AI に貼り付ける前に確認すること ── 個人情報・守秘義務・社内規程の 3 ライン
目次
- 1. AI への入力が「問題になる」とはどういうことか
- 2. ライン 1:個人情報 ── 名前・住所・連絡先は原則 NG
- 「個人情報」の法的な定義
- 「個人関連情報」にも注意が必要
- 2026 年 4 月の法改正:違反への制裁が強化された
- 3. ライン 2:守秘義務の対象情報 ── 社外秘・顧客情報・契約内容
- 守秘義務には 2 種類ある
- 「秘密管理性」が失われるリスク
- 4. ライン 3:社内規程と利用規約 ── 使う前に確認すべき 2 枚の紙
- 2 つのルールが同時に存在する
- 確認の手順
- 5. 入力前のセルフチェック ── 迷ったら「公開できるか」で決める
- 迷ったときの 1 つの問い
- 入力前のチェックリスト
- 匿名化・抽象化して入力する
- 6. ツール側でできる対策 ── 学習オフ・プロジェクト機能・API 利用の違い
- 設定はリスクを下げるが、ゼロにはしない
- 主要 3 サービスの学習ポリシー(2026 年 5 月時点)
- 3 サービスの比較(2026 年 5 月時点)
- API 利用の場合
- 7. 入力 vs 出力 ── 著作権との違いをひとことで
- 8. まとめ:今日から使える 3 つのライン
- 次に読む
- 出典・参考文献
注意:この記事は情報提供を目的としており、法的アドバイスではありません。個別の法的判断については弁護士等の専門家に相談してください。記事内の法律・規約情報は 2026 年 5 月時点 のものです。
AI 活用の研修をしていると、使い始めてから出てくる質問があります。
「業務の内容を ChatGPT に貼り付けて使っているんですが、それって大丈夫なんですか?」
これは使い方の質問ではありません。「自分は今、何か悪いことをしているんじゃないか」という不安です。AI を使い始めると、出力の品質よりも先に、この感覚がじわじわやってきます。「入力してよかったのか」という後ろめたさが残ります。
この記事はその不安に正面から答えます。「入れてはいけないもの」と「入れても問題ないもの」の境目を、個人情報・守秘義務・社内規程の 3 本のライン で整理します。
1. AI への入力が「問題になる」とはどういうことか
「入力が問題になる」とはどういう状態でしょうか。2 つの問いに分けると分かりやすくなります。
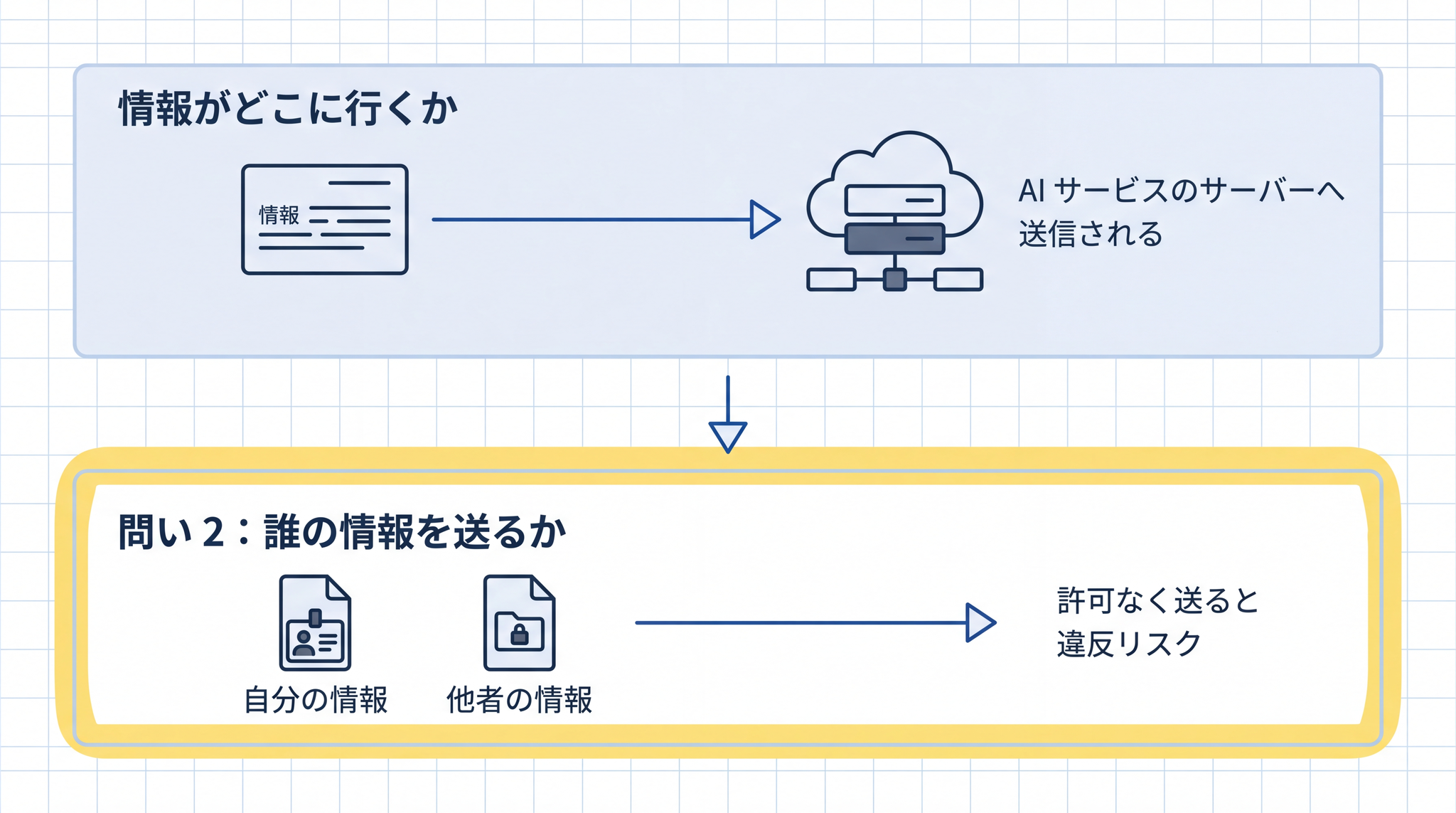
第一の問い「情報がどこに行くか」。 クラウド型の AI サービスに文章を貼り付けると、そのデータは外部のサーバーに送信されます。場合によってはモデルの学習データに使われます。「AI に入力する = AI サービス会社にデータを送る」と考えると、状況がはっきりします。
第二の問い「誰の情報を、誰の許可なく送っているか」。 自分のことだけを入力するなら、自分の判断で送れます。しかし他者の個人情報や、会社が「秘密」として管理している情報が混ざっている場合、その管理者(本人・会社)の許可なく外部に渡すことになります。この 2 つが重なったとき、個人情報保護法違反・守秘義務違反・社内規程違反 が問題になります。
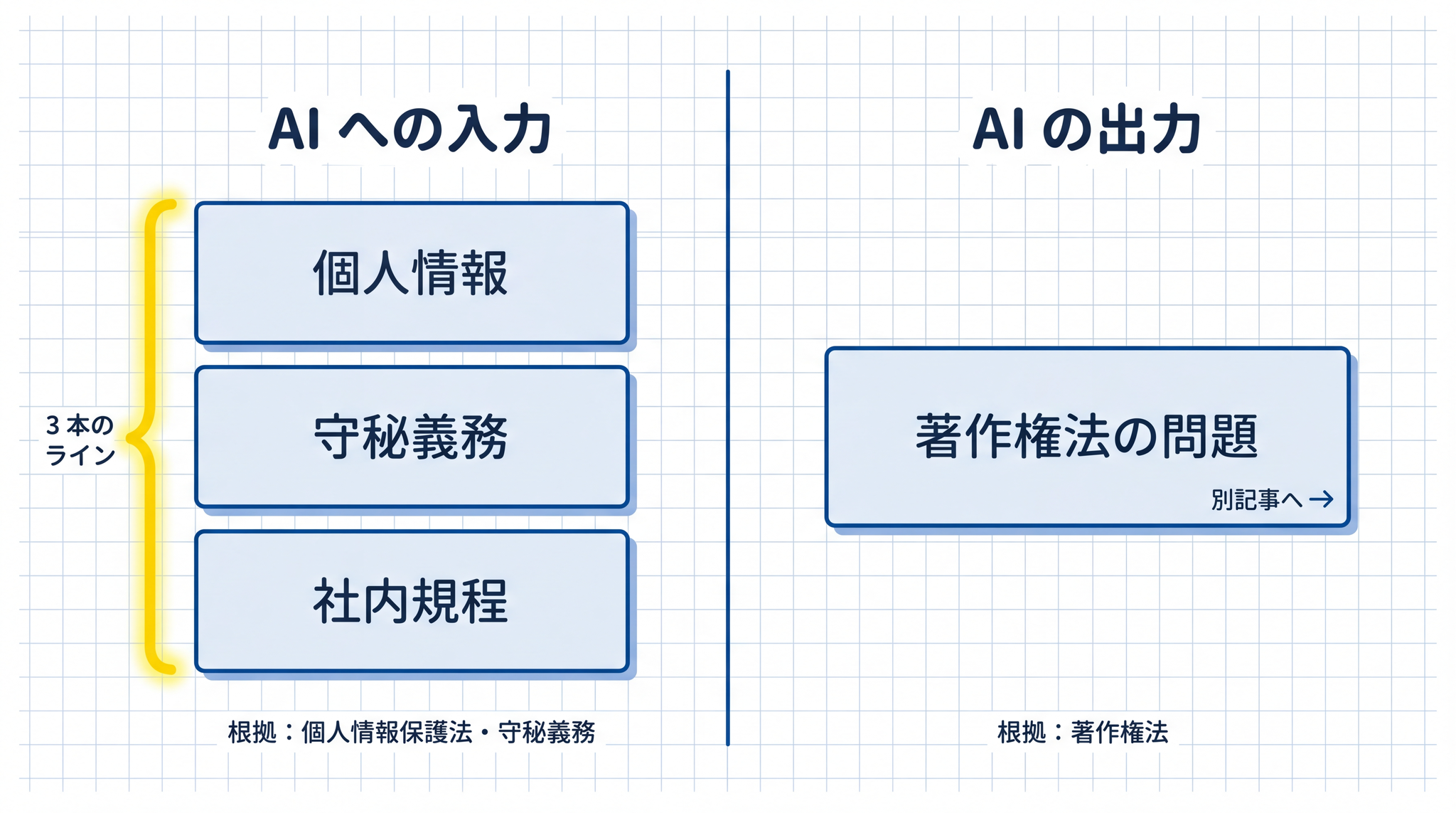
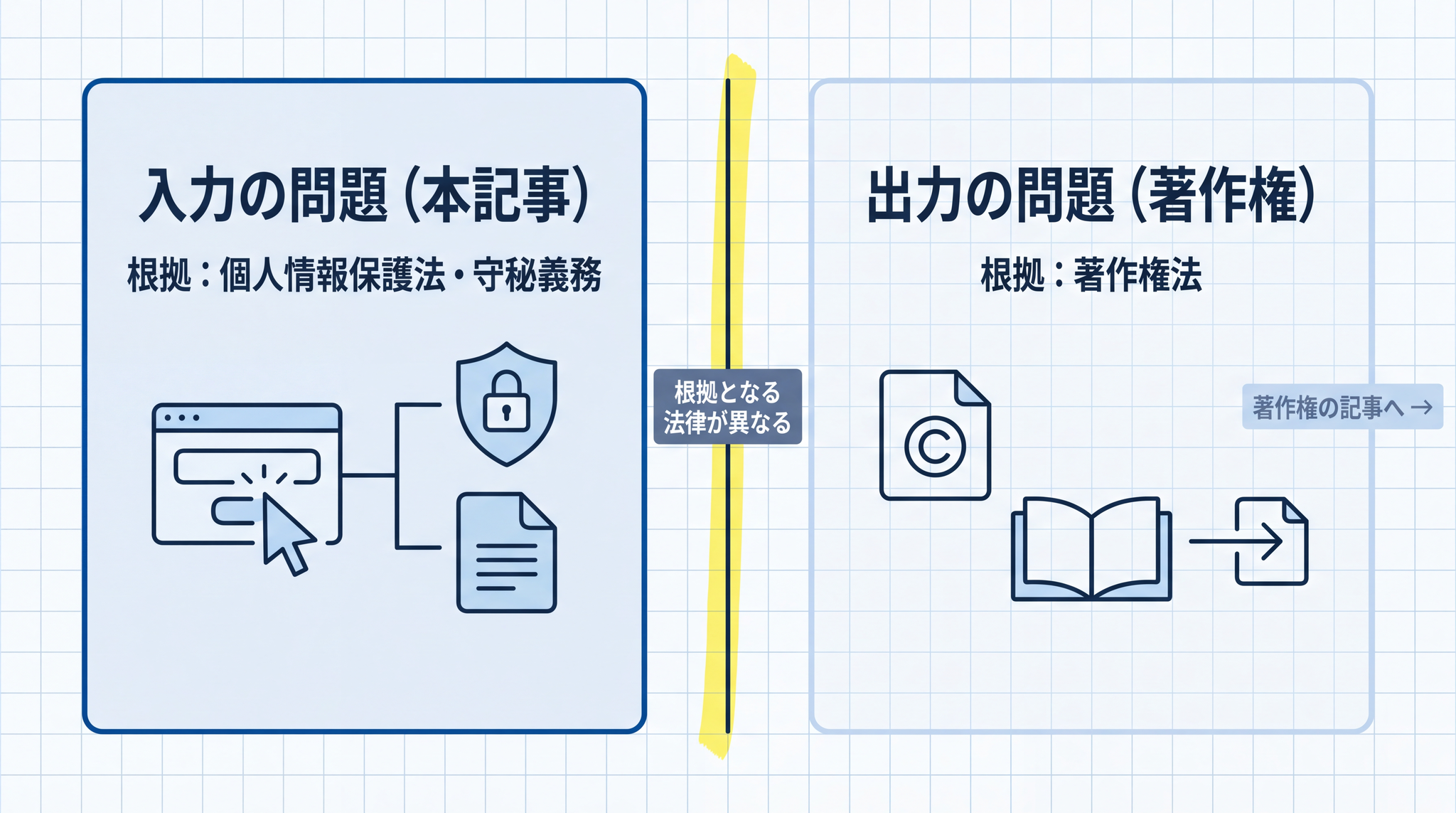
本記事が扱うのは AI への入力(プロンプト)の安全性です。AI が生成した出力(画像・文章)の著作権は、また別の話です。「AI と著作権 ── 「使っていい?」に答える 3 つの問い」は著作権法を根拠とする出力の問題を扱います。入力と出力は根拠になる法律が別で、混同すると正しく判断できなくなります。
2. ライン 1:個人情報 ── 名前・住所・連絡先は原則 NG
「個人情報」の法的な定義
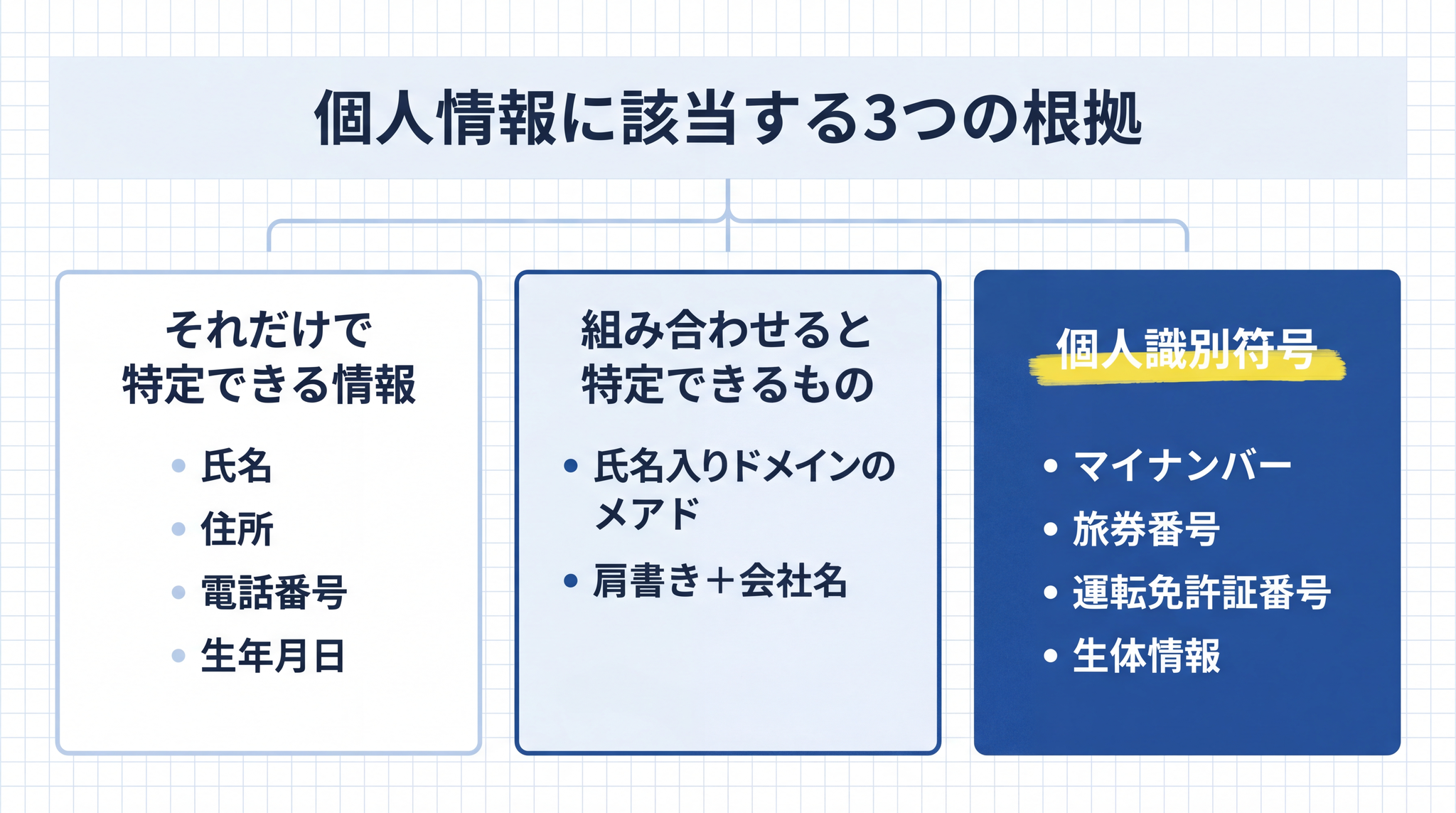
個人情報保護法では、「個人情報」を「生存する個人に関する情報で、氏名・生年月日などの記述によって特定の個人を識別できるもの(他の情報と照合することで識別できるものを含みます)、または個人識別符号を含むもの」と定義しています1。
具体的に個人情報に当たるものは次の通りです2。
- それだけで特定できるもの:氏名、住所、生年月日、電話番号
- 組み合わせると特定できるもの:個人のメールアドレス(氏名入りの企業ドメインなど)、「A 社の営業部長」のような肩書きと会社名の組み合わせ
- 個人識別符号:マイナンバー、旅券番号、運転免許証番号、指紋・顔認識データなどの生体情報
会社名だけ では個人情報に該当しません。でも「○○株式会社 田中課長」のように氏名と組み合わさると、特定の個人を指してしまうので個人情報として扱う必要があります。
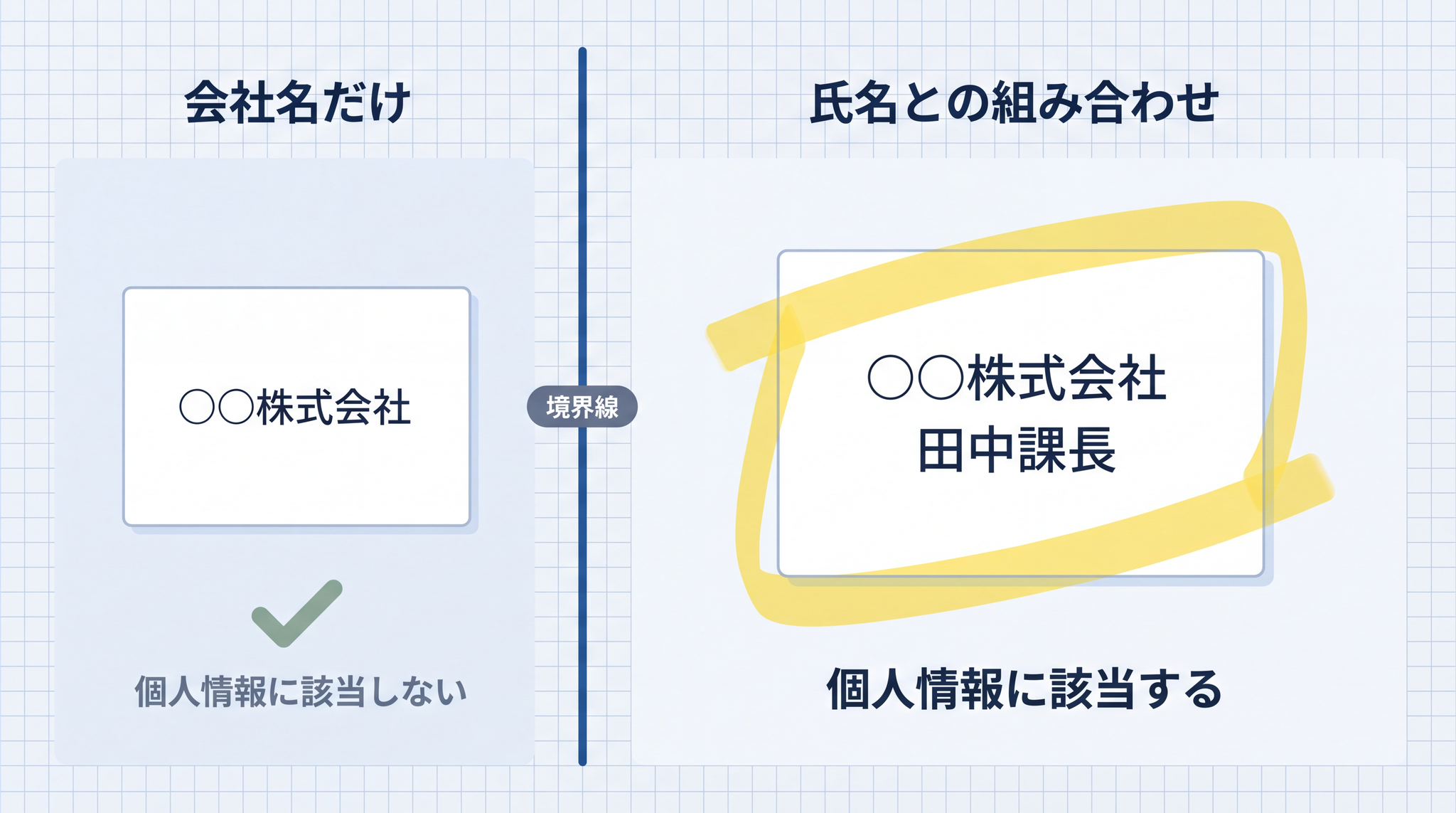
「個人関連情報」にも注意が必要
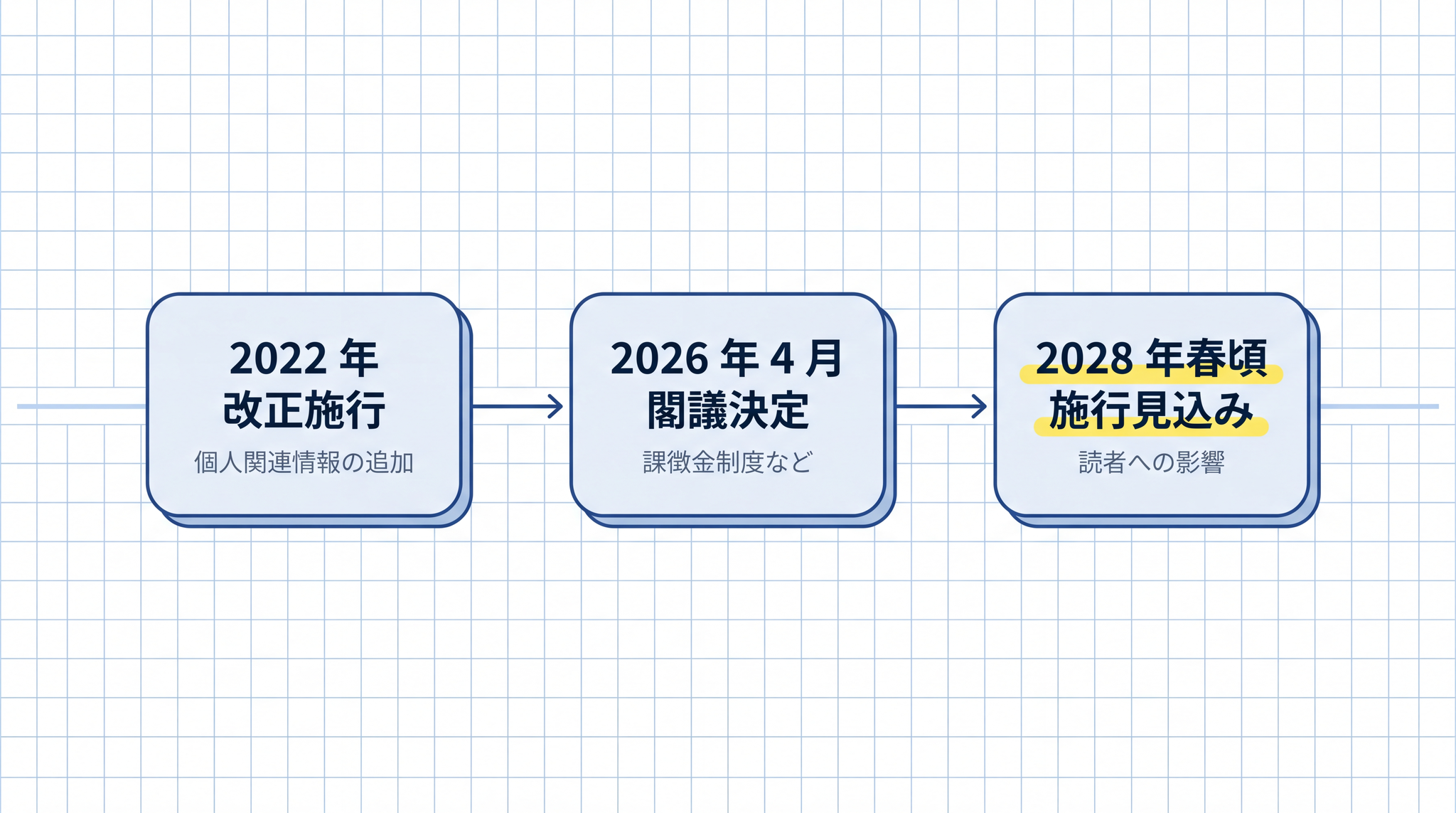
2022 年の改正で個人情報保護法第 2 条第 7 項に「個人関連情報」という概念が加わりました3。それだけでは誰のものか分かりませんが、他のデータと組み合わせると特定できてしまいうる情報のことです。Cookie(サイトがブラウザに残す識別タグ)・IP アドレス(接続元を示す番号)・位置情報の履歴などが典型例です。
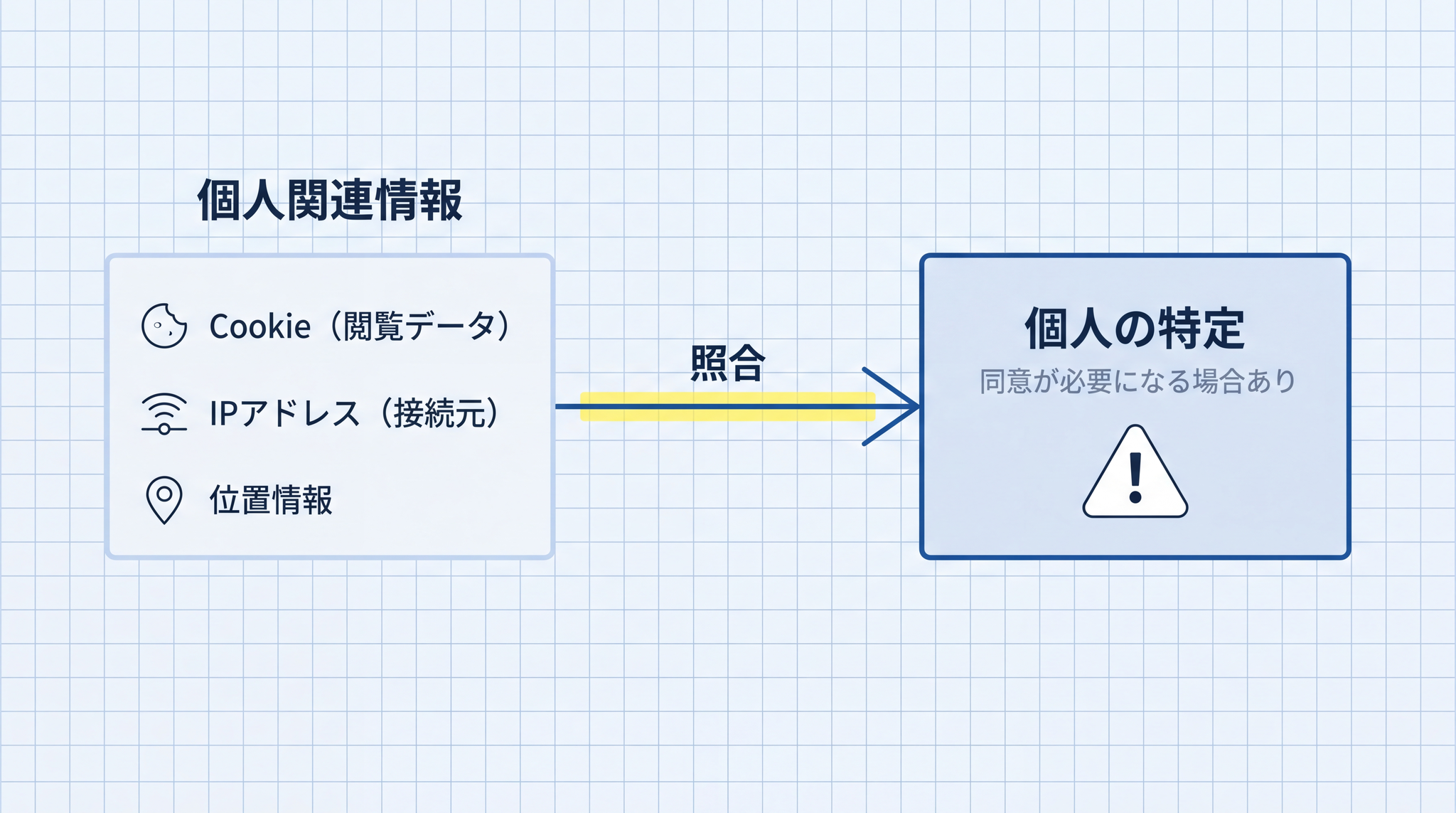
AI サービス会社がそのデータを自社の情報と照合して個人を特定できる場合、事前に本人の同意が必要になります(同法第 31 条)。システムのエラーログやアクセス解析のデータをそのまま貼り付けると、この規定に引っかかる可能性があります。
2026 年 4 月の法改正:違反への制裁が強化された
2026 年 4 月 7 日、個人情報保護法等の一部改正案が閣議決定され、国会に提出されました45。
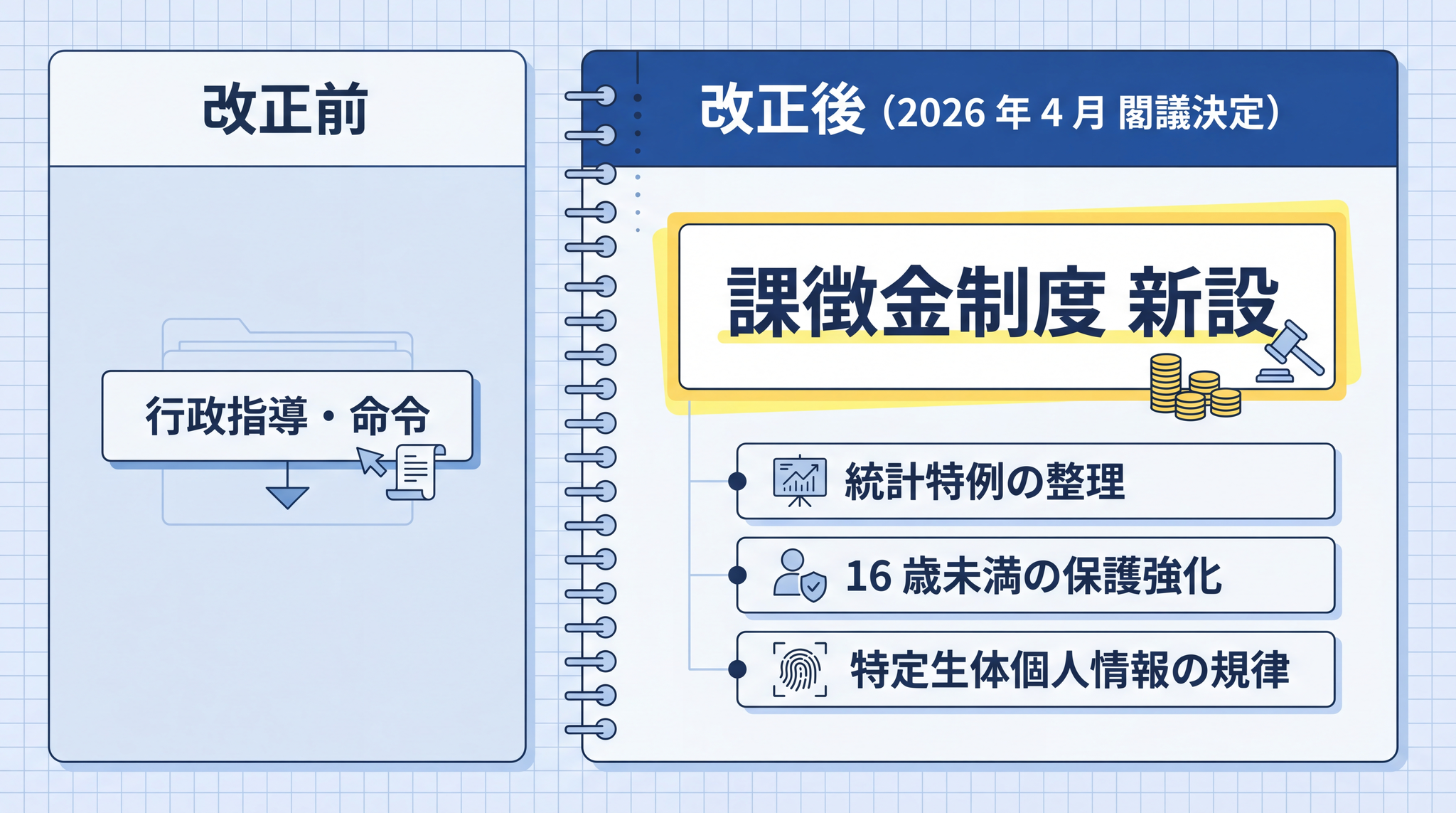
最も大きな変化は 課徴金制度の新設 です。違法に個人情報を第三者に渡した場合、「違反行為により得た財産的利益等に相当する額」を金銭的制裁として課す制度が加わります。これまでは行政指導・命令が主な対応手段でしたが、金銭的なペナルティが直接かかるようになります。
ほかにも、統計作成等を目的とした第三者提供の本人同意不要例外の整理・16 歳未満の個人情報について法定代理人(保護者等)を対象とすることの明文化・顔認証データなどを「特定生体個人情報」として規律強化する改正が含まれます。
施行は公布日から 2 年以内の予定で、2028 年春頃が見込みです。
3. ライン 2:守秘義務の対象情報 ── 社外秘・顧客情報・契約内容
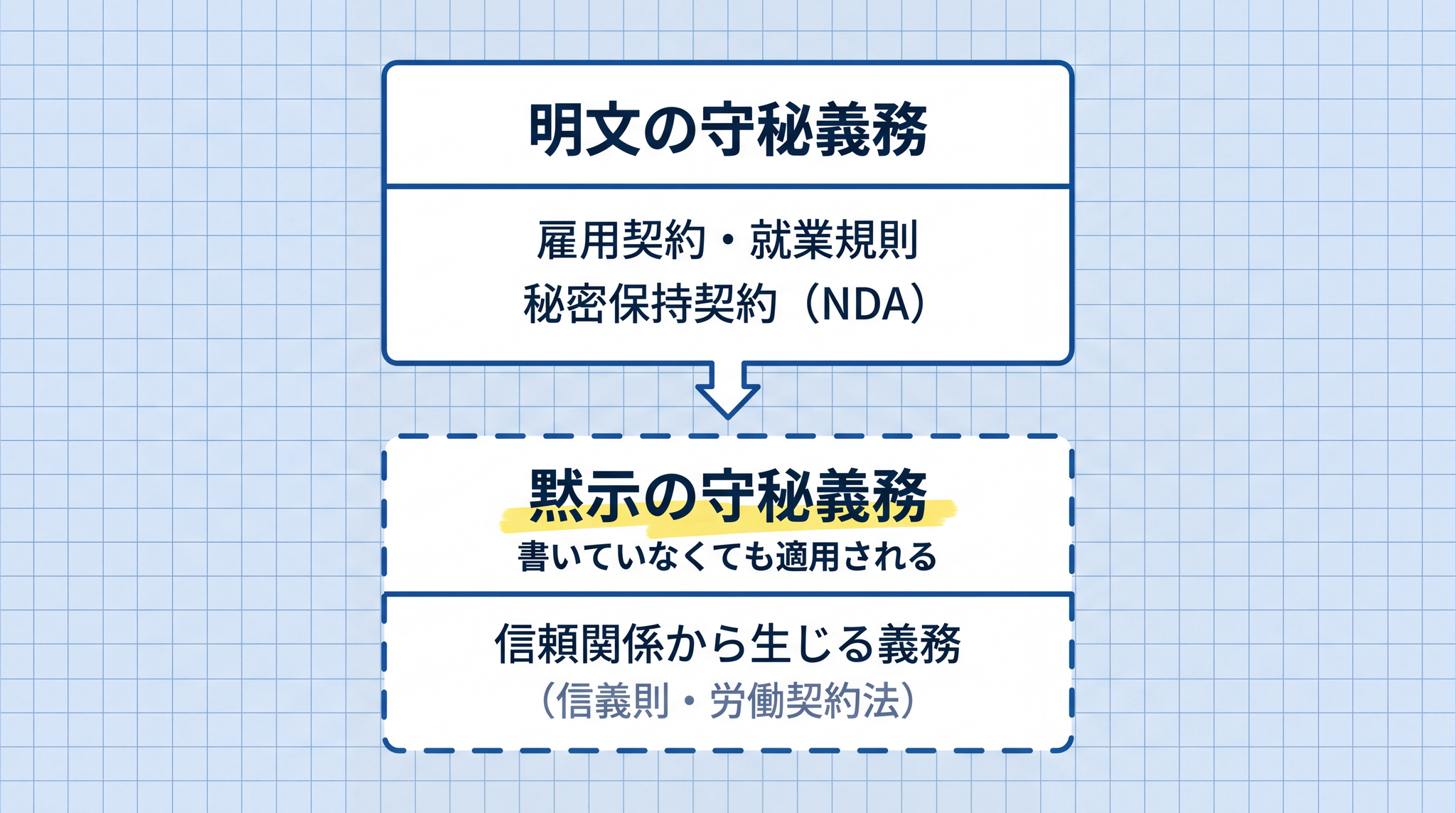
守秘義務には 2 種類ある
「守秘義務」には、2 種類の根拠があります。
明文で書いてある守秘義務:雇用契約や就業規則に「秘密保持条項」が明記されている場合や、「この情報は外に出しません」と約束する書面(秘密保持契約)を個別に結んでいる場合です。
書いていなくても生じる守秘義務:就業規則に一言も書いていなくても、働いている人は守秘義務を負います。労働契約法第 3 条第 4 項の「信義則」(信頼関係に基づいて誠実に行動する義務)の付随義務として、業務上知った秘密を守ることは法律上認められています6。
「会社のルールブックに AI 使用禁止と書いていなかったから問題ない」という判断は、法的に成り立ちません。書いていなくても守秘義務はある、というのがポイントです。
たとえていうなら、新入社員が入社初日に「他社に機密を漏らしてはいけない」と明示されなくても、それが当然の行動として求められるのと同じことです。
「秘密管理性」が失われるリスク
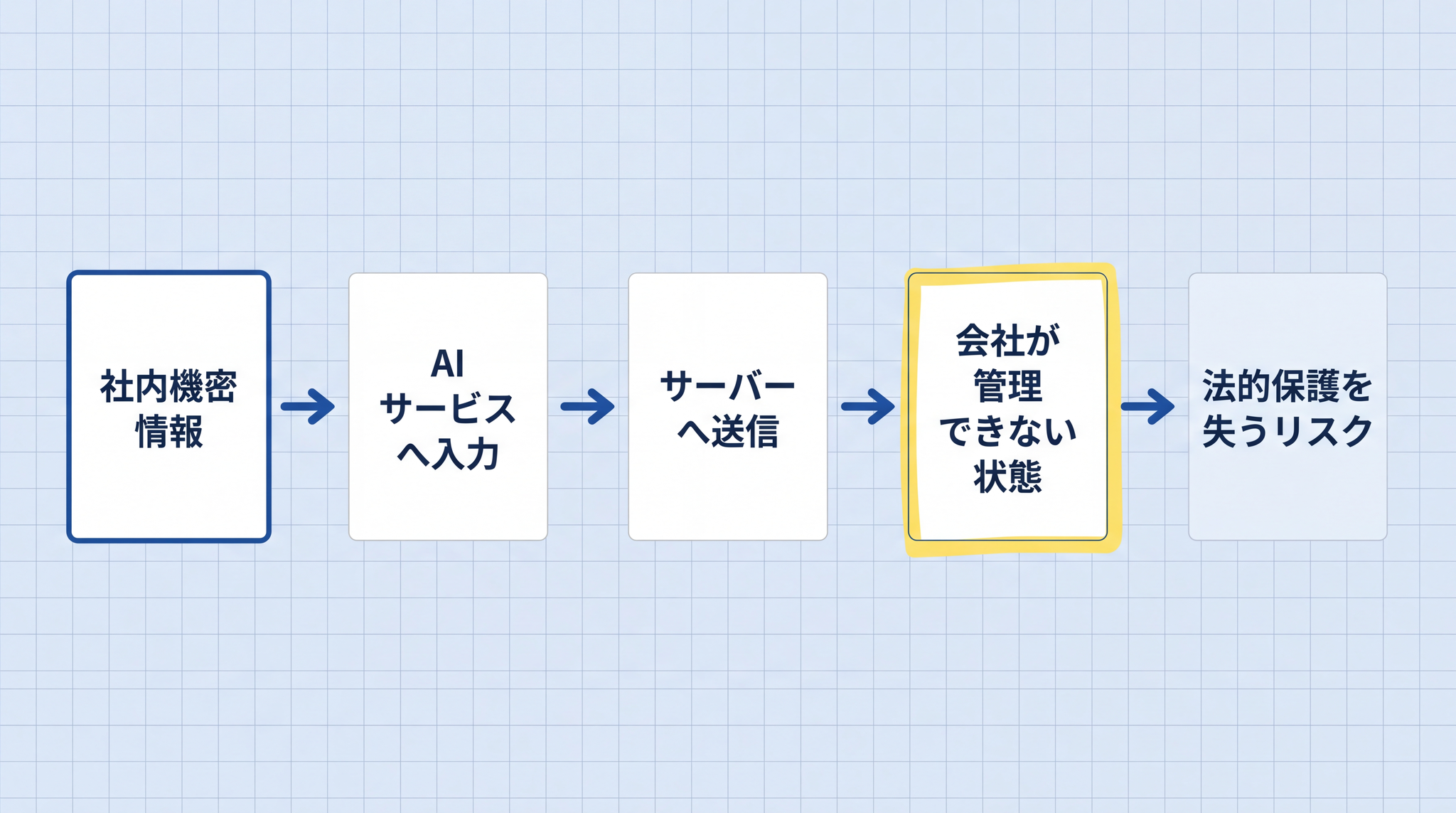
会社が持つ重要なノウハウや顧客リストは、法律(不正競争防止法)上の「営業秘密」として保護される場合があります。保護が成り立つ条件はいくつかありますが、AI への入力で直接問題になるのは 「会社がちゃんと秘密として管理しているかどうか」 という点だけです。

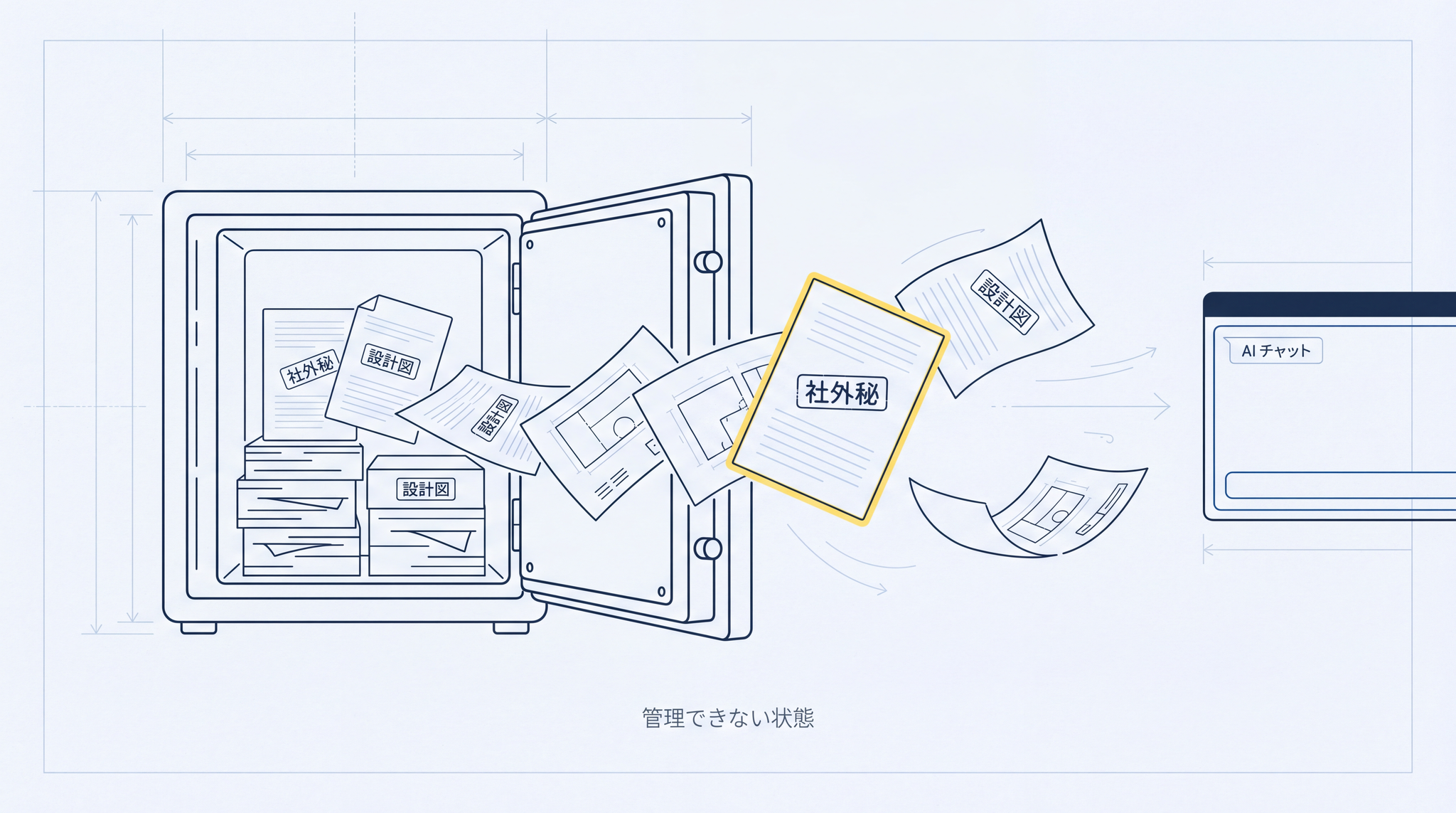
従業員が個人向けの AI サービス(誰でも使えるコンシューマープラン)に自社の機密技術データを入力すると、その情報は AI サービス会社のサーバーに送られ、会社が管理できない状態に置かれます。もし「秘密管理性が失われた」と裁判所が判断した場合、競合他社が不正にその技術を手に入れても、差し止めや損害賠償を求める法的な根拠がなくなってしまいます。
これは仮定の話ではありません。2023 年春、大手半導体・電子機器メーカー(韓国のサムスン電子)でエンジニアが ChatGPT のコンシューマー版に機密ソースコードや会議の議事録を入力する事案が複数発生しました。同社はその後すぐ、社内デバイスからの AI サービスへのアクセスを全面禁止しました。
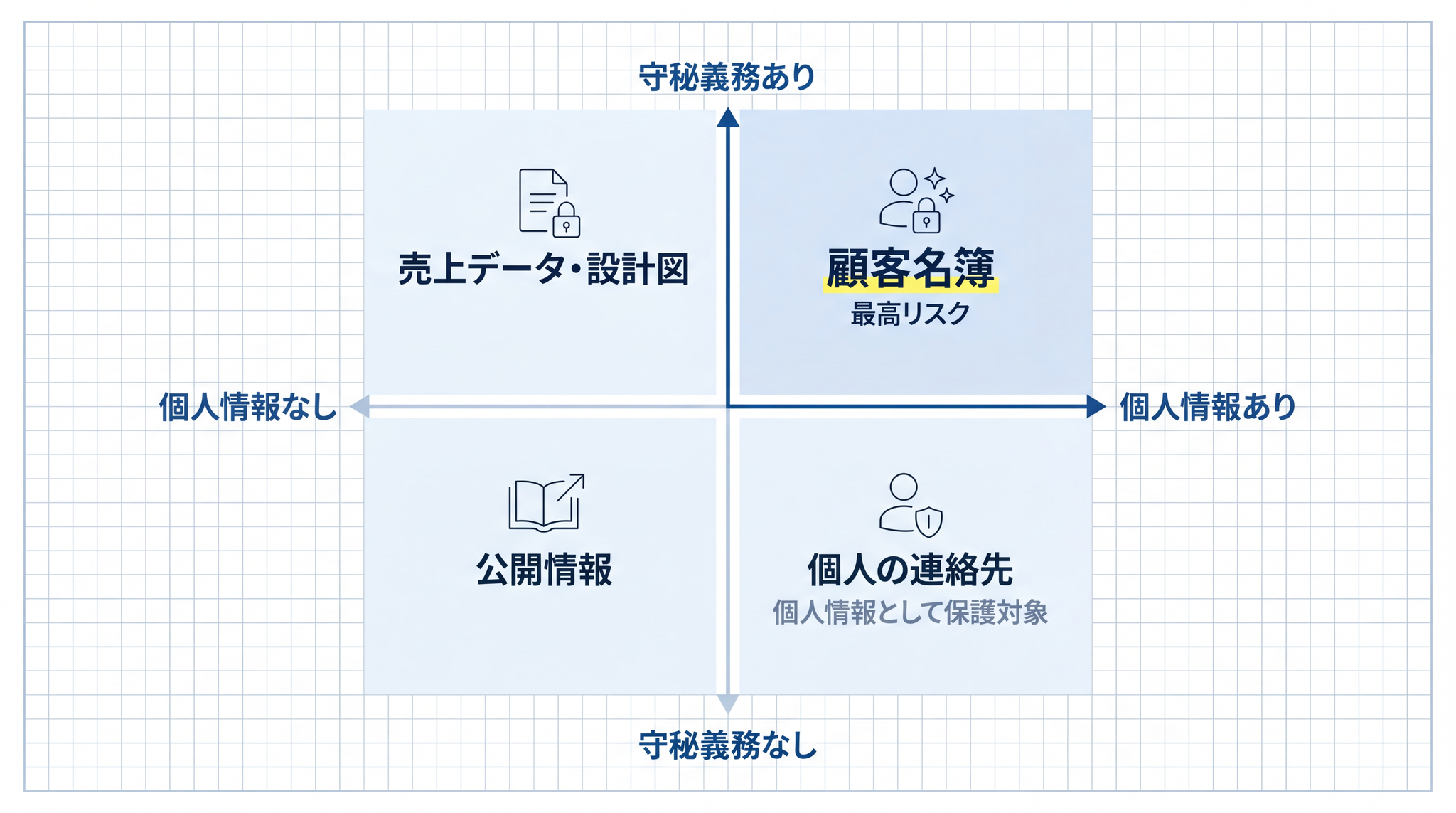
守秘義務の対象になりやすい情報の典型例としては、顧客名簿・取引履歴・契約内容、売上データ・未公開の事業計画、設計図・ソースコード・製造プロセス、給与・人事評価、他社との NDA(秘密保持契約)の条件などが挙げられます。
4. ライン 3:社内規程と利用規約 ── 使う前に確認すべき 2 枚の紙
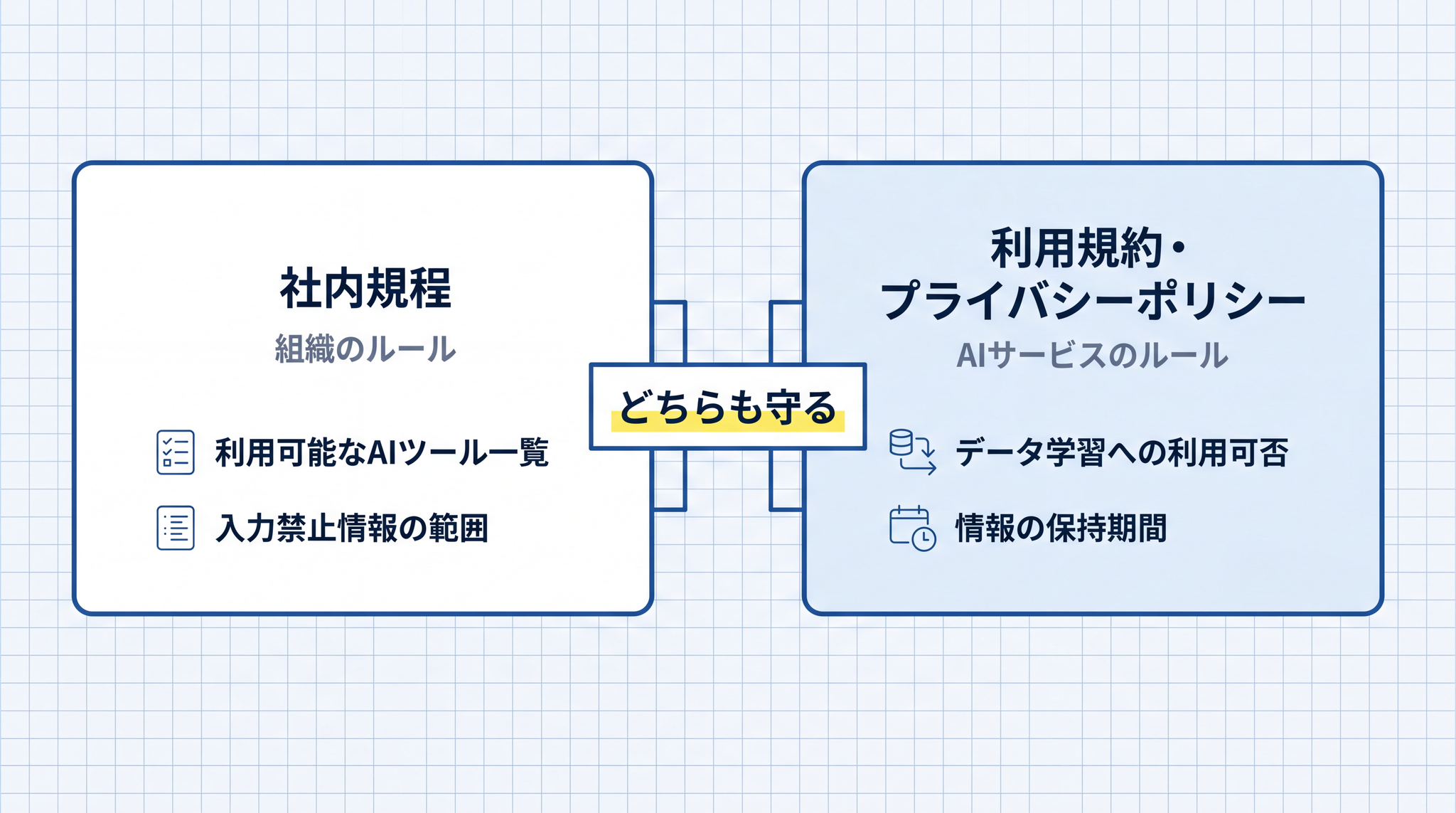
2 つのルールが同時に存在する
AI ツールを使うとき、守るべきルールは 2 層に分かれます。
社内規程(自分が属する組織のルール):組織が独自に定めた AI 利用のルールです。「業務情報の AI 入力を禁止する」「使用できるサービスを指定する」「上長の承認が必要」といった内容が含まれる場合があります。組織に規程がない場合でも、守秘義務(§3)は黙示の義務として適用されます。
利用規約・プライバシーポリシー(AI サービスのルール):AI サービス会社が定めたルールです。入力データをモデルの学習に使うかどうか、データの保持期間、法人向けと個人向けの違いなどが書かれています。
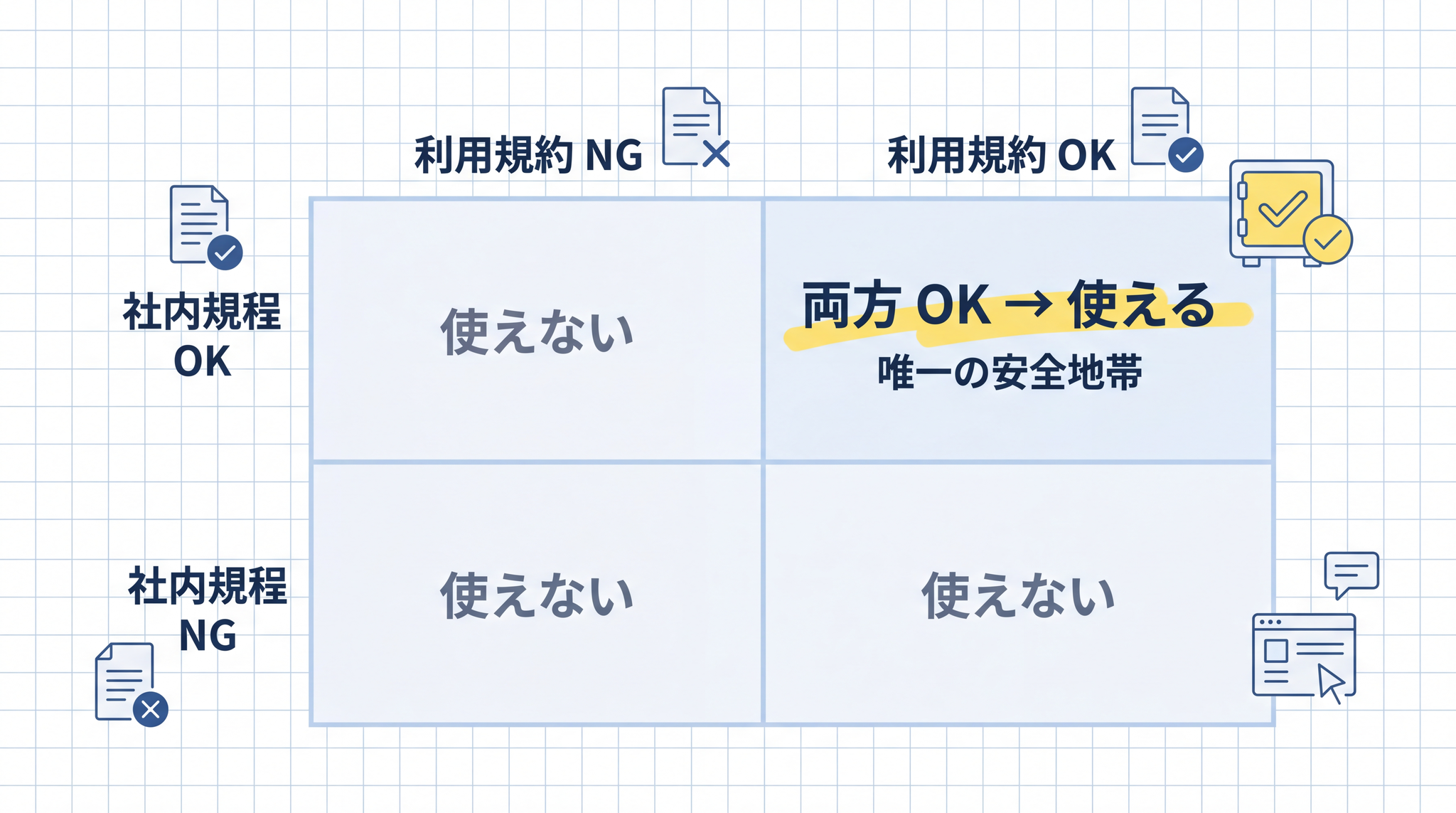
この 2 層は「どちらが優先か」ではなく、「両方を守る」という関係です。組織のルールで「使ってよい」とされていても、利用規約の範囲を超えることはできません。逆に、利用規約上は問題ない行為でも組織のルールで禁じられていれば従う必要があります。
確認の手順
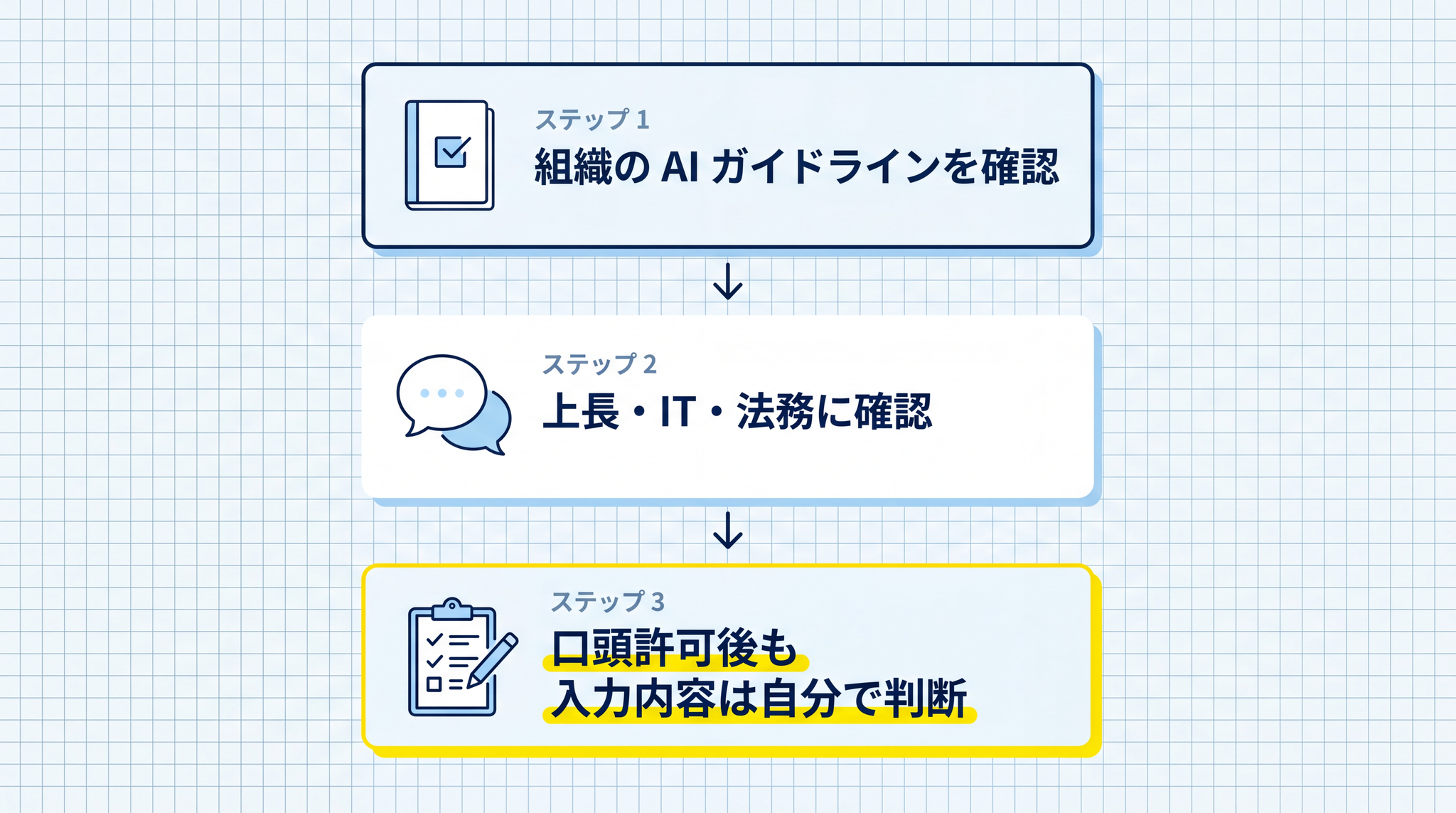
人事部門や IT 部門が AI 利用ガイドラインを出している場合はそこを参照します。規程がない場合や分からない場合は、使う前に所属組織の責任者や IT・法務の担当者に確認します。「AI ツールの使用について、入力内容の判断基準はありますか」のような形で聞くと、相手も答えやすくなります。
「使っていい」と口頭で言われても、何を入力するかは自分で判断する必要があります。口頭の許可はあくまで「そのサービスを使ってよい」という意味で、入力内容の安全性まで保証するものではありません。個人情報(§2)と守秘義務(§3)の判断はその後に自分で行います。
5. 入力前のセルフチェック ── 迷ったら「公開できるか」で決める
迷ったときの 1 つの問い
研修でよく使う判断軸があります。
「この情報を、インターネット上に自分の名前で公開できるか?」
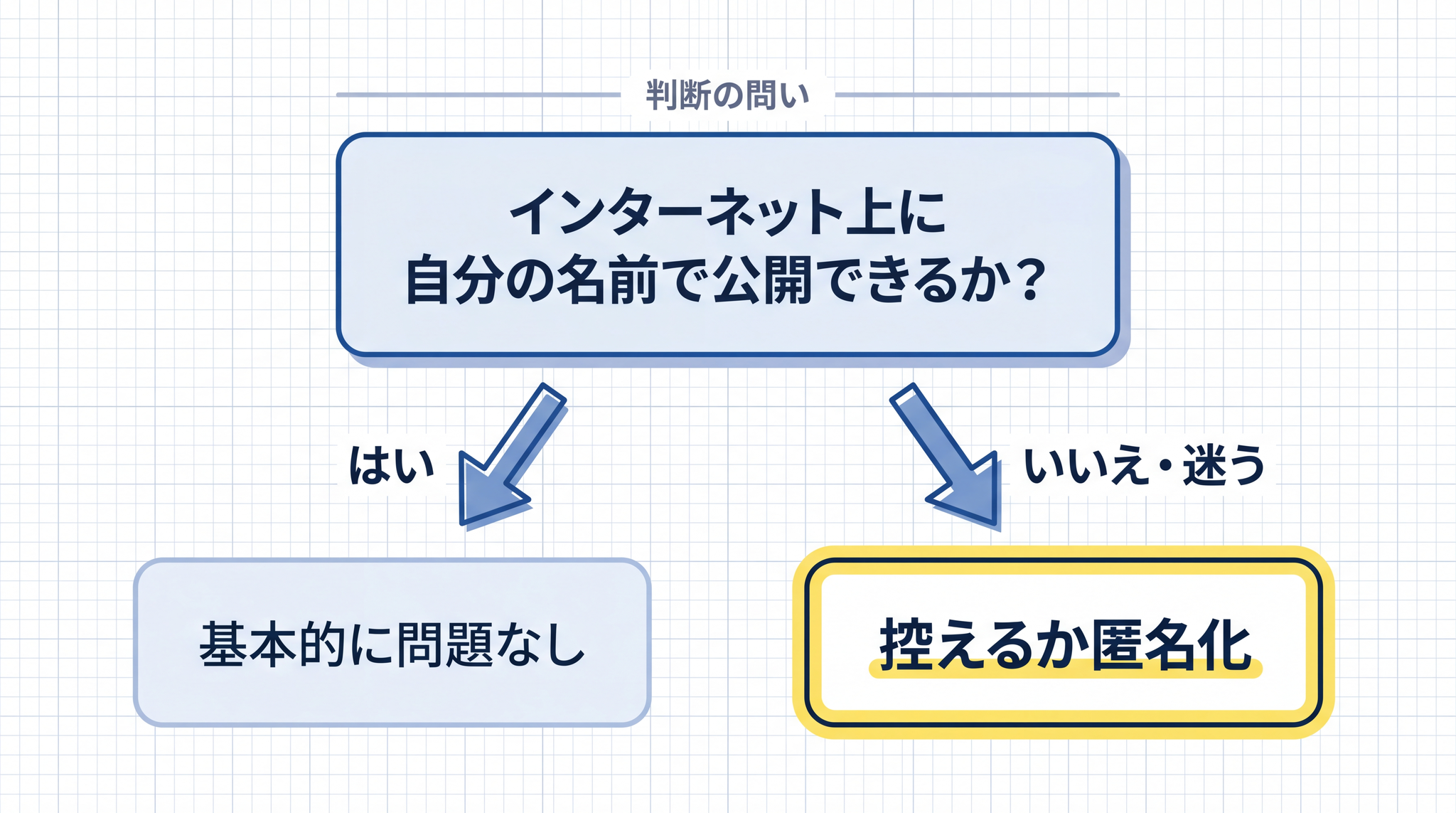
「はい」と答えられる情報は、基本的に AI に入力しても問題になりにくいです。「いいえ」と感じる情報、または迷う情報は、入力を控えるか、加工・匿名化してから使います。
「公開できない」という感覚は、守秘義務や個人情報保護の実質的な根拠と重なることが多いです。法律の条文を覚えなくても、公開できるかという感覚でリスクの境目を捉えられます。
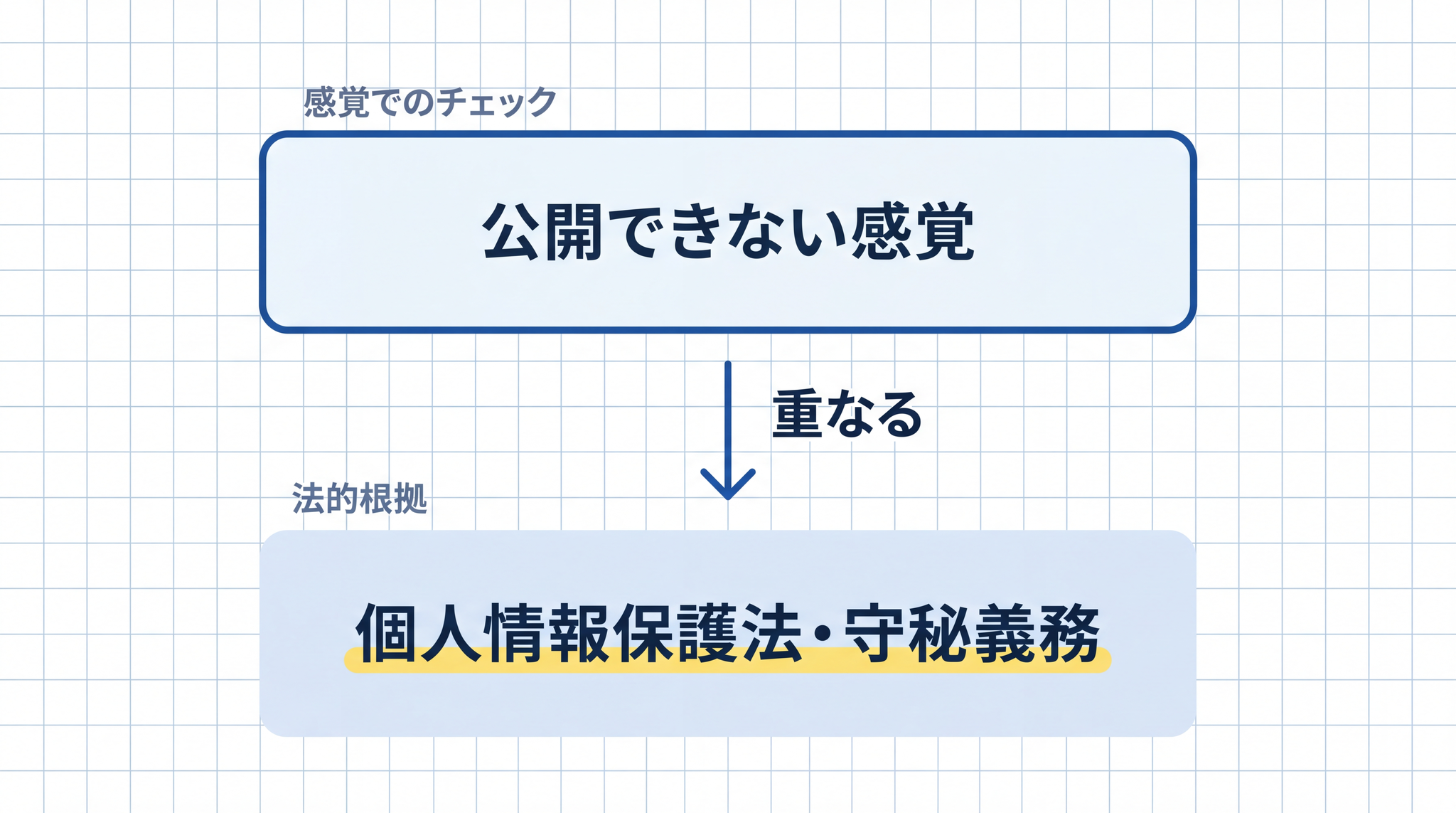
ただし、これはあくまで一次的な自己チェックの軸です。法的な判断の代わりにはなりません。組織の規程や個別の事案については、専門家への確認を優先してください。
入力前のチェックリスト

- 他者の氏名・住所・電話番号・メールアドレスが含まれる → 個人情報。匿名化を検討
- 顧客情報・取引情報・契約内容が含まれる → 守秘義務の対象の可能性。組織の担当者に確認
- 「社外秘」「マル秘」などの表示がある → 入力しない
- 組織に AI 利用ガイドラインがある → その範囲内かを確認
- 個人向けプランを使っている → 学習設定の確認が必要(§6 参照)
匿名化・抽象化して入力する
守秘義務の対象を含む情報でも、加工してから入力すれば AI の力を借りられる場合があります。
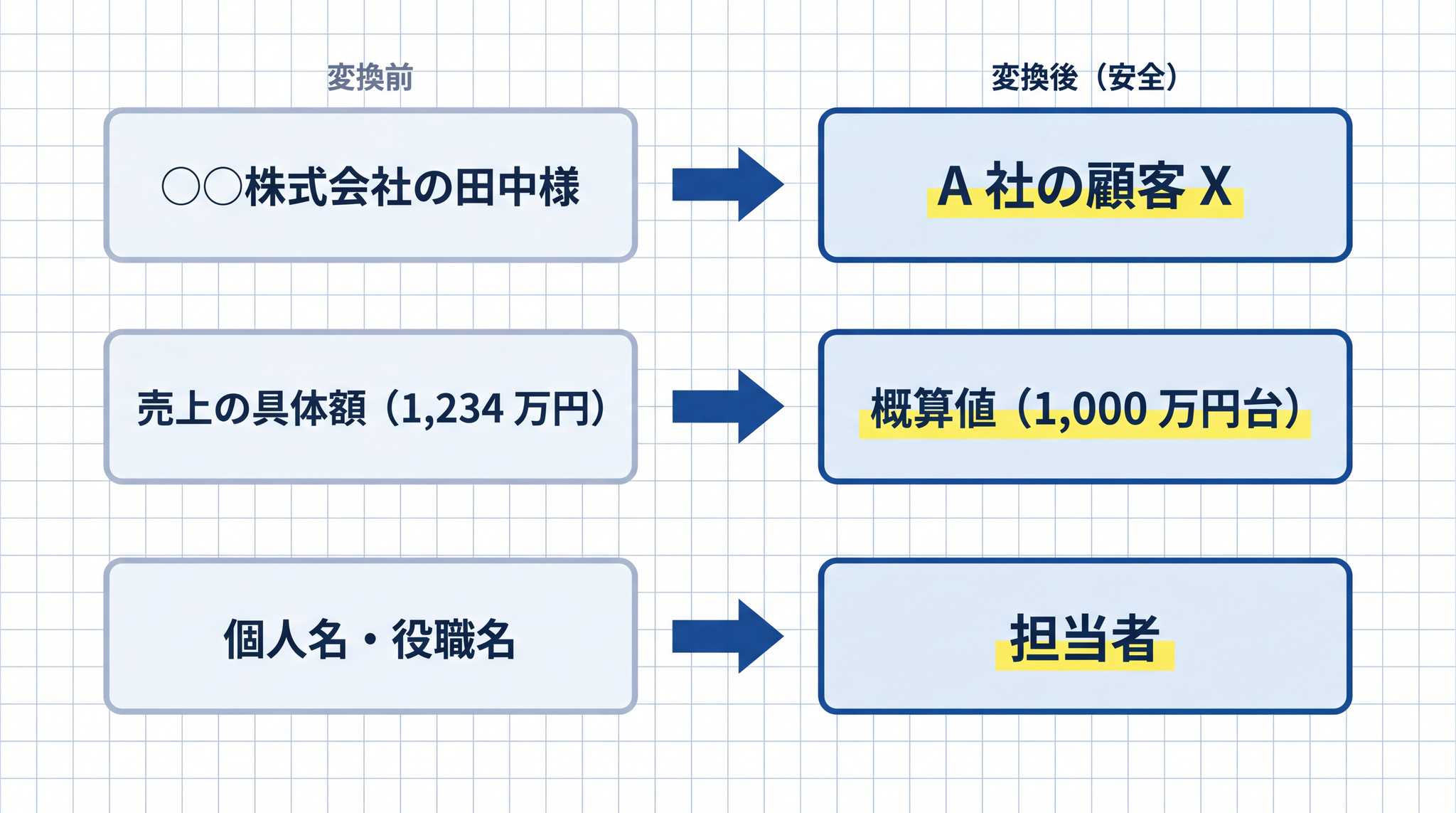
- 「○○株式会社の田中様」→「A 社の顧客 X」
- 売上の具体額 → 概算値
- 個人名・役職名 → 「担当者」
単純な置換では足りないケース
名前や会社名を置き換えただけでは、「他の情報と組み合わせると特定できる」状態が残ることがあります。
たとえば「A 社の顧客 X」と書いても、業種・地域・規模・取引時期・担当者の役職がそのまま残っていれば、社内の事情を知る人や関係者には誰のことか分かってしまいます。個人情報保護法では、他の情報と組み合わせると特定できてしまう場合も保護の対象になります(§2 で紹介した「組み合わせると特定できる情報」の考え方)。置換した後も、周辺情報を一段抽象化することが必要です。
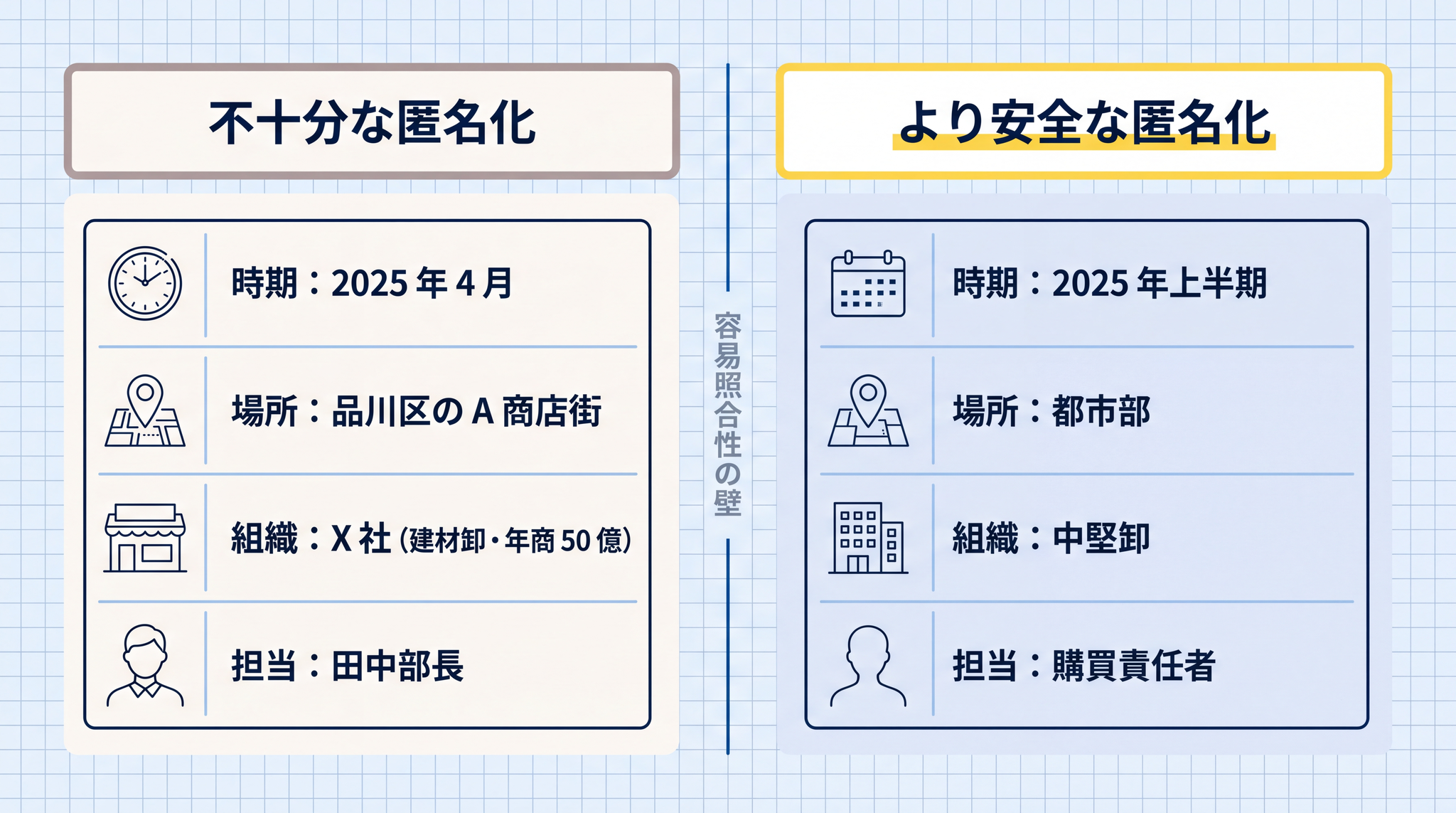
対比すると、次のような差があります。
- 不十分:「2025 年 4 月、品川区の A 商店街、X 社(建材卸・年商 50 億)の田中部長」
- より安全:「2025 年上半期、都市部の中堅卸、購買責任者」
業種・地域・規模・時期の粒度を落とすと、組み合わせによる特定が難しくなります。
「金額を伏せると分析できない」というトレードオフ
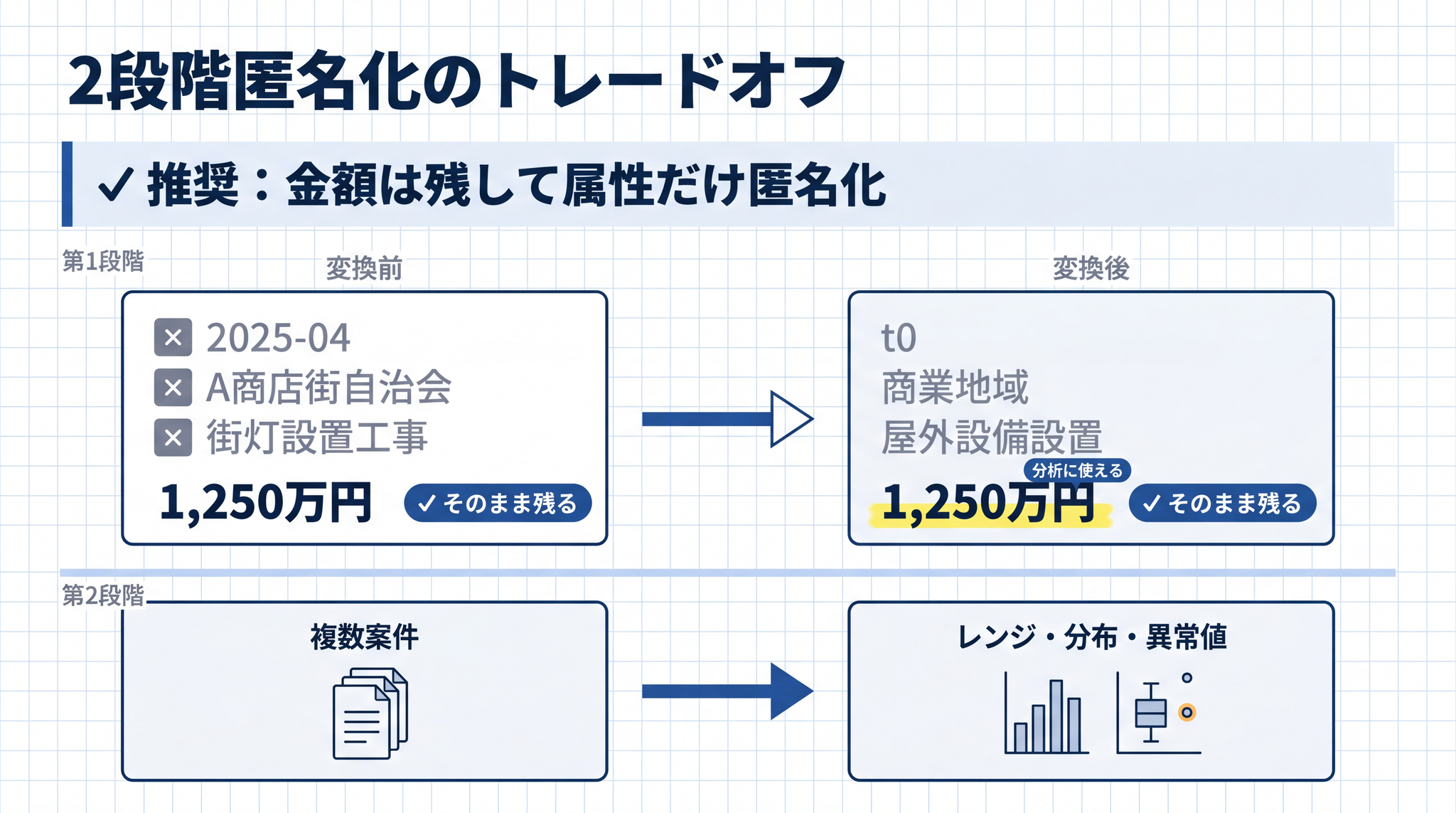
実務でよく問われるのが、「金額そのものを伏せたら AI に分析させる意味がなくなるが、どこまで伏せればよいか」という問いです。金額の分析価値を保ちながら、特定リスクを下げる方法は 2 段階あります。
「誰の・いつの・どの案件か」を匿名化して、金額は残すのが最も実用的です。たとえば「2025-04 / A 商店街自治会 / 街灯設置工事 / 1,250 万円」という情報を AI に渡す場合、「t0 / 商業地域 / 屋外設備設置 / 1,250 万円」のように属性を抽象化します。金額のレンジや分布、異常値の分析は引き続きできますが、個別案件の特定は難しくなります。
完全な匿名化が難しい場合は、法人向けプランへの切り替え(§6 参照)か、AI への入力自体を取りやめる判断が安全です。
6. ツール側でできる対策 ── 学習オフ・プロジェクト機能・API 利用の違い
設定はリスクを下げるが、ゼロにはしない
ツールの学習設定をオフにすれば、入力データがモデルのトレーニングに使われるリスクは下げられます。ただし「設定したから何でも入れていい」ではありません。個人情報保護法と守秘義務は、学習設定のオン・オフにかかわらず適用されます。
設定変更は補完的な対策です。3 本のラインを守ることが先で、設定はその後の話になります。

主要 3 サービスの学習ポリシー(2026 年 5 月時点)
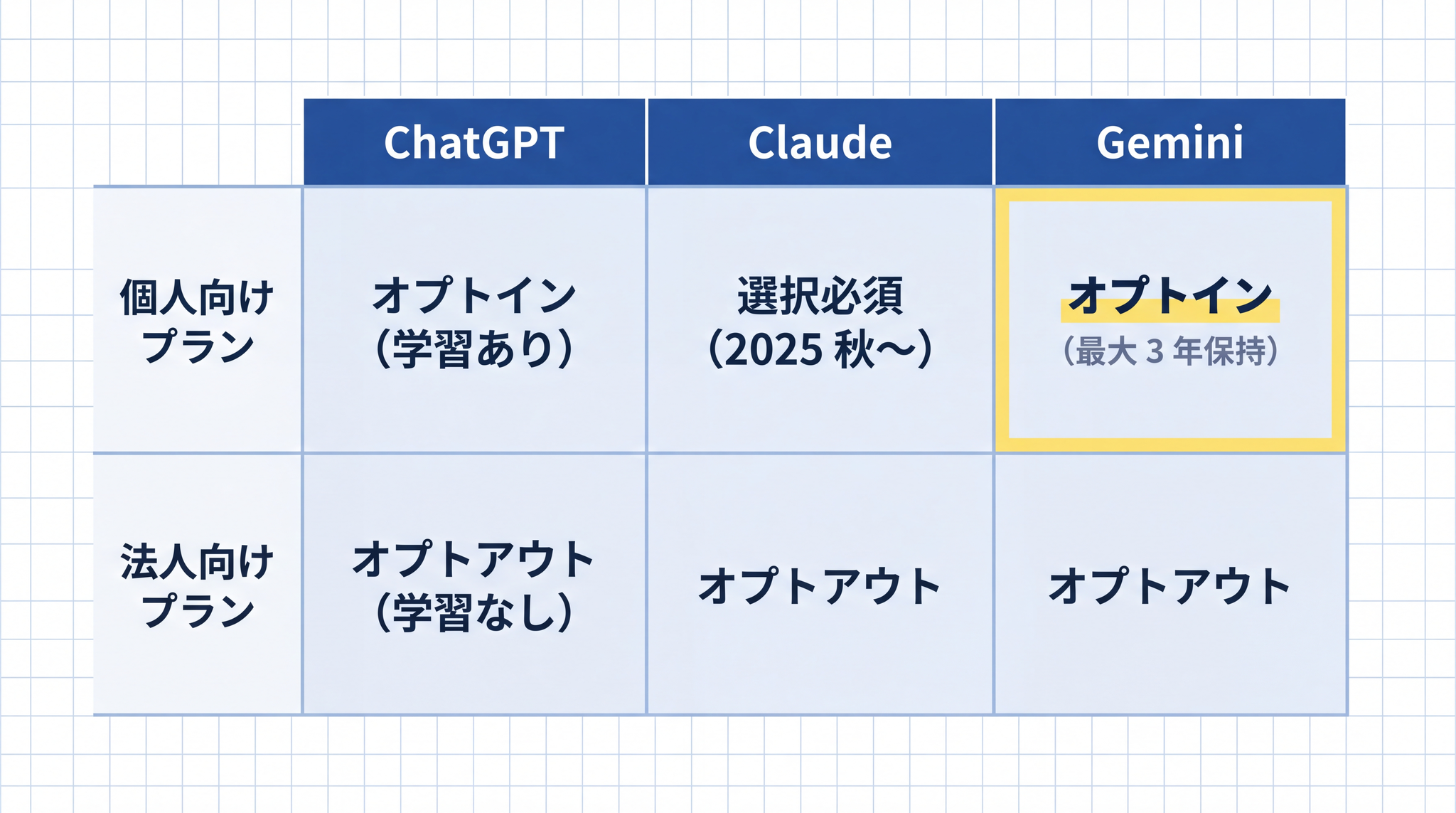
個人向けプラン(Free / Plus / Pro)はデフォルトで学習に使う設定(オプトイン)です。設定 → Data controls →「Improve the model for everyone」をオフにすることでオプトアウトできます。学習をオフにしても、不正利用監視のために最長 30 日間データを保持します。法人向けプラン(Enterprise / Teams)はデフォルトで学習に使わない設定(オプトアウト)です。
2025 年秋にコンシューマー版(Free / Pro / Max)の規約が改訂され、学習利用を許可するかどうかをユーザーが必ず選択する必要となりました(事実上のオプトイン)。以前は「絶対に学習しない」というポリシーでしたが、現在は変わっています。設定 → Privacy →「Help improve Claude」のトグルで選びます。学習を許可した場合は最長 5 年間、許可しない場合は最長 30 日間データを保持します。法人向けプラン(Claude for Work / API)はデフォルトで学習に使いません。
Gemini(Google)11
個人向けプラン(コンシューマー版)はデフォルトでアクティビティが Google のサービス改善に使われます(オプトイン)。注意すべき点は、人間のレビュアーが会話を確認するプロセスがあることです。一度レビュー対象となった会話データは、アカウントから削除しても切り離されて 最大 3 年間保持されます。オプトアウトは myactivity.google.com/product/gemini から「Gemini アプリのアクティビティ」をオフにします。法人向けプラン(Google Workspace)はトレーニングに使われません。
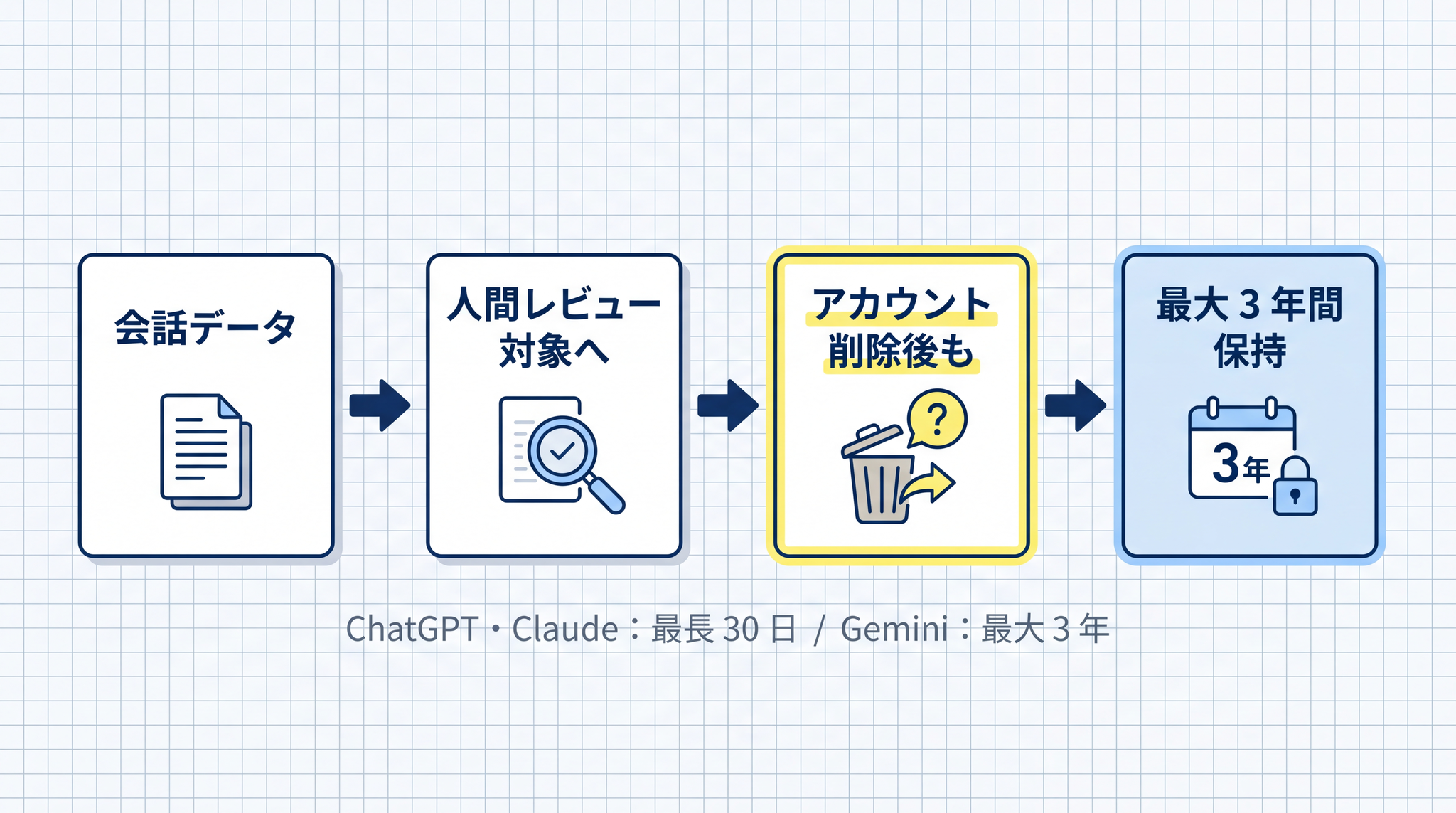
3 サービスの比較(2026 年 5 月時点)
3 サービスの中で Gemini Consumer 版だけが、人間によるレビュー対象になった会話データを 最大 3 年間 保持します。ユーザーが履歴を削除しても、レビューに移行したデータは消えません。
自分が個人向けプランを使っているか法人向けプランを使っているかは、各サービスのアカウントページにあるサブスクリプション・プラン設定から確認できます。
| サービス | 個人向けデフォルト | 法人向けデフォルト | 学習オフ時のデータ保持 |
|---|---|---|---|
| ChatGPT | オプトイン(学習あり) | オプトアウト(学習なし) | 最長 30 日 |
| Claude | 選択必須/事実上オプトイン(2025 年秋以降) | オプトアウト | 最長 30 日 |
| Gemini | オプトイン | オプトアウト | 最長 3 年(人間レビュー対象分) |

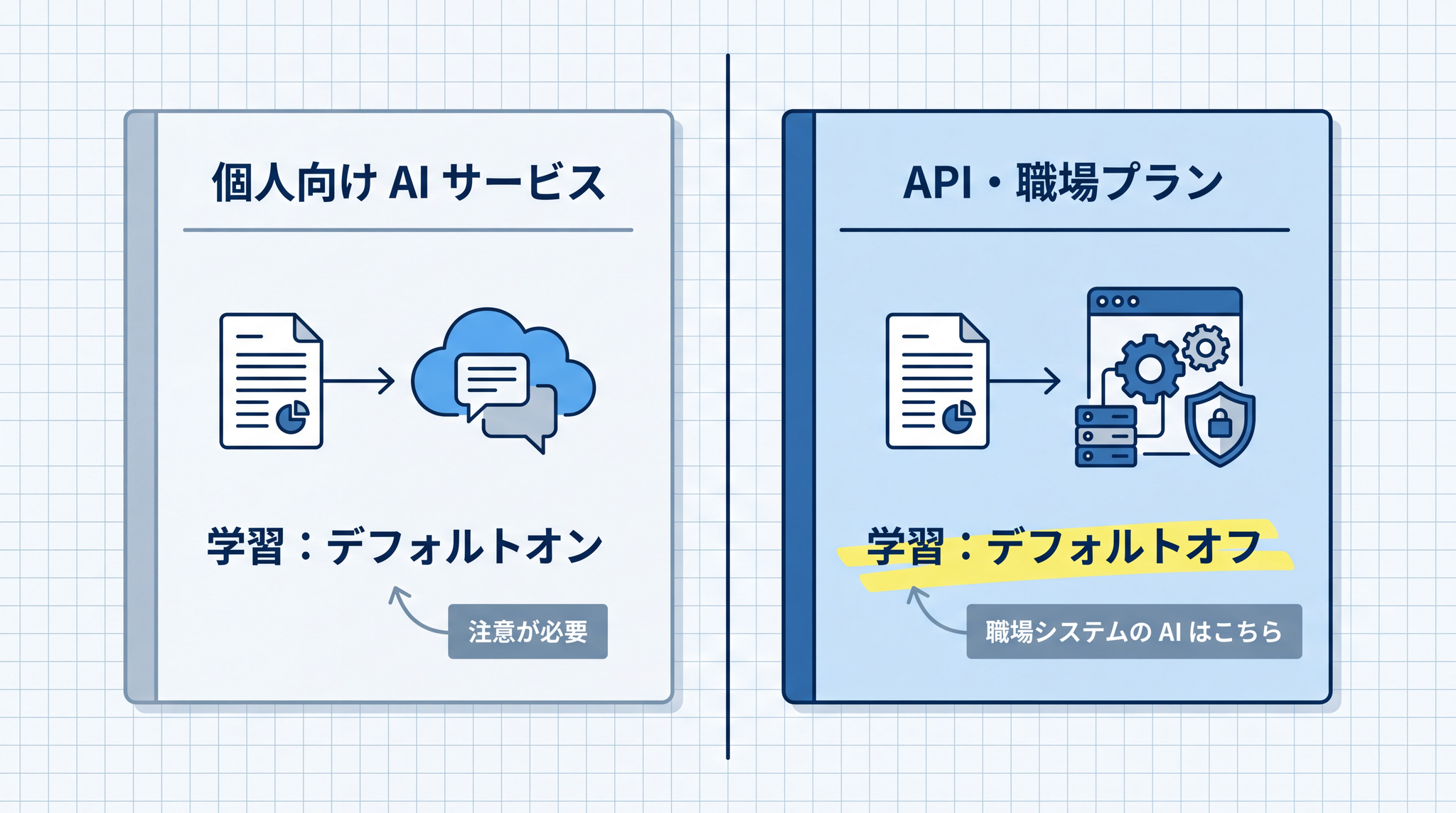
API 利用の場合
3 サービスいずれも、API(アプリ開発者向けの接続方式)経由での利用はデフォルトでモデルのトレーニングに使われません。職場や学校が導入しているシステムに AI が組み込まれている場合、個人向けの無料プランとは異なるデータの扱いが適用されている可能性があります。使っているサービスの契約形態については IT 担当者に確認するのが確実です。
7. 入力 vs 出力 ── 著作権との違いをひとことで
「AI と著作権 ── 「使っていい?」に答える 3 つの問い」は出力(生成された文章・画像)の権利の話で、根拠は著作権法です。本記事は入力の安全性で、根拠は個人情報保護法・守秘義務です。この 2 つを混同すると、判断の土台にする法律がズレて正しく判断できなくなります。
8. まとめ:今日から使える 3 つのライン
- ライン 1(個人情報):他者の氏名・住所・連絡先・生体情報を本人の同意なく入力しない
- ライン 2(守秘義務):業務上知った情報は、就業規則に明記がなくても守秘義務の対象になる。個人向けの AI サービスへの入力は、秘密管理性の喪失リスクを伴う
- ライン 3(社内規程と利用規約):組織のルールと AI サービスのルールは両方を守る必要がある。どちらか一方だけでは不十分
迷ったときは「この情報をインターネット上に自分の名前で公開できるか」という一問を使います。学習設定のオプトアウトや法人向けプランへの切り替えはリスクを下げる補完的な対策ですが、3 本のラインは設定の有無にかかわらず適用されます。
後ろめたさを感じながら使い続けるより、3 本のラインを頭に置いて「これは入れていい」と判断できるほうが、AI を長く安心して使い続けられます。まず自分の手元のツールで、学習設定がどうなっているかを確認するところから始めてみてください。

次に読む
- AI と著作権 ── 「使っていい?」に答える 3 つの問い:入力の安全性を理解したら、AI が生成した出力(文章・画像)の著作権も整理しておくと、判断の地図が完成します。
- AI に教科書を渡してから聞く ── 自分の文書を答えに使わせる方法:入力してよい情報を整理したあとは、自分の文書を安全に AI に活用させる方法を知ると次のステップに進めます。