自社サーバーで動かせる AI はある? ── オープン・クローズドの構造と業務判断
目次
「自社サーバーで動かせる AI ってないの?」── AI についての相談を受けていると、この質問は必ず出てきます。
ChatGPT のようなクラウド型の AI を使うと、入力した内容は外部のサーバーに送信されます。社内の機密資料や顧客情報を扱う業務では「それは困る」という場面が出てきます。答えは「あります」です。ただし、「オープン」「クローズド」という言葉の中身が、実はなかなか一筋縄ではいきません。
この記事では、AI の「公開」に何段階あるかを整理します。定義をめぐる業界の議論も正直に紹介した上で、業務での判断軸を 1 本で整理します。

1. 「自社サーバーで動かす」とはどういうことか
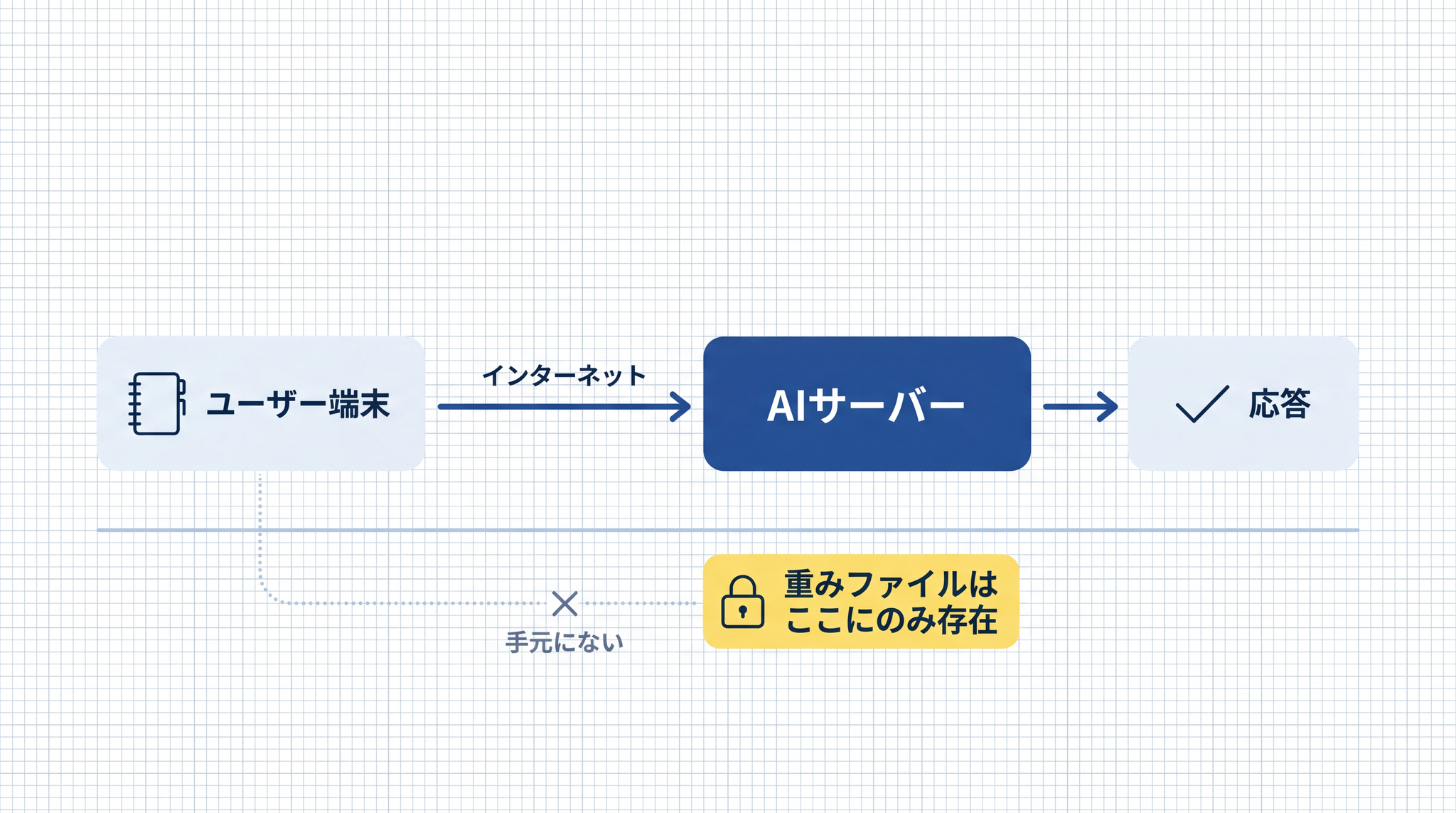
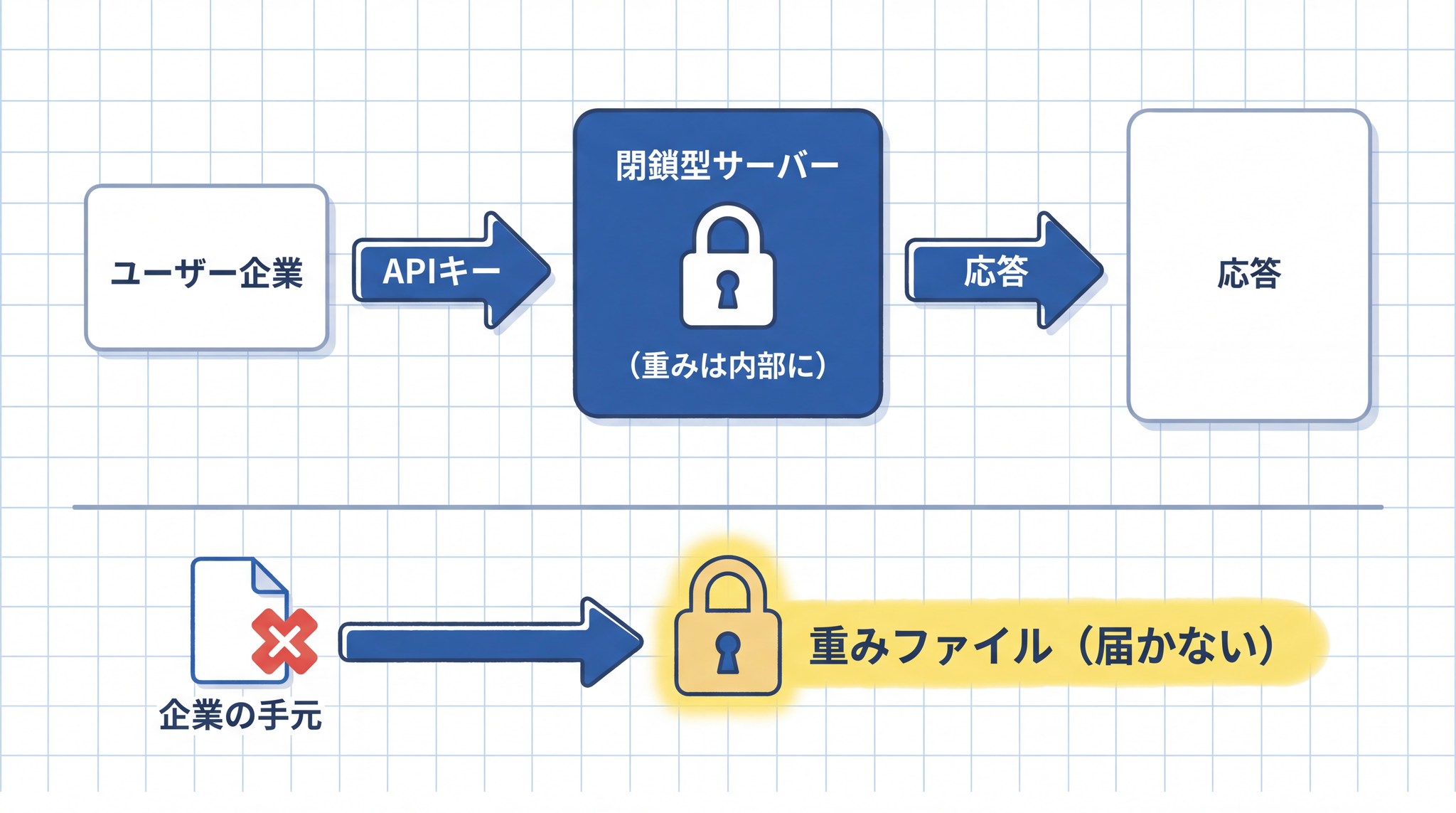
ChatGPT や Claude を使うとき、処理の本体は手元にありません。パソコンやスマートフォンは窓口に過ぎず、データはインターネット経由で OpenAI や Anthropic のサーバーに届き、そこで答えが生成されます。
「自社サーバーで動かす」とは、AI の本体 ── モデルのファイル(重み) ── を自分たちのコンピューターに置いて、外部に頼らずに動かすことです。
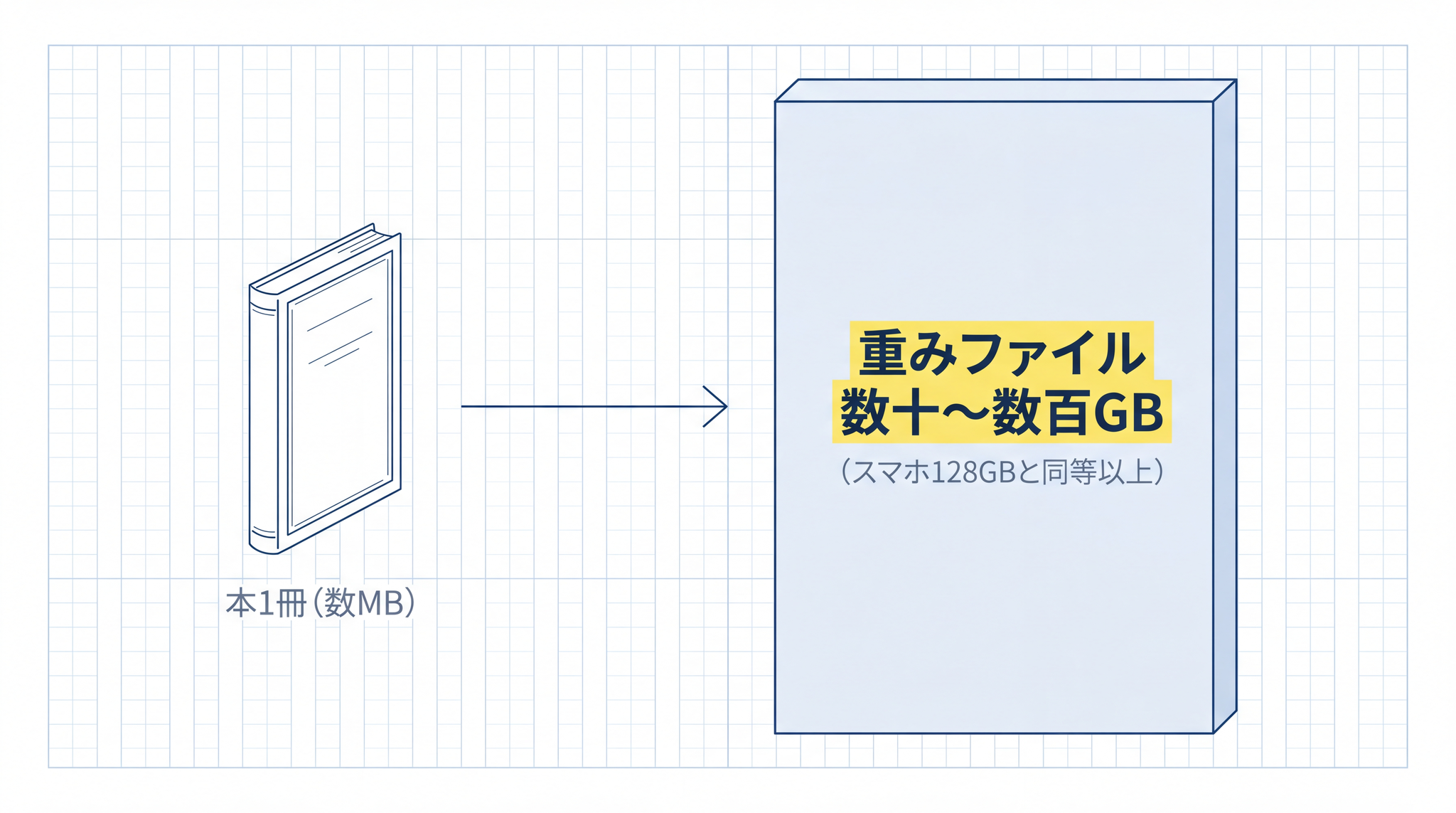
「重み」とは何かというと、AI が言葉を理解・生成する能力が詰め込まれた、巨大な数値の集合体です。本の中身のような存在で、代表的なモデルでは数十〜数百 GB(ギガバイト)になります。スマートフォンの内部ストレージ(128GB 程度)と同じか、それ以上の大きさです。このファイルを手元に置けるかどうかが、「自社で動かせるか」の核心です。
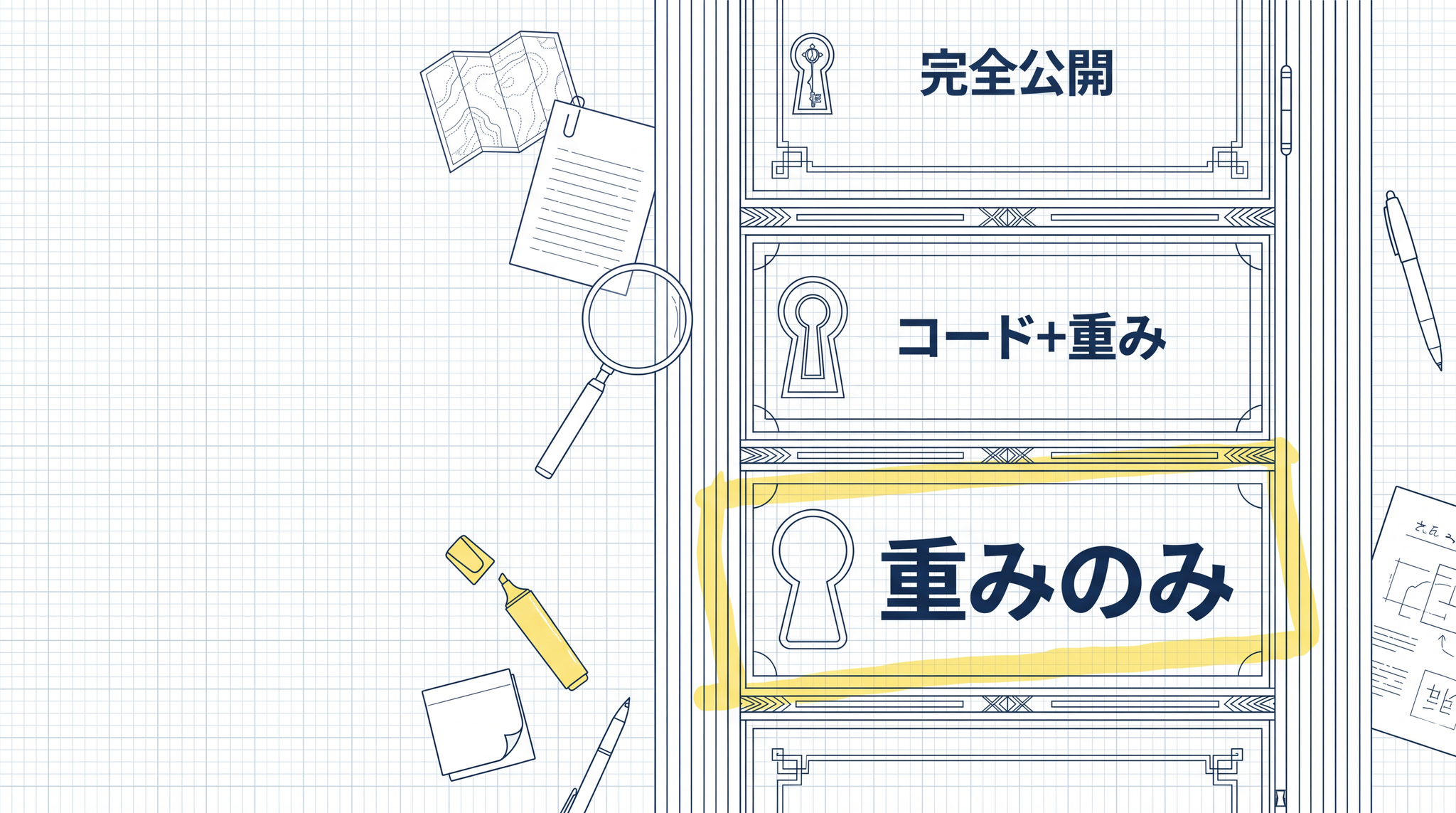
2. AI の「公開」には段階がある ── 3 層の連続体

「オープンソース AI」と聞くと「全部公開されている」と想像しがちですが、実際には「何が公開されているか」によって大きく 3 段階に分かれます。
なお、業界には MOF(Model Openness Framework、モデル開放性フレームワーク) という本記事の 3 段階に近い分類体系もありますが、本記事では実務判断に必要な範囲で整理します(細部は MOF 仕様書 1 を直接参照してください)。
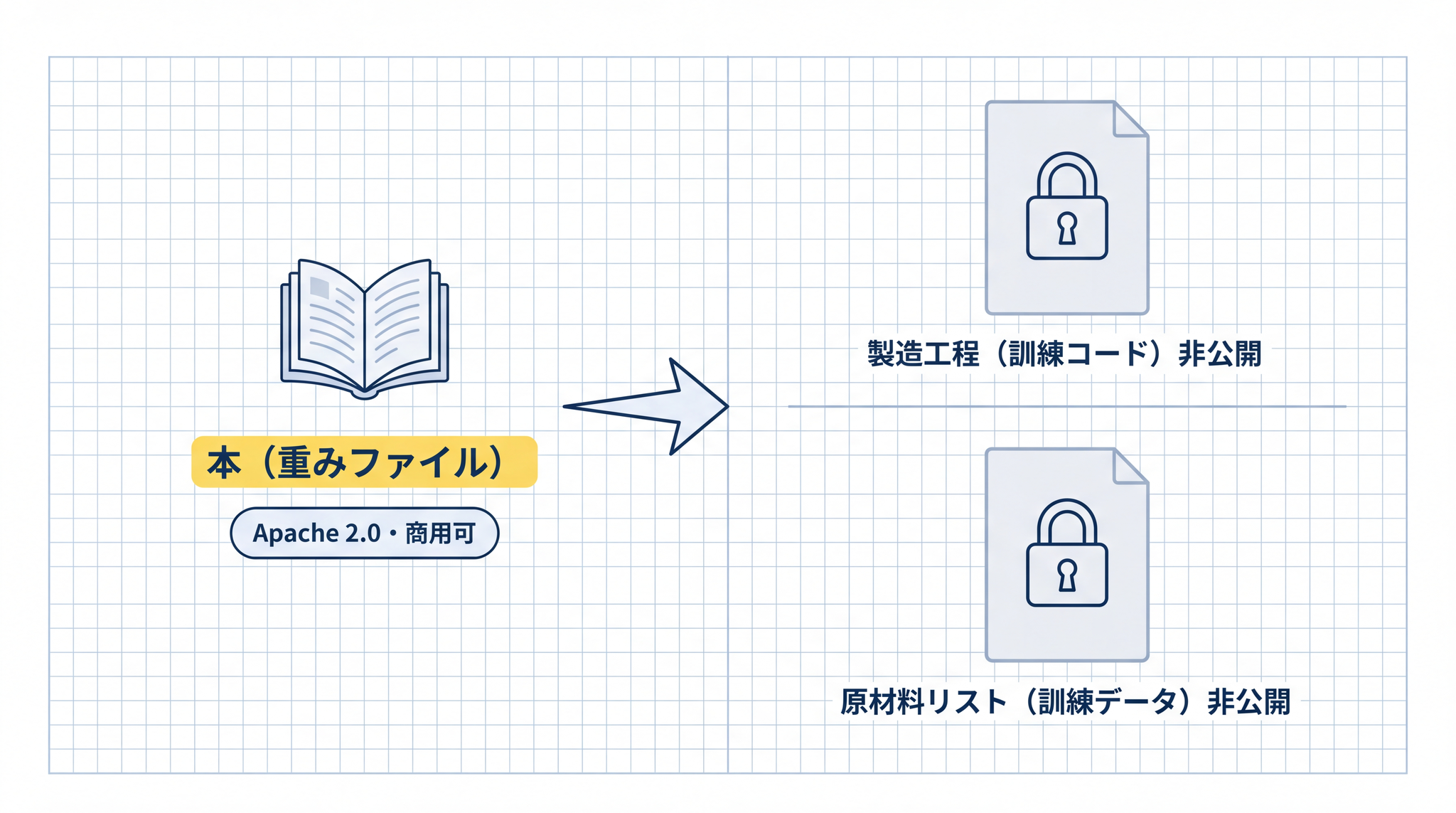
段階 1:重みのみ公開(Open Weights)
モデルのファイル(重み)だけが配布されている状態です。自社のサーバーに持ち込んで動かせます。ただし、どのように学習させたか(訓練コード)や、何のデータで学習したか(訓練データ)は非公開です。
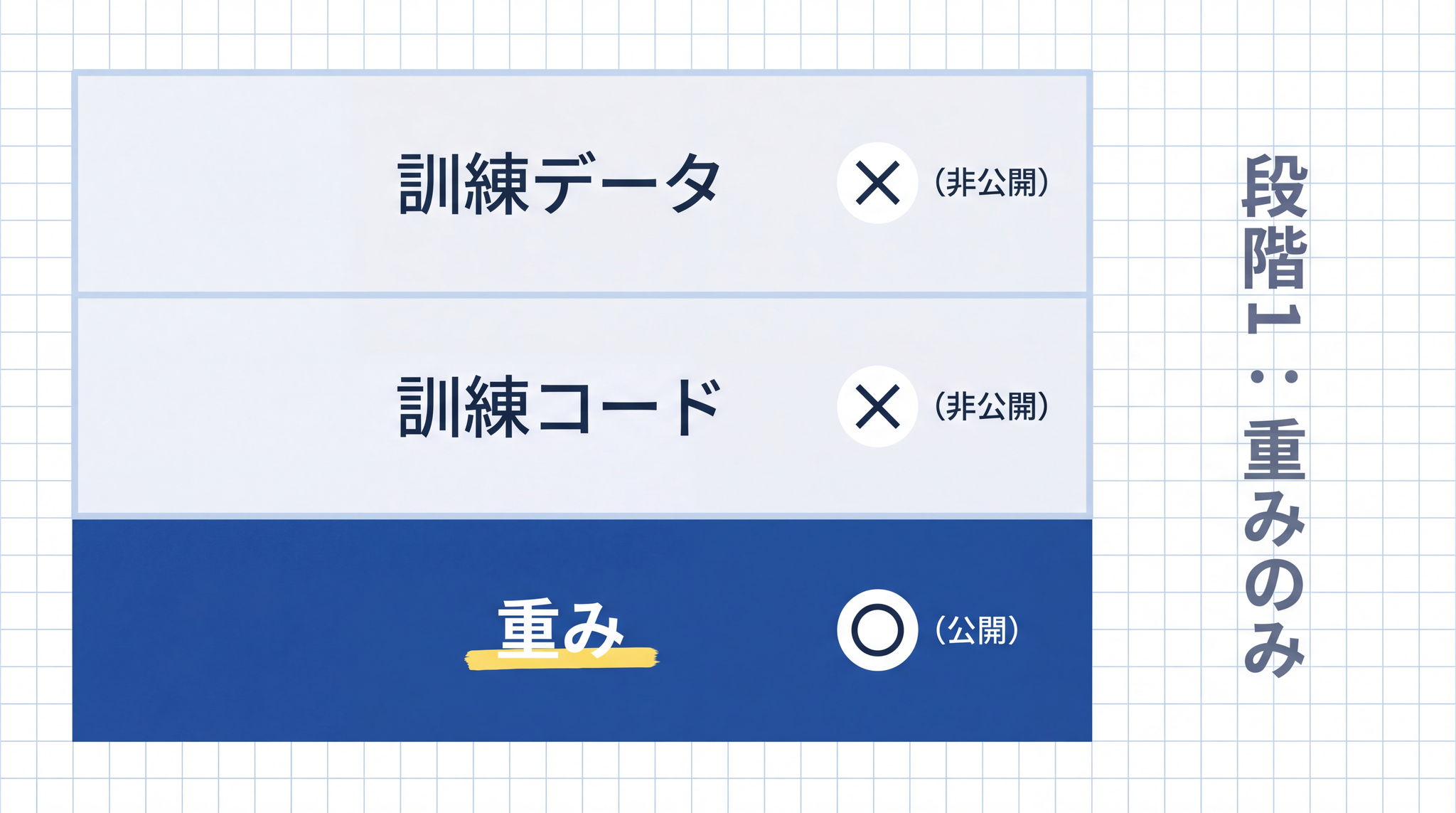
「本の中身は渡すけど、どう書いたかは教えない」というイメージです。
Meta の Llama 4 が代表例で、Meta 自身が公式ブログでこれを “open-weight” と呼んでいます。2 Mistral Large 3 や Google の Gemma 4 も同じカテゴリです。34 いずれも商用利用が許可された条件で配布されています(Apache 2.0 ライセンス)。
段階 2:コード + 重み公開
重みに加えて、訓練コードやアーキテクチャ(どういう構造で AI を組んだか)も公開されている状態です。「どういう設計で学習させたか」が外部から確認できます。MOF の Class II(クラス 2)では、この段階に主要な訓練データセットも含まれます。段階 1 と 3 の中間にあたります。
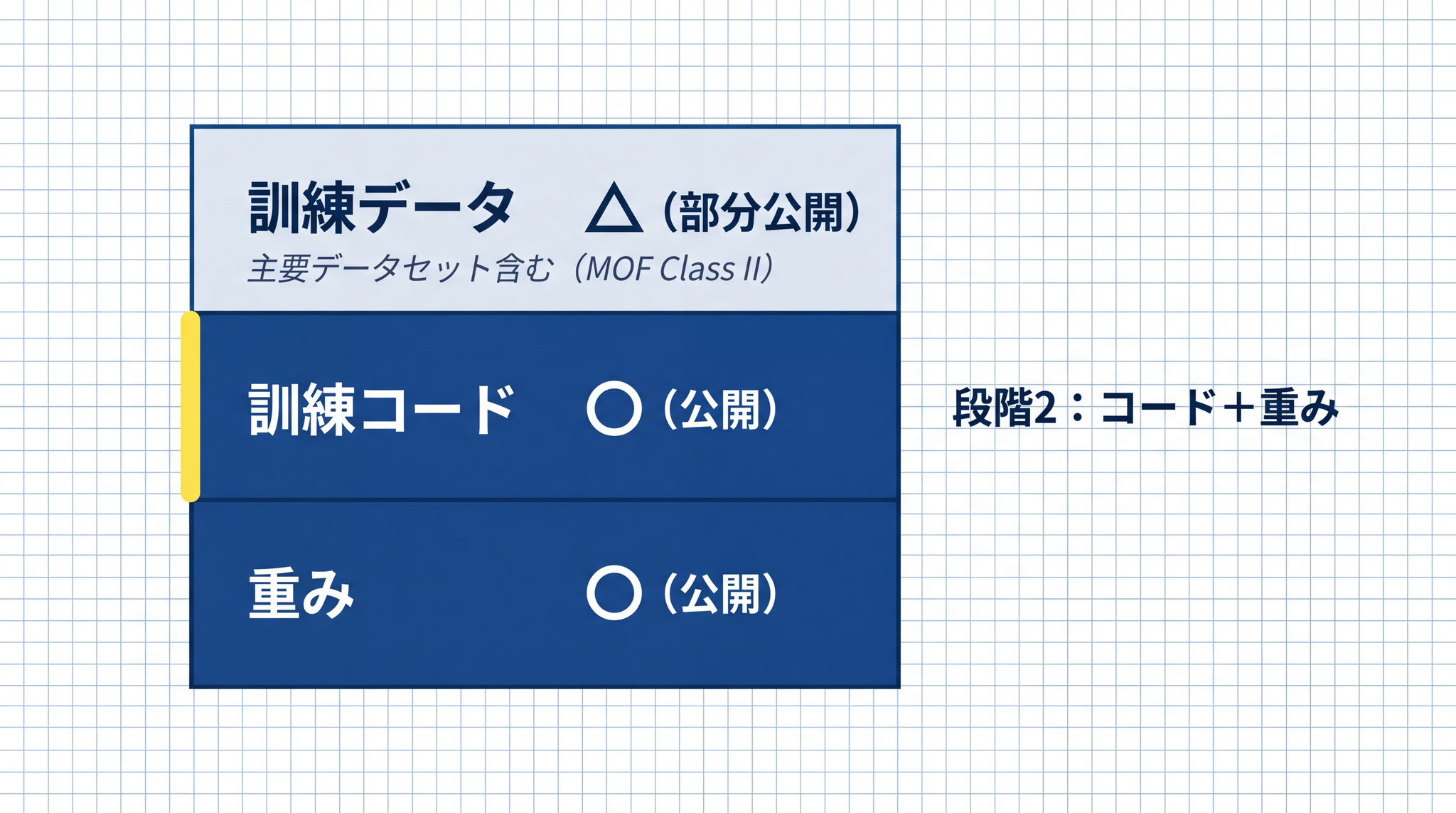
業務での選択肢としては、現実的には段階 1 か段階 3 かクラウド型の 3 択が多く、段階 2 が単独で登場する場面は少ないです。
段階 3:学習データも含む完全公開(Fully Open)
重み・コード・訓練データのすべてが公開される状態です。第三者が同じ条件で再現できるレベルの透明性を持ちます。現時点では学術研究用途のモデルが主で、一般的な業務での実用例は段階 1 が中心です。
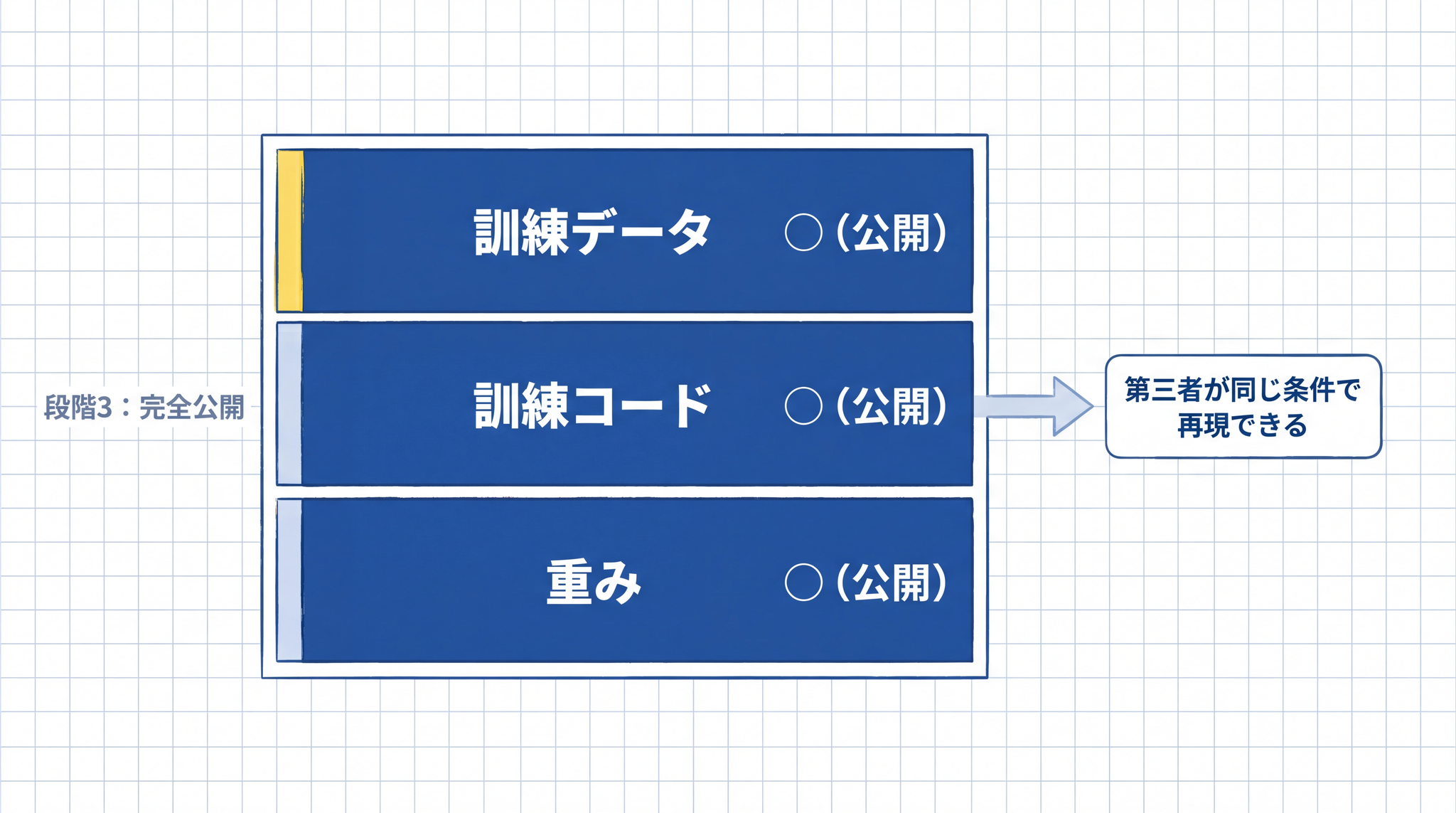
Allen Institute for AI(AI2)の OLMo 2 が代表例で、重み・訓練データ・訓練コード・評価コード・中間チェックポイントまで公開されています。5 EleutherAI の Pythia も、重みから訓練データ(The Pile、825GB)まで揃えた完全公開モデルです。6

まとめると
公開段階が上がるほど重みからコード・訓練データへと開示範囲が広がり、完全公開では第三者による再現が可能になる。
| 公開段階 | 重み | 訓練コード | 訓練データ | 代表例 |
|---|---|---|---|---|
| 段階 1:重みのみ | ○ | × | × | Llama 4、Gemma 4、Mistral Large 3 |
| 段階 2:コード+重み(主要データ含む) | ○ | ○ | 主要データを含む | Mistral 7B 初期など |
| 段階 3:完全公開 | ○ | ○ | ○ | OLMo 2、EleutherAI Pythia |
| クローズド | × | × | × | GPT 系、Claude 系、Gemini 系 |
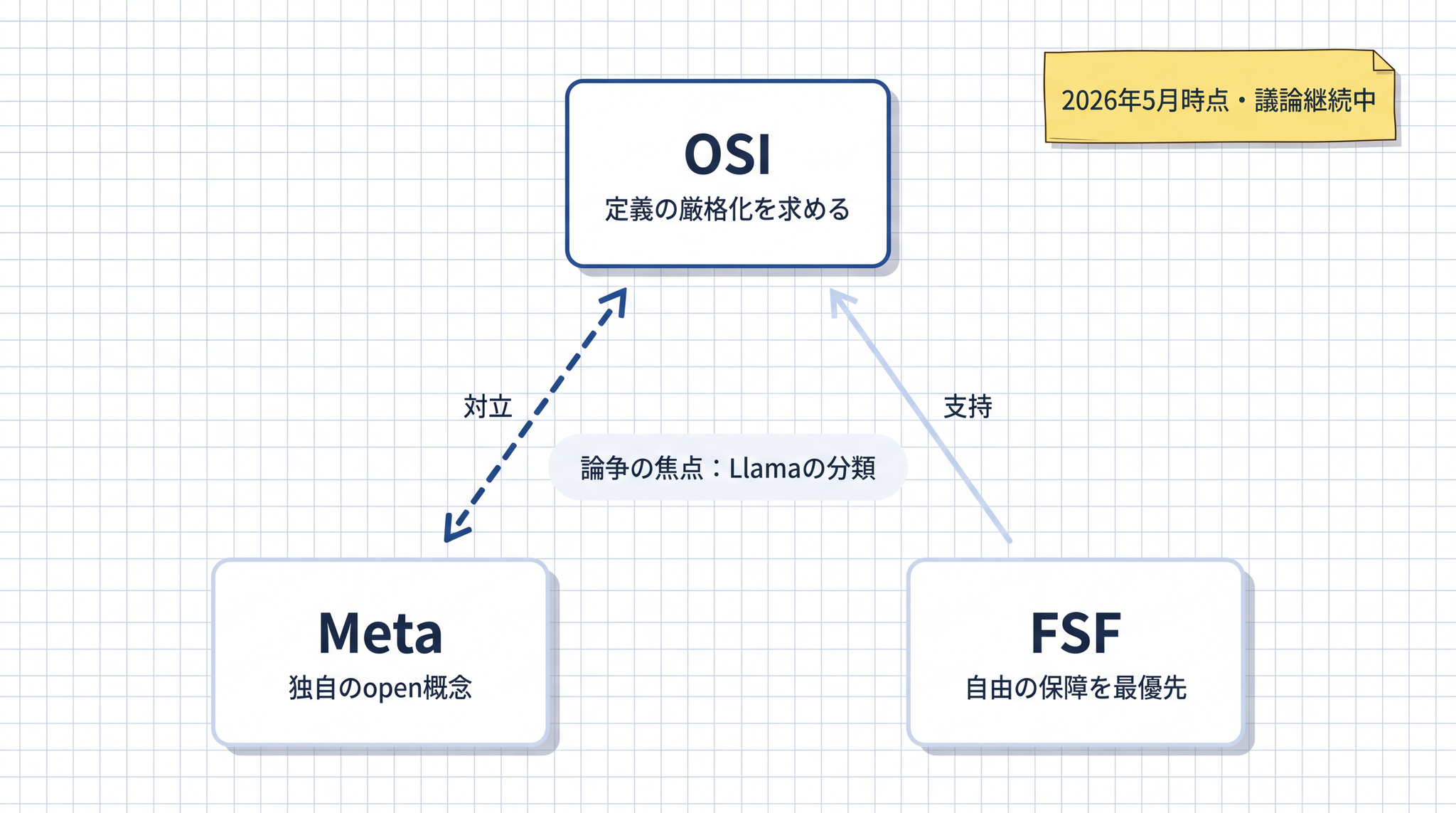
3. 「オープンソース AI」の定義はいまも論争中
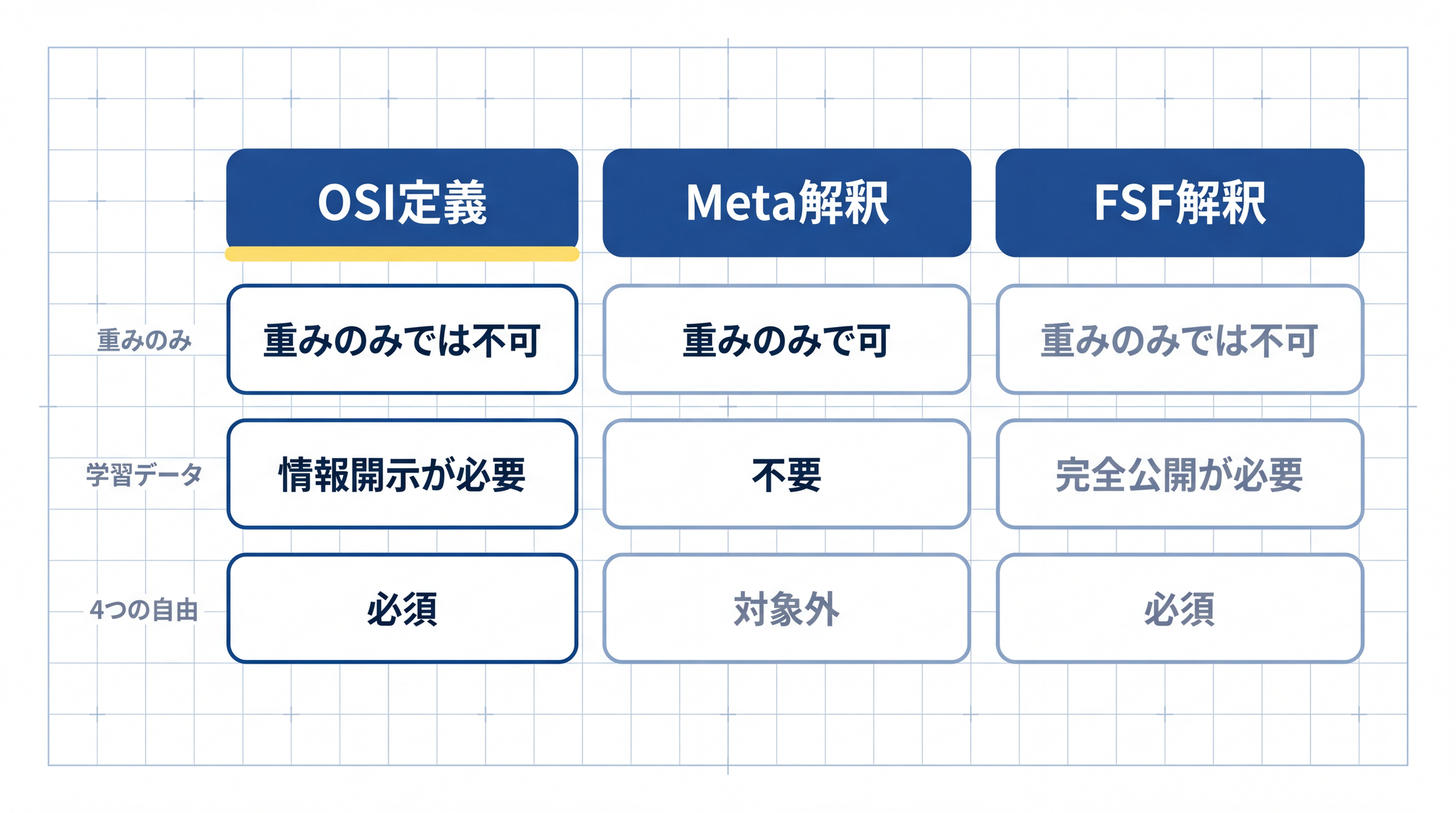
ここで正直に触れておきます。「オープンソース AI」という言葉の意味が、業界でいまも揺れているという事実です。
OSI(Open Source Initiative、オープンソースの定義を管理する国際的な非営利組織)は、2024 年 10 月 28 日に AI 向けの定義 OSAID(Open Source AI Definition)v1.0 を正式に発表しました。78 その核心は「使用・調査・改変・配布の 4 つの自由を保障すること」です。
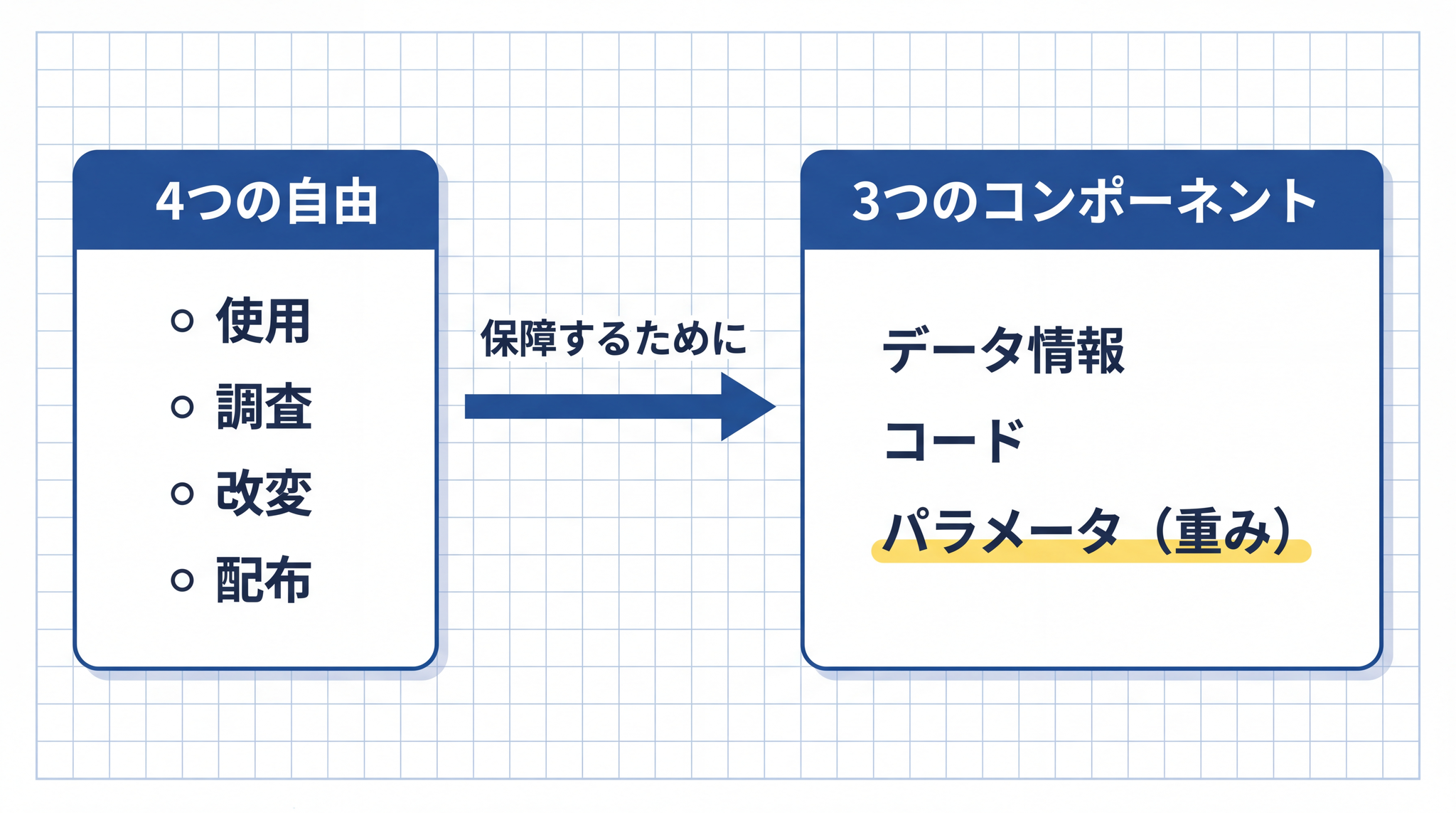
訓練データの完全公開が著作権やプライバシーの制約で困難な場合は、詳しい第三者がほぼ同等のシステムを構築できる程度の情報開示が代替要件として認められています。
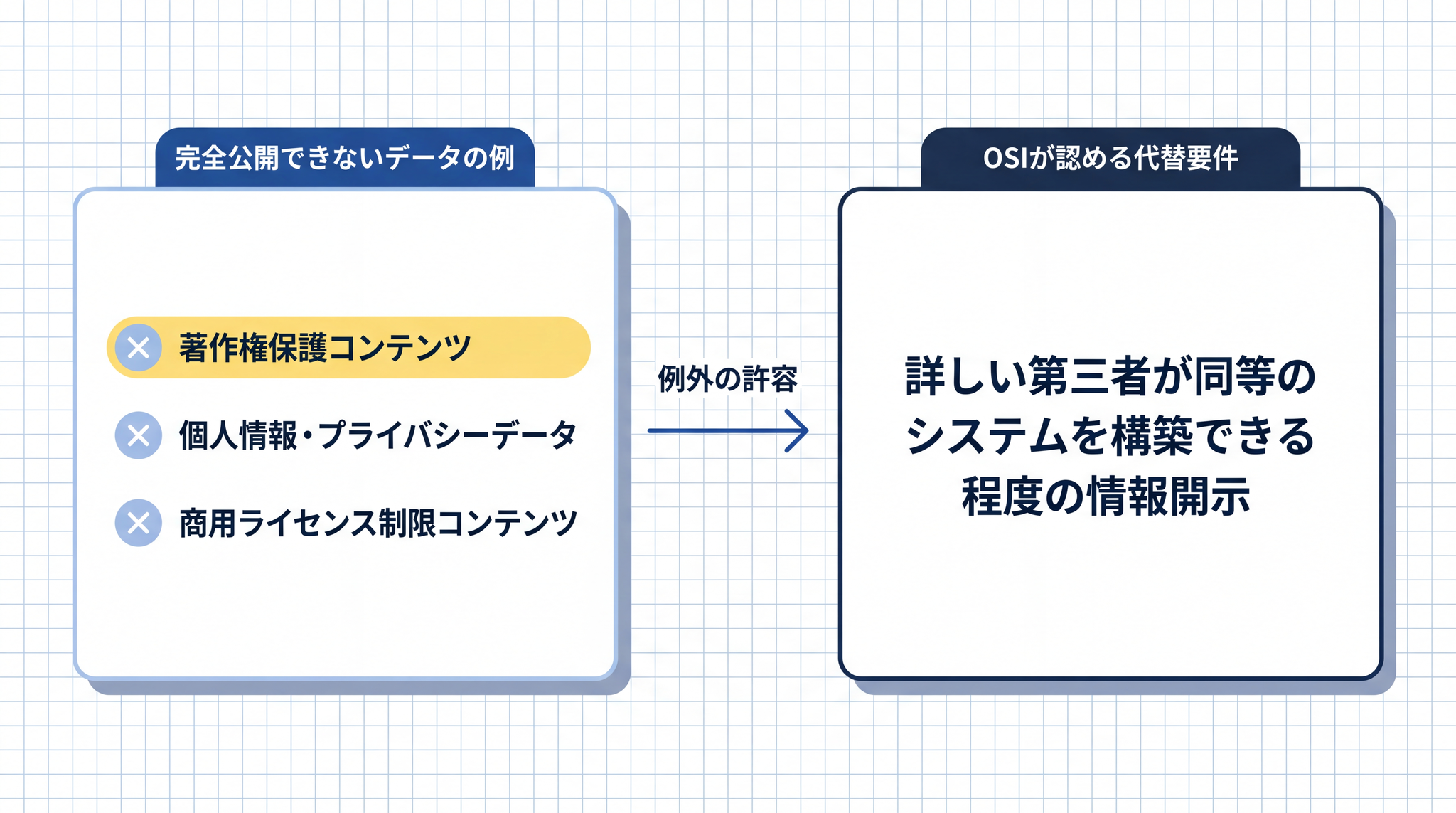
この OSI の基準で見ると、Llama 4 は「オープンソース AI」と認定されていません。主な理由は、競合モデルへの利用制限・月間利用者数(MAU、Monthly Active Users)が一定規模を超えた場合の使用制限・EU(European Union、欧州連合)居住者へのマルチモーダル機能の適用除外などです。910

OSI はこれを「オープンウォッシング」── 実際には自由に使えないのに「公開している」と名乗る行為 ── と呼んでいます。

OSAID の定義はいまも更新プロセスが続いており、議論が進んでいます(2026 年 5 月時点)。11
この記事で「公開の 3 段階」を使っているのは、「OSI 基準に合格か否か」の二択ではなく、「実際に何が手元に置けるか」 という実務の視点からの整理です。段階 1 のモデルを使う際は、それぞれのライセンス条件を確認した上で利用してください。
4. 閉鎖型 AI も一枚岩ではない
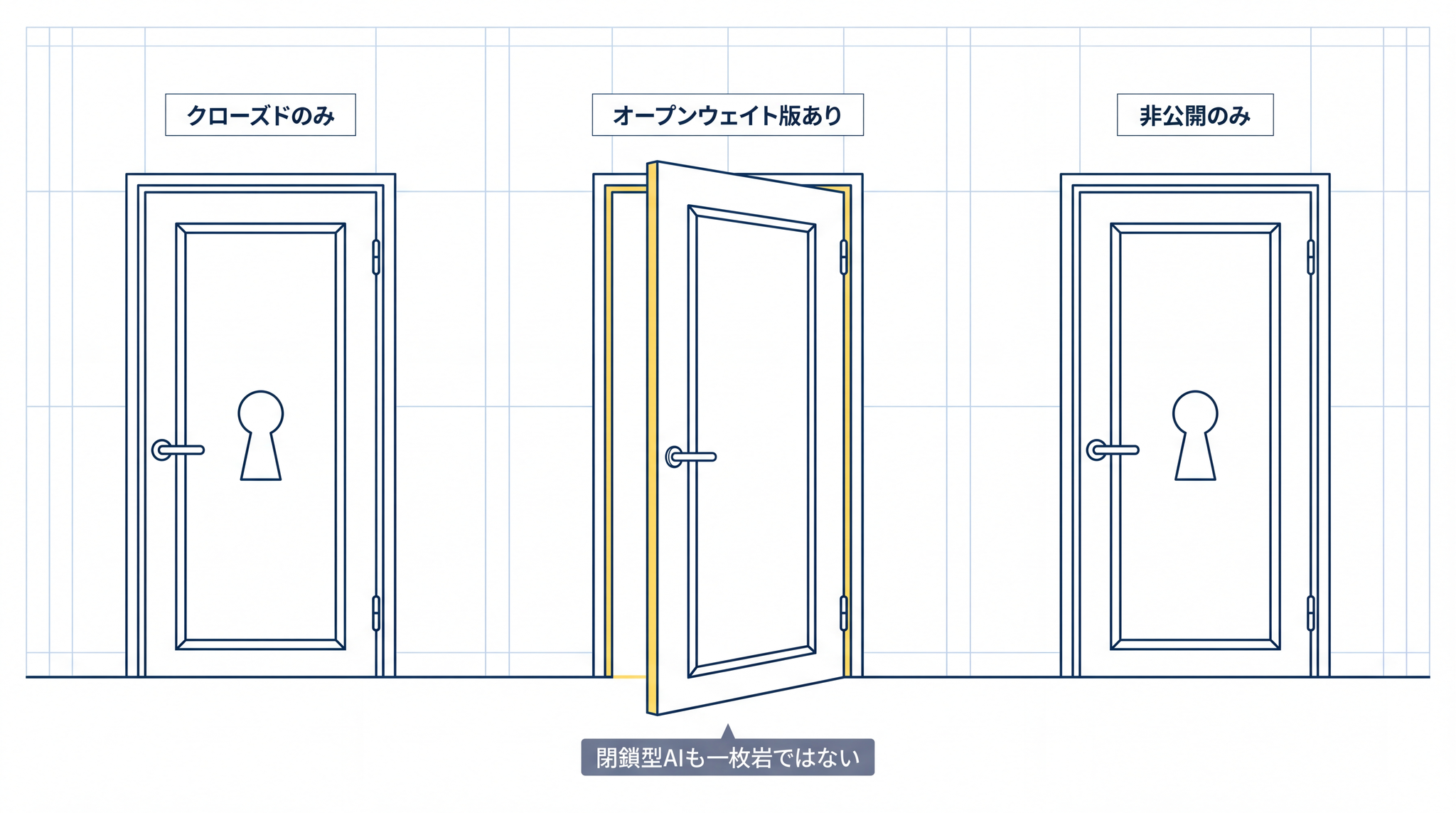
2026 年時点では「クラウド型 AI はすべてクローズド」という単純な図式は成り立ちません。

OpenAI は GPT 系の重みを非公開にしています。外部の AI サービスに接続して使う仕組み(API)形式での提供にとどめる理由として、重みや機密情報を管理下に置くためと公式ドキュメントに明文化されています。12 一方で 2025 年 8 月には gpt-oss-120b と gpt-oss-20b を商用利用が許可された条件(Apache 2.0 ライセンス)で公開しました(同社として GPT-2〈2019 年〉以来となるオープンウェイトリリース)。13 主力フロンティアモデルとは別の位置づけですが、「同一企業がクローズドとオープンの両形態を同時に持ちうる」ことを示しています。
Anthropic は Responsible Scaling Policy(責任ある拡張方針)で、「後から特定の用途向けに追加学習させること(ファインチューニング)によって安全ガードレールが容易に無効化されうる」として重みを非公開にする理由を説明しています。14
Google も同様に、クローズドの Gemini 系(API 専用)と、ローカル運用も可能な Apache 2.0 公開の Gemma 4 を並存させています。
5. クラウド API のデータポリシー ── 「貼っていいか」の確認
「クラウド型を使うと業務データが学習に使われる」という不安は、現時点(2026 年 5 月確認)では API・エンタープライズの利用においてデフォルトで訓練利用しない方針が各社で確認されています。
OpenAI・Anthropic・Google Cloud の主要 3 社はいずれも、API 利用時のデータをデフォルトで訓練に使用しない方針を表明しています。
| 提供者 | API のデータ扱い(デフォルト) |
|---|---|
| OpenAI | API・Enterprise からのデータは訓練に使用しない15 |
| Anthropic | API データは明示的な許可なく訓練に使用しない(ZDR(Zero Data Retention:入力データを一切保存しない契約方式)対応)16 |
| Google Cloud(Gemini) | 有料 API のデータは訓練に使用しない17 |
API 利用前に利用プランを確認し、各社のプライバシーポリシーで訓練への利用条件を確認することが、守秘性の判断の出発点になります。
ただし、ChatGPT の無料プランや個人向けプランはポリシーが異なる場合があります。プライバシーポリシーは更新されます。利用前に各社の最新ポリシーを確認してください。
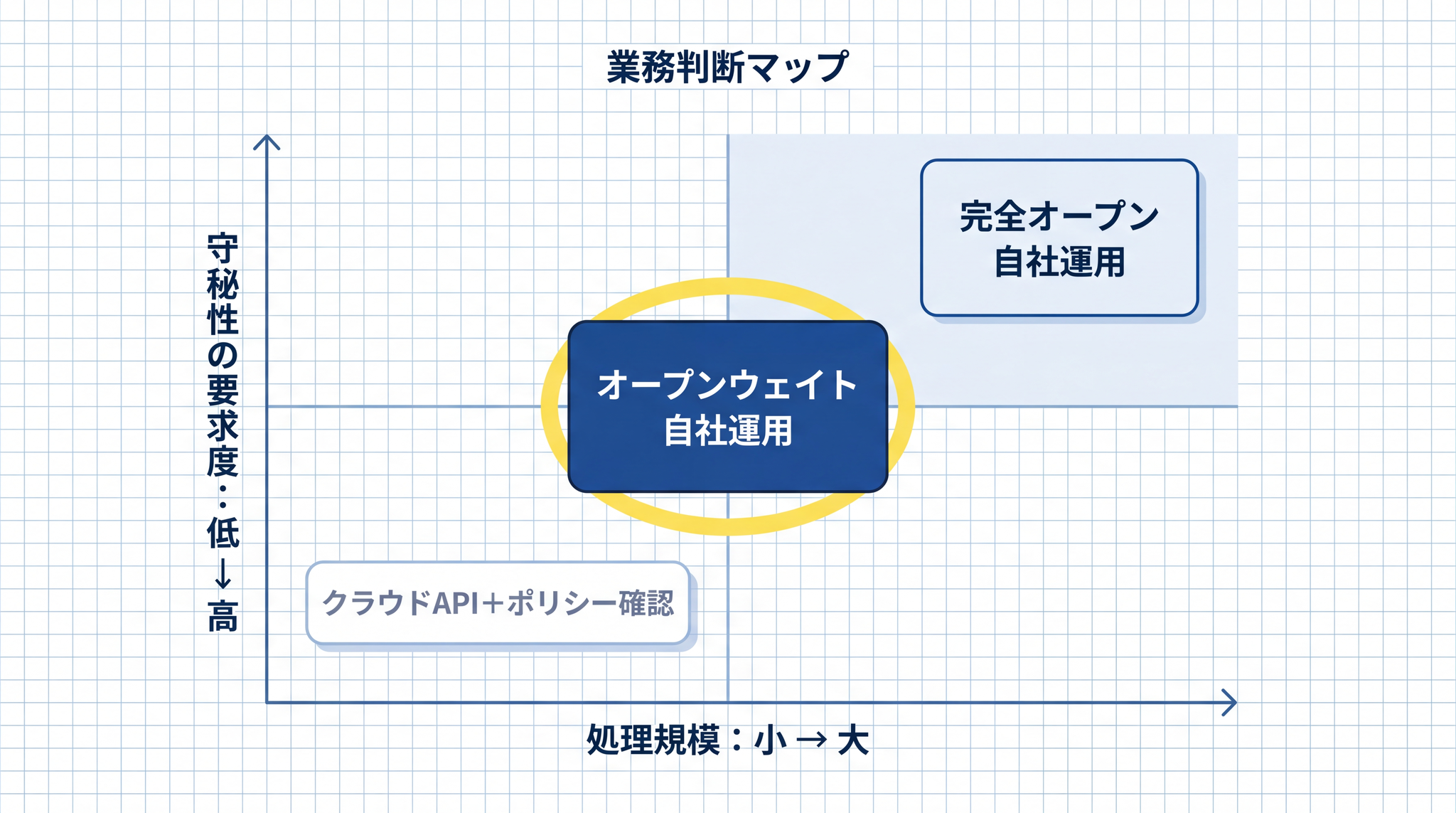
6. 業務での選び方 ── 判断軸を整理する

「守秘データが多い業務か、最新性能を優先したい業務か」── この 2 軸が選択の起点になります。
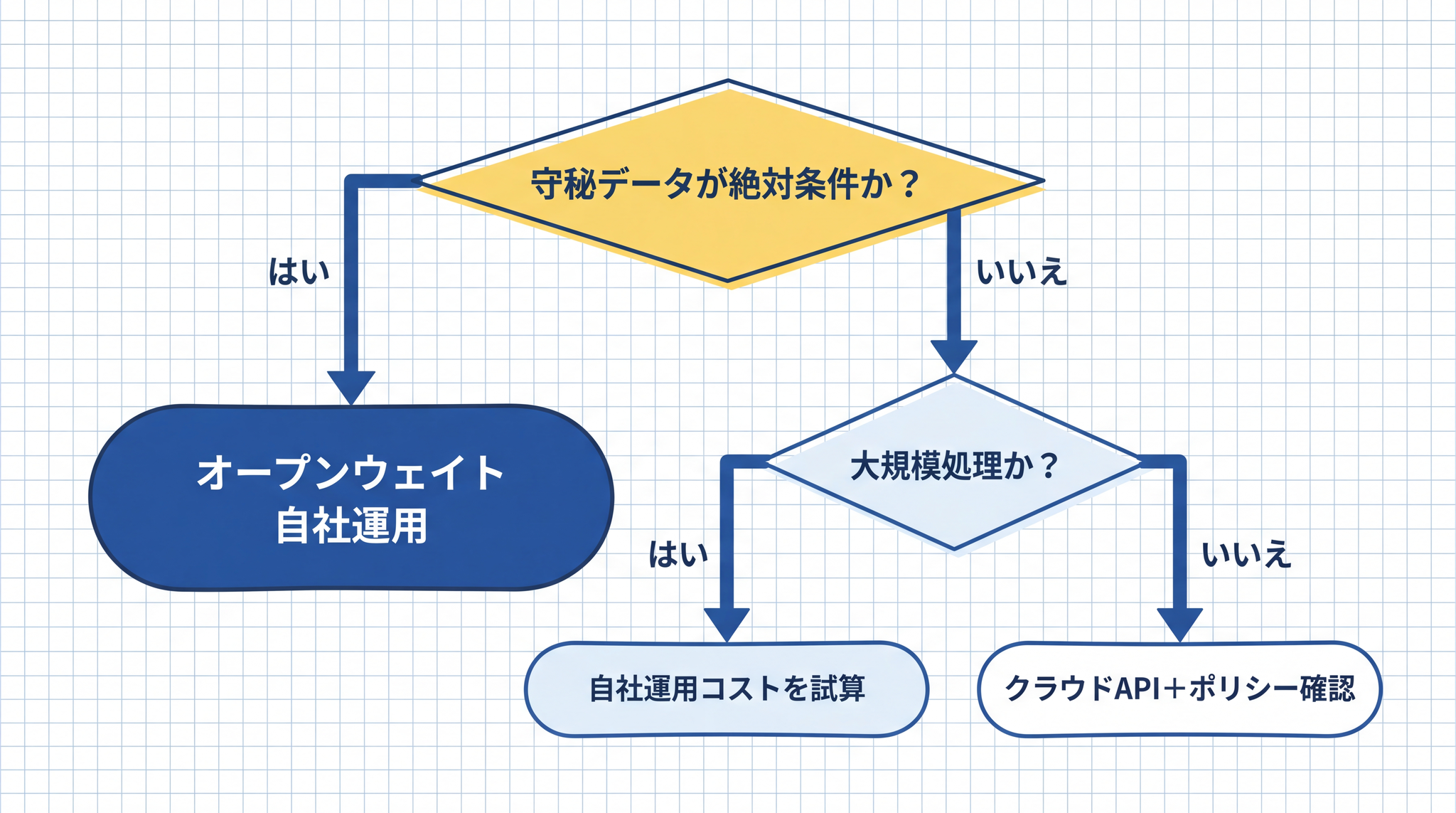
守秘性・性能・コスト・処理規模という 4 つの優先事項に応じて、自社運用とクラウド API の選択肢が分かれます。
| 優先事項 | 選択肢 | 業務シーン例 |
|---|---|---|
| データを外に出したくない(絶対条件) | オープンウェイトモデルの自社運用(社内 IT 担当またはシステムベンダーへの相談が起点になります) | 社内 DB・顧客情報・未公開の設計書を扱う業務 |
| 最新・高性能の AI が必要 | クラウド API(API ポリシー確認の上) | 議事録の要約・社外向け文書のドラフト作成 |
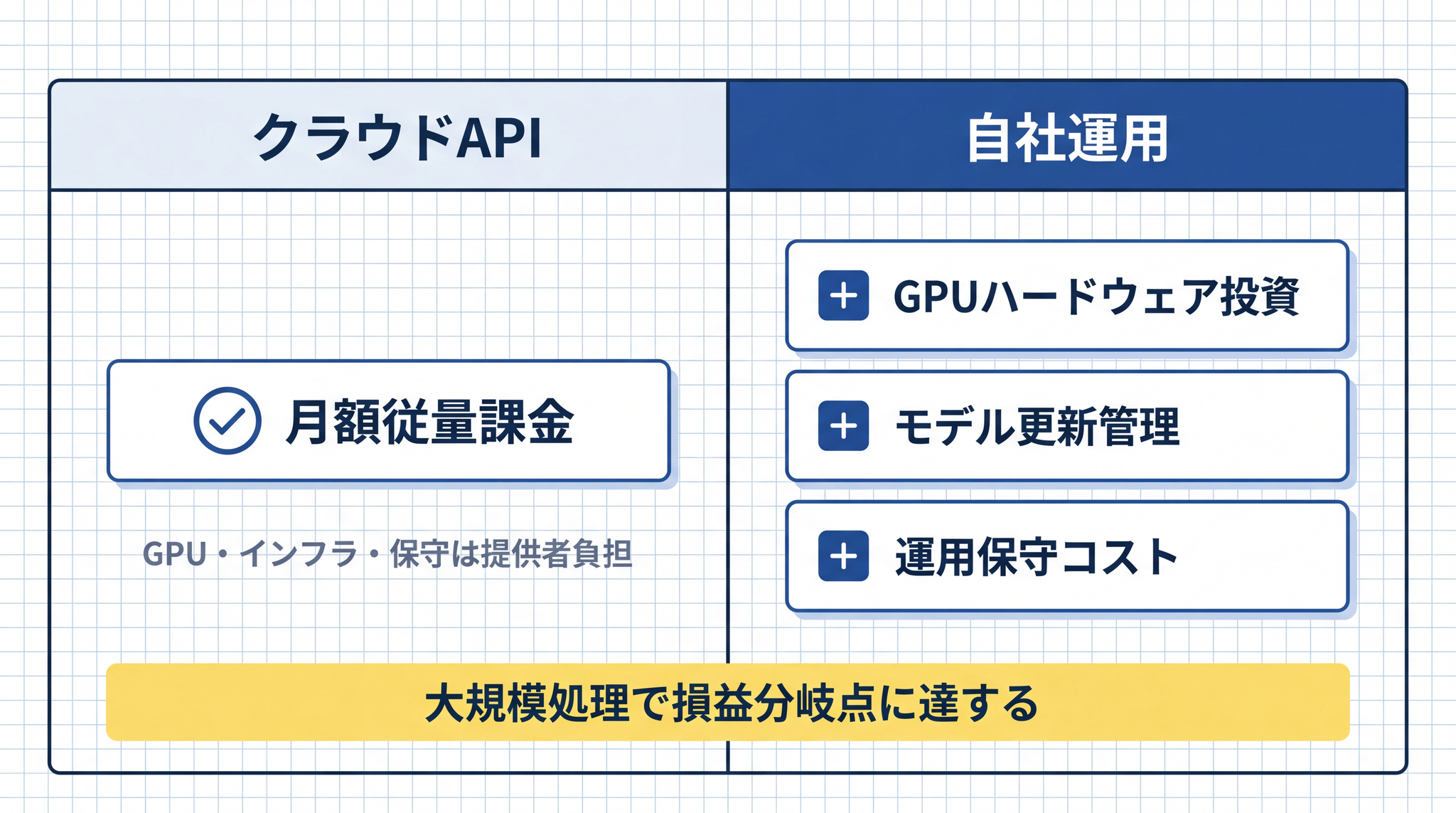
| 中規模以下のコストを抑えたい | クラウド API(月間処理量が少なければ桁違いに安価) | 月数千〜数万件の問い合わせ応答(A4 文書 1 枚 ≈ 1,000〜2,000 トークン) |
| 超大規模処理でコストを回収したい | 自社運用を試算(1 日数千万〜1 億トークン(AI が処理する文字量の単位)以上が目安。一般的な中小規模の業務では月額数千〜数万円程度のクラウド API のほうが現実的なことが多いです)18 | 製造ライン異常検知ログの一括分析・大量顧客 DB の定期処理 |
まずは ChatGPT や Claude の API ポリシーを確認して使い始めることが現実的な第一歩です。
自社運用を選ぶ場合は、GPU(Graphics Processing Unit、AI 計算に使う高性能なチップ)を含む専用ハードウェア・モデル更新管理・運用保守のコストとリソースが発生します。クラウド API ではこれらが利用料金に含まれています。
規制が厳しい分野(医療・金融など)では、データレジデンシー(データの保存場所の要件)から自社運用が必要なケースもあります。19
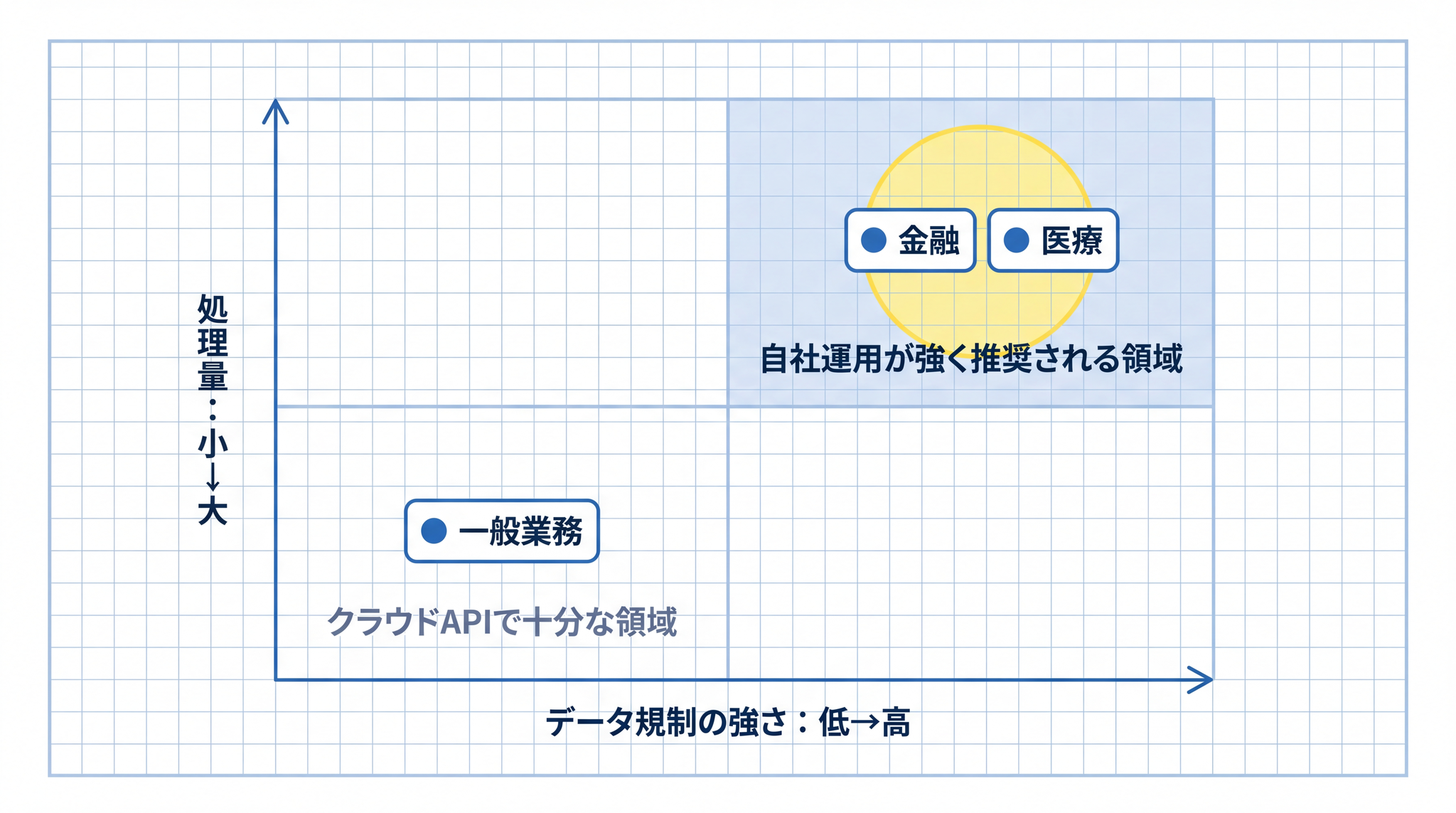
API ポリシー上は訓練利用なしと確認できても、自社の情報セキュリティポリシーで社外送信が禁止されているケースでは、自社運用が選択肢になります。「ポリシーを確認してから使う」という判断は合理的ですが、社内規程との照合も忘れずに確認してください。
機密データがあるかどうか・費用・管理できる人やベンダーがいるかどうかを、業務ごとに考える視点が判断の核心です。
7. 関連する記事
ChatGPT・Claude・Gemini の設計思想の違いについては、ChatGPT・Claude・Gemini はなぜ違うのか で整理しています。
AI に入力してよい情報の判断軸については、AI に貼り付ける前に確認すること が起点になります。この記事では「そのデータをどこで動かす AI に渡すか」の上流判断を扱っています。
自社の資料を AI に読ませて活用する実践については、AI に教科書を渡してから聞く を参照してください。
「公開の段階を 3 層に分けて考える視点を持つ」── これがこの記事で整理したことの核心です。「オープン vs クローズド」の単純な二択ではなく、何が公開されていて何が手元に置けるかを確認する。その上で、機密データがあるかどうか・費用・管理リソースを並べて判断する。
自分の業務に守秘データが入るかどうか、これが最初の分岐点です。そこから始めてください。
AI のオープン化は今も進んでいます。OpenAI のように「クローズド」の代名詞だった企業が方針を変えた事例もあります。自分がいますぐ何かをしなければならないわけではありませんが、「選択肢がある」と知っておくことが、いざというときの判断の出発点になります。
出典・参考文献
-
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation — Meta AI Blog ↩
-
The Open Source Initiative Announces the Release of the Industry’s First Open Source AI Definition ↩
-
The Open Source AI Definition — 1.0 | Open Source Initiative ↩
-
Meta’s LLaMa license is still not Open Source | Open Source Initiative ↩
-
Report from OSS EU 2025 and AI_dev: What’s next for OSAID | Open Source Initiative ↩
-
How Gemini for Google Cloud uses your data | Google Cloud Documentation ↩
-
A Cost-Benefit Analysis of On-Premise Large Language Model Deployment — arXiv ↩
-
Ensuring Open Source AI thrives under the EU’s new AI rules | Open Source Initiative ↩