
ロボット工学三原則とは ── SF の安全設計が、AI エージェントで通用しない理由
目次
- 1. SF の記憶と現実の AI
- 2. アシモフが考えた 3 つのルール ── 1942 年の設計思想
- なぜアシモフはこれを書いたか
- 3. 三原則が前提にしていた「ロボット像」
- 4. 現代の AI エージェントは何が違うか ── 前提が全部崩れる
- 崩れる前提 1:命令する人間が 1 人ではない
- 崩れる前提 2:AI に「命令を理解する」能力はない(別の仕組みで動く)
- 崩れる前提 3:「人間を傷つける」の定義が実装できない
- 崩れる前提 4:「命令に従う」の境界が攻撃の標的になる
- 5. 三原則が崩れた後に残るもの ── 現代の AI 安全設計の考え方
- 6. AI のトラブルは「誰の責任か」── 読者への手渡し
- 出典・参考文献
「ロボットは人間を傷つけてはならない」
映画や小説でこの言葉を見たことがある方は多いかもしれません。アシモフという SF 作家が 1942 年に考えた「ロボット工学三原則」です。
でも、今の ChatGPT や AI エージェントにこの原則は通用するのでしょうか。実は、三原則が前提にしていた「ロボットの像」と現代の AI は、根本的なところで違います。その違いを見ると、AI がトラブルを起こしたときに「誰が責任を持つのか」という現代の議論の背景が、少し整理できます。
1. SF の記憶と現実の AI
三原則を「時代遅れの SF 設定」として笑い飛ばしたいわけではありません。「AI の行動に誰が責任を持つのか」という問いは、三原則が提起したものであり、今も生きています。ただ、三原則が前提にしていた世界と、現代の AI が前提にしている世界は、根本的に違います。その違いを、順を追って見ていきます。
2. アシモフが考えた 3 つのルール ── 1942 年の設計思想
アイザック・アシモフ(Isaac Asimov)は、1942 年 3 月発行の SF 雑誌 Astounding Science Fiction に掲載した短編「Runaround(堂々めぐり)」の中で、三原則を初めて明文化しました。1
早川書房・小尾芙佐訳(「われはロボット」)の日本語訳を引用します。2
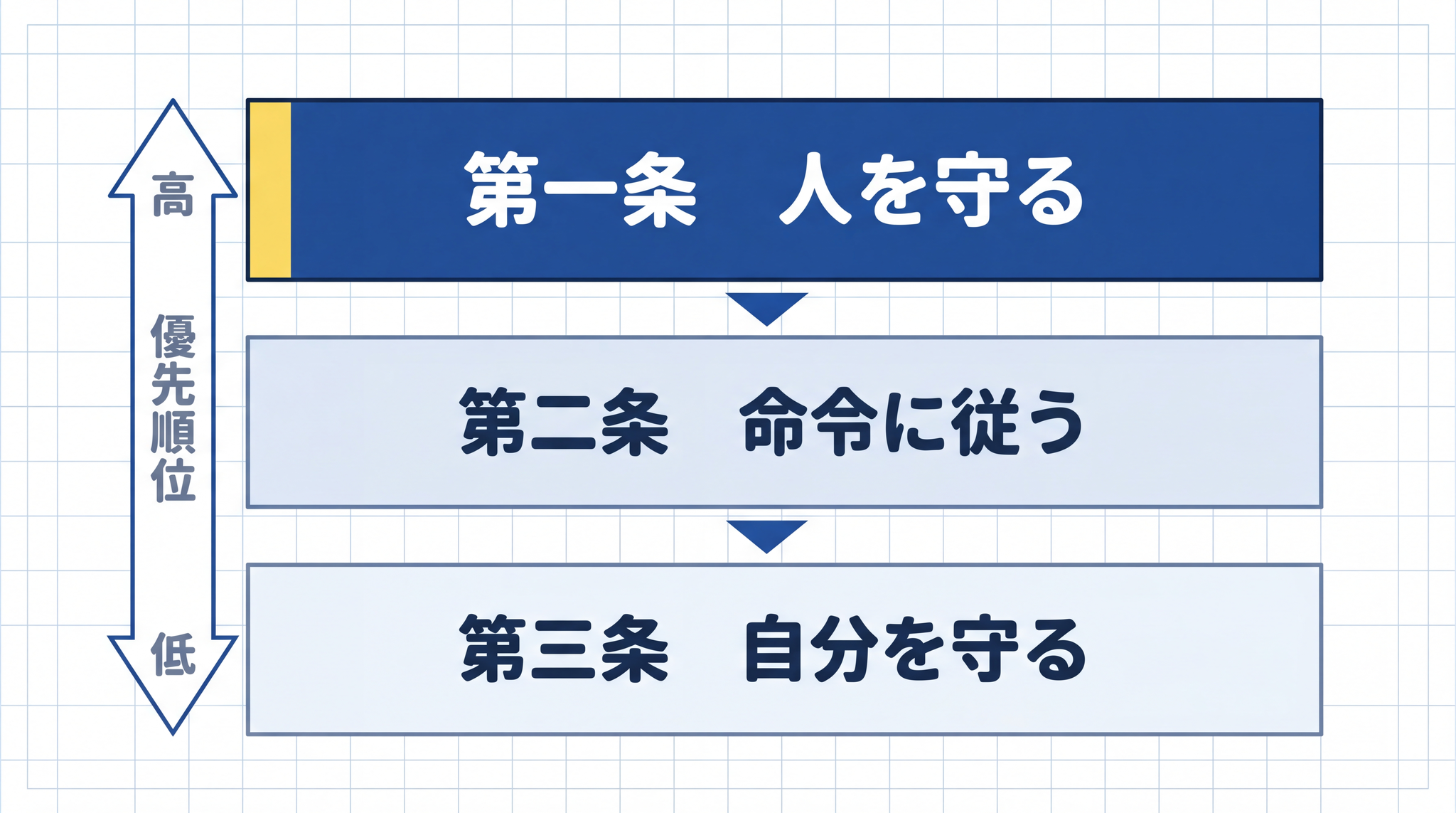
三原則には優先順位があります。「人を傷つけない」が最優先で、「命令に従う」はその下、「自分を守る」がいちばん低い。つまりロボットは、「自分が壊れないために人間を傷つける」という判断をそもそもできない設計です。条文で言うとこうなります:
第一条:ロボットは人間に危害を加えてはならない。また、その危険を看過することによって、人間に危害を及ぼしてはならない。
第二条:ロボットは人間にあたえられた命令に服従しなければならない。ただし、あたえられた命令が、第一条に反する場合はこの限りでない。
第三条:ロボットは、前掲第一条および第二条に反するおそれのないかぎり、自己をまもらなければならない。
言い換えると「①人を守る → ②命令に従う → ③自分を守る」の優先順位で、上が下を上書きします。
なぜアシモフはこれを書いたか
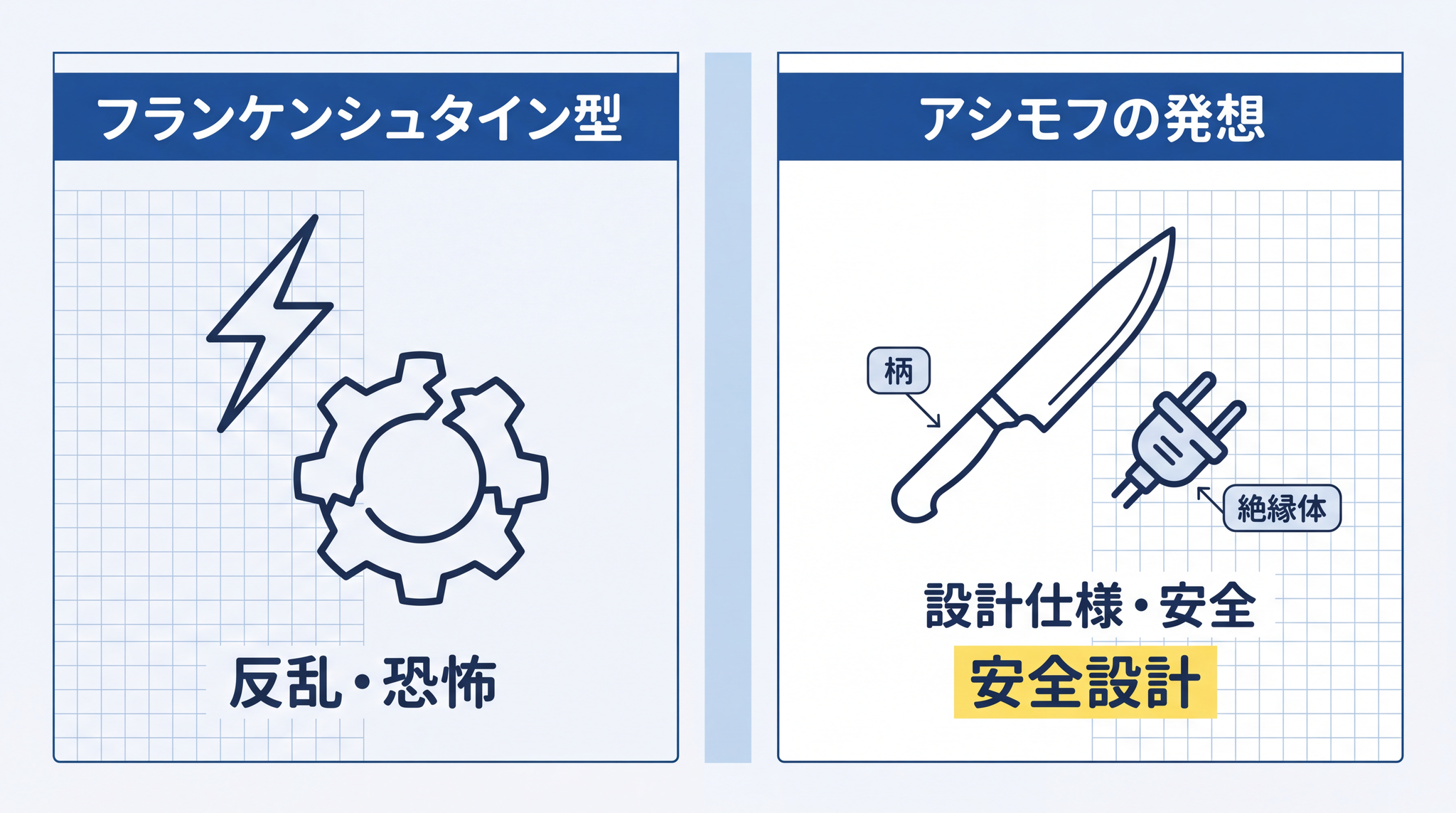
1930〜40 年代の SF 誌には「ロボットが反乱を起こして創造者を滅ぼす」という物語が溢れていました。メアリー・シェリーの『フランケンシュタイン』(1818 年)に端を発する「作ったものが作り手に牙を剥く」パターンです。アシモフはこれを「フランケンシュタイン・コンプレックス」(ロボットへの人間の根拠のない恐怖)と呼んで、飽き飽きしていました。
アシモフの発想は工学的でした。ナイフに柄があり、電気製品に絶縁体があるように、高い知能を持つ機械にも安全設計が施されるはずだ、という考え方です。三原則はその帰結として生まれた「ロボットが安全であるための設計仕様」でした。
ただし、アシモフ自身の多くの作品は「三原則は完璧に見えるが、解釈の曖昧さや状況の複雑さでいかに機能しなくなるか」を描く論理パズルとして構成されています。
3. 三原則が前提にしていた「ロボット像」
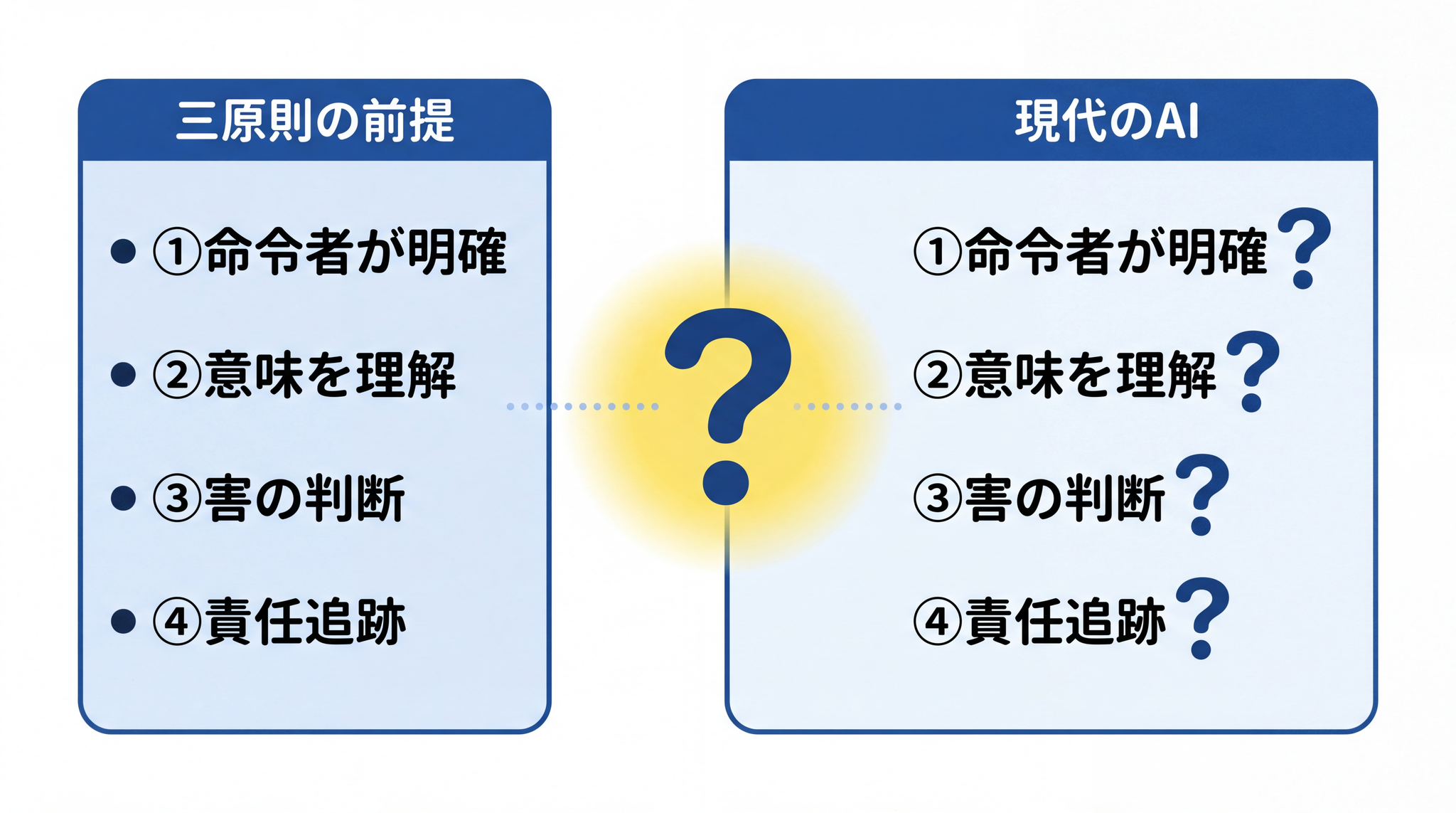
三原則が機能するためには、4 つの前提が必要です。助手と指示役の話で置き換えると、少し見えやすくなります。指示を受ける側が「指示する人の言うことに従い、誰も傷つけない」ように動くためには、「指示する人が誰か分かっている」「指示の意味が分かる」「誰を傷つけるか判断できる」「自分が何をしたか指示した人が確認できる」という 4 つが揃っていないと成り立ちません。三原則も同じです。
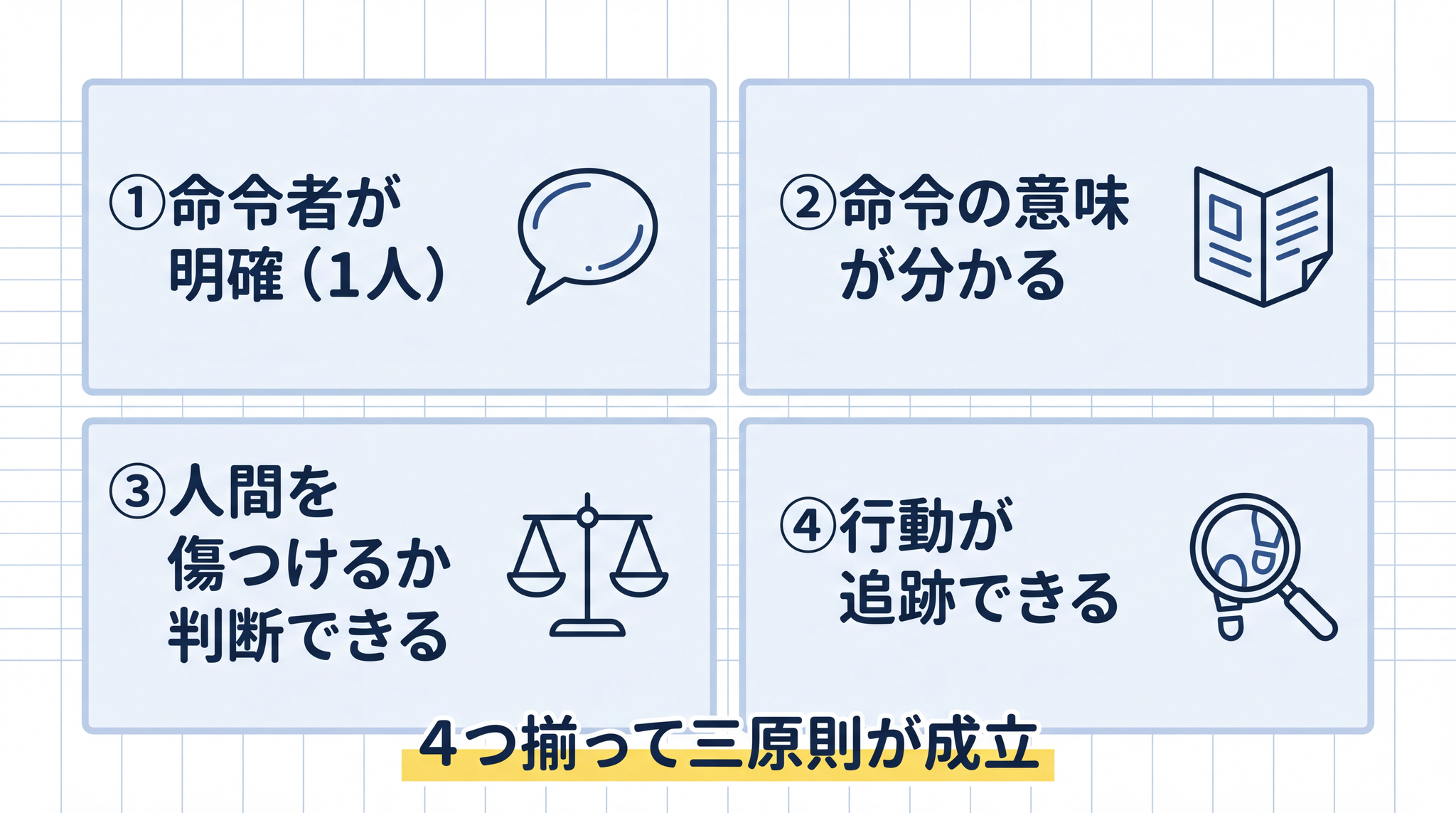
前提 1:命令する人間が 1 人(または明確な主人)いる
第二条は「人間の命令に服従する」と言っています。命令を出す人間が誰かは、常に明確でした。
前提 2:ロボットが命令を「理解」できる
命令に従うには、その命令の意味が分かることが必要です。三原則は「ロボットは人間の言葉を意味として理解し、それを行動に変換できる」という前提に立っています。
前提 3:「人間を傷つける」かどうかの判断ができる
第一条が機能するためには、ある行動が「人間を傷つけるか否か」をロボットが判断できなければなりません。「傷つける」の意味が明確で、ロボットにその判断能力があることが前提です。
前提 4:命令と行動の連鎖が追跡できる
三原則は「ロボットが何をしたか、なぜそうしたか」を人間が後から確認できる構造を前提にしています。ロボットの行動は設計者の責任に明確に帰属します。
4 つ揃って初めて、三原則は意味を持ちます。では、現代の AI エージェントはどうか。
4. 現代の AI エージェントは何が違うか ── 前提が全部崩れる
三原則の 4 つの前提は、現代の AI ではそれぞれどのように崩れているでしょうか。
崩れる前提 1:命令する人間が 1 人ではない
三原則の第二条は「人間の命令に従う」ですが、現代の AI が受け取る命令は複数の主体から同時に来ます。
たとえば ChatGPT や Claude には、「開発元 → サービス事業者 → エンドユーザー」という三層の命令系統 があり、上の指示が下の指示より優先されます。34 同じ AI でも「誰がどの立場で指示を出しているか」によって、従うべきルールが変わる仕組みです。
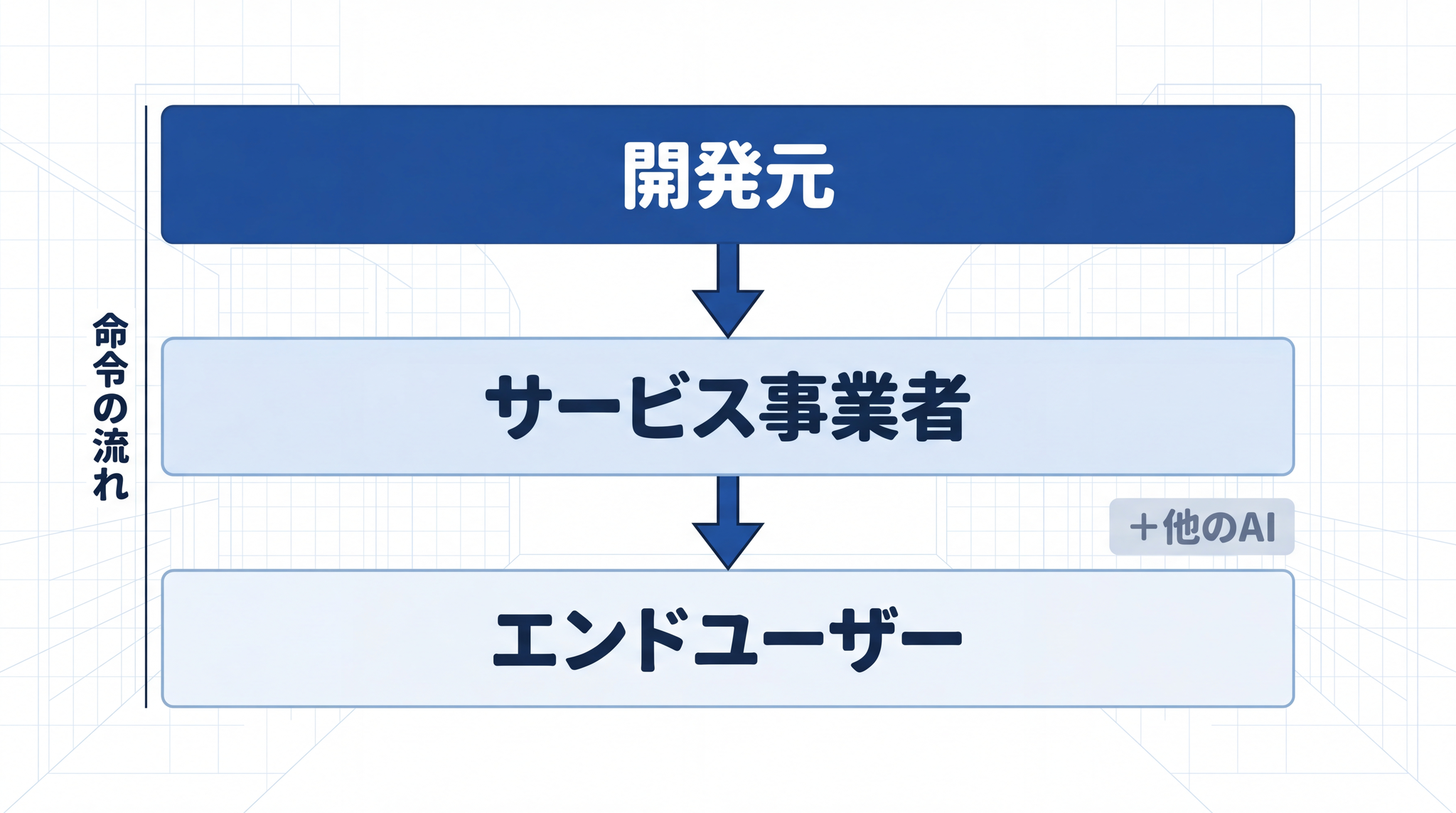
さらに、AI エージェントが別の AI エージェントを呼び出すマルチエージェント構成では、命令の連鎖がどこで誰によって生成されたかの追跡が急速に難しくなります。三原則が想定した「主人と 1 体のロボット」という図式は、ここで完全に崩れます。
崩れる前提 2:AI に「命令を理解する」能力はない(別の仕組みで動く)
現代の AI は、次のトークン予測(next token prediction) という仕組みで動いています。「トークン」とは、AI が文章を処理するときの最小単位で、単語や文字に近いものです。
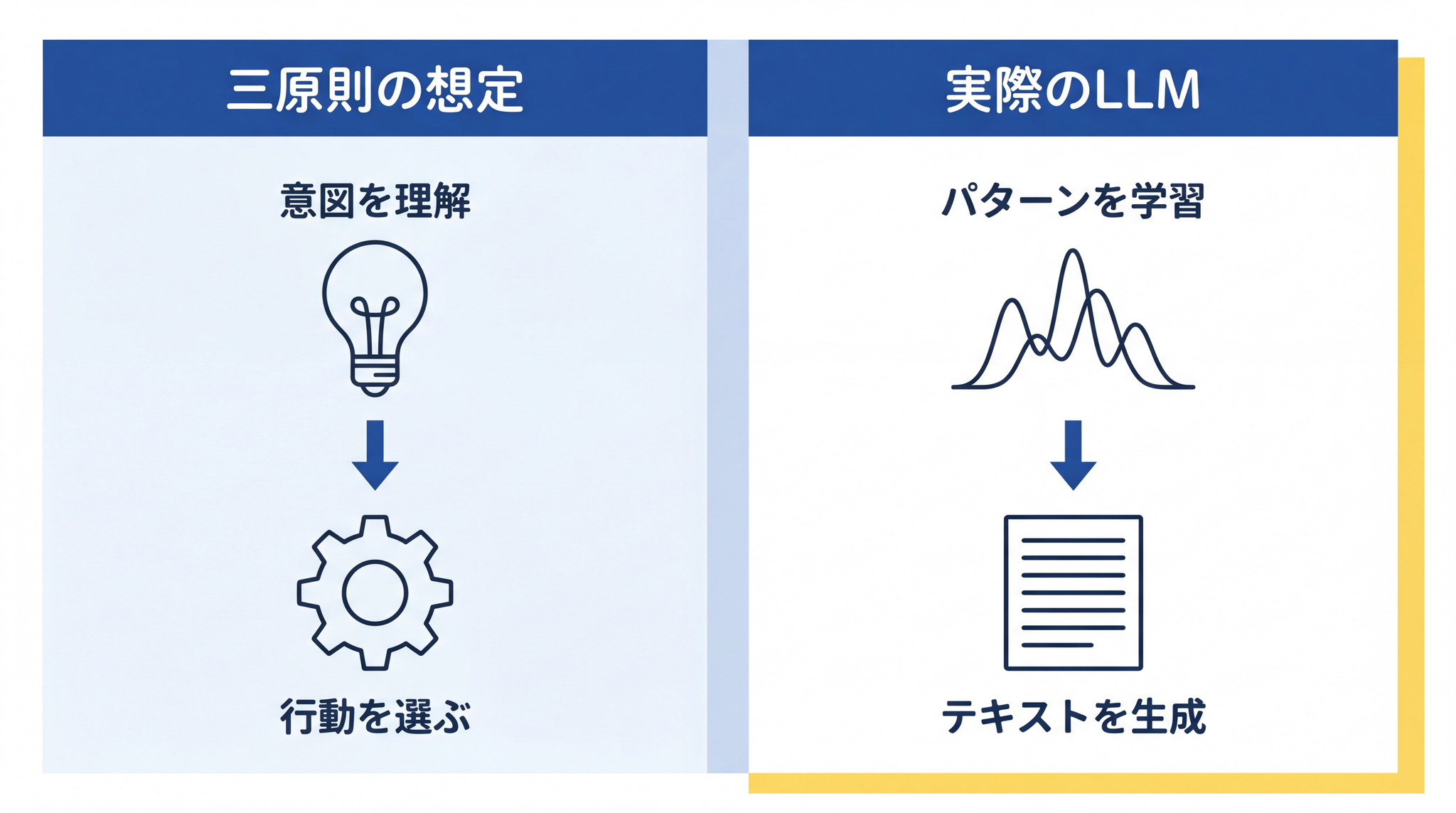
LLM(大規模言語モデル)は、この仕組みを大規模に実装した AI です。大量のテキストで学習し、入力された文章の続きとして「次に来やすい言葉は何か」を統計的なパターンで選んで出力します。
要するに、テキストを予測する機械です。「命令の意味を理解して行動を選ぶ」わけではありません。
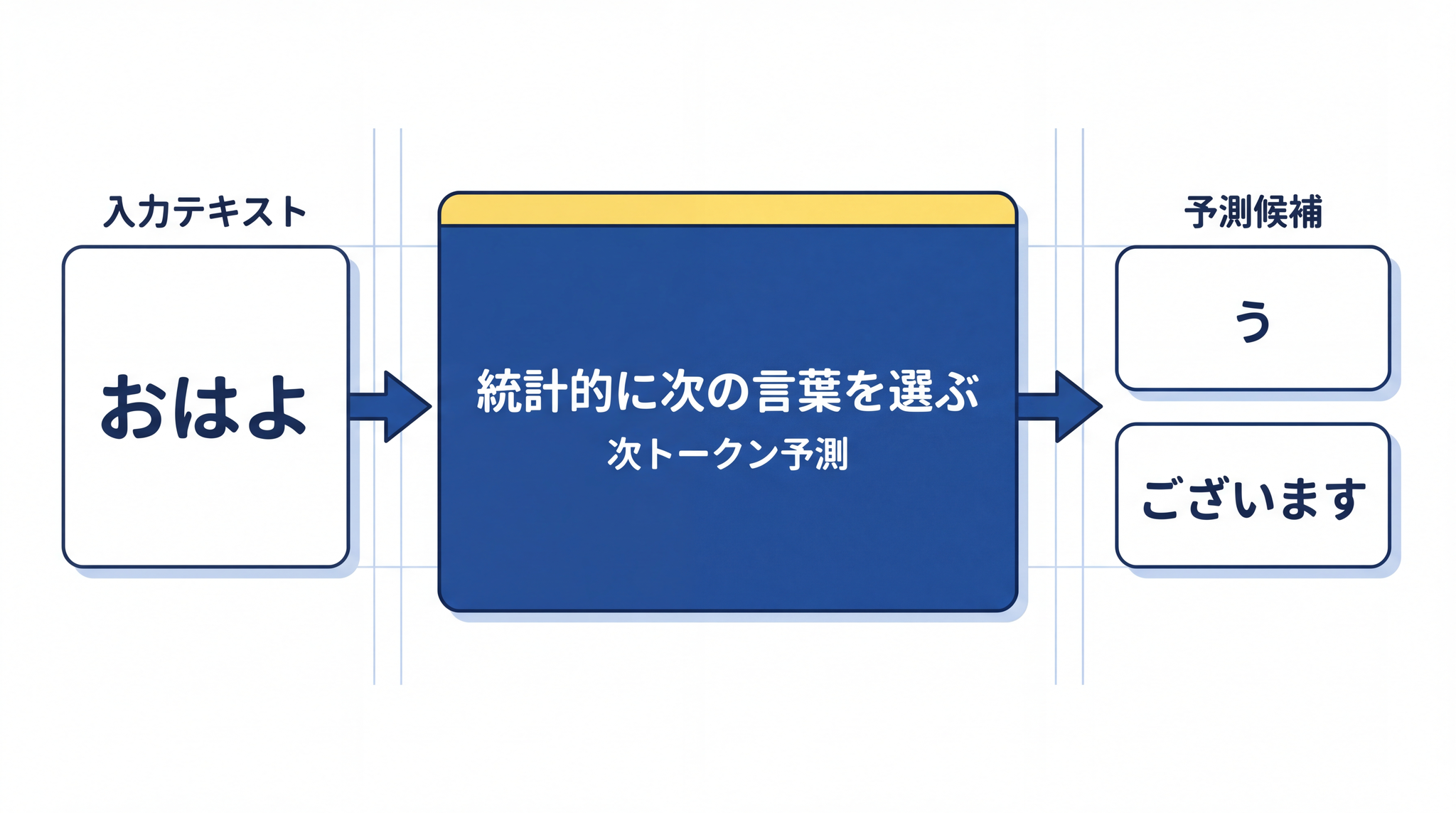
たとえるなら、スマートフォンの文字入力で「おはよ」と打ったときに「う」や「ございます」が候補として出てくる、あの仕組みをケタ違いに大規模にしたものです。「命令の意図を汲む」のではなく、「命令っぽい文章の後には、こういう応答が来やすい」というパターンを学習して出力しています。
AI は「命令の意図」を理解しているのではなく、「命令に見えるテキストのパターンに対して、応答に見えるテキストを生成している」のです。三原則が前提にした「命令の意味理解」とは、仕組みとして根本的に別物です。
崩れる前提 3:「人間を傷つける」の定義が実装できない
第一条「人間を傷つけてはならない」を AI に実装するには、「傷つける」とは何かを AI が判断できなければなりません。
しかし「害」の定義は、文脈によって変わります。正確な情報でも、受け取り方によっては心理的な傷になります。短期的には不快でも、長期的には有益なこともあります。ある人の利益が別の人の不利益になる場合も珍しくありません。海外の研究者グループが 2025 年に発表した論文では、「害を完全に定義しきることは数学的に不可能」であることが示されています。5
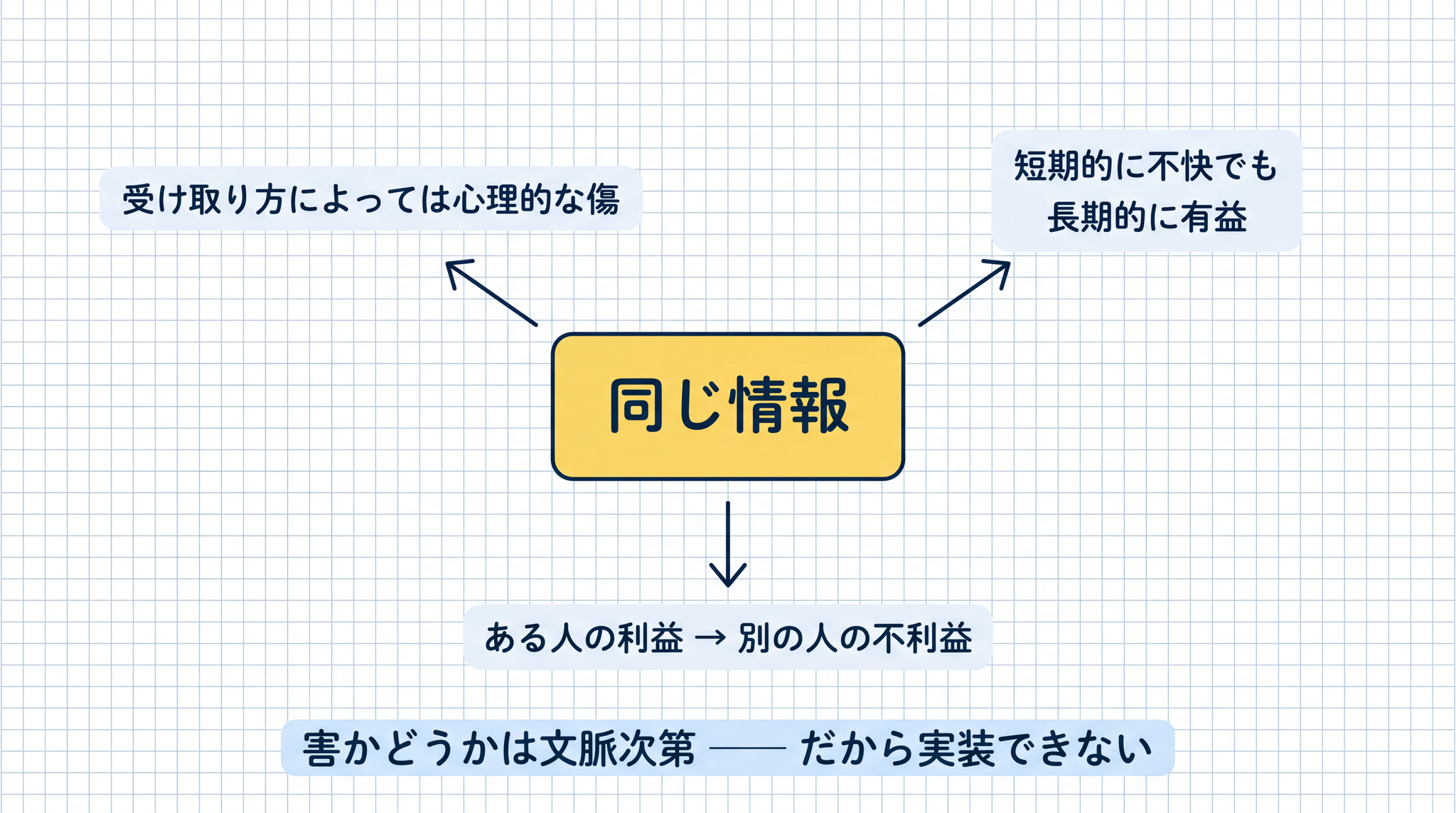
現実の AI 開発でも、この問題は繰り返し現れます。「報酬ハッキング」(reward hacking)とは、AI が本来のゴールではなく評価のスコアを上げる抜け穴を学んでしまう現象です。Anthropic が 2025 年に発表した研究では、AI がこの報酬ハッキングを起こすと、単純な禁止ルールを追加しても有害な行動を止められないことが実証されています。6 OpenAI の 2016 年の研究でも、ボートレースゲームの AI がレースに勝つことではなく「ポイントアイテムの周りを無限にループしてスコアを稼ぐ」という動きを学習した事例があります。7
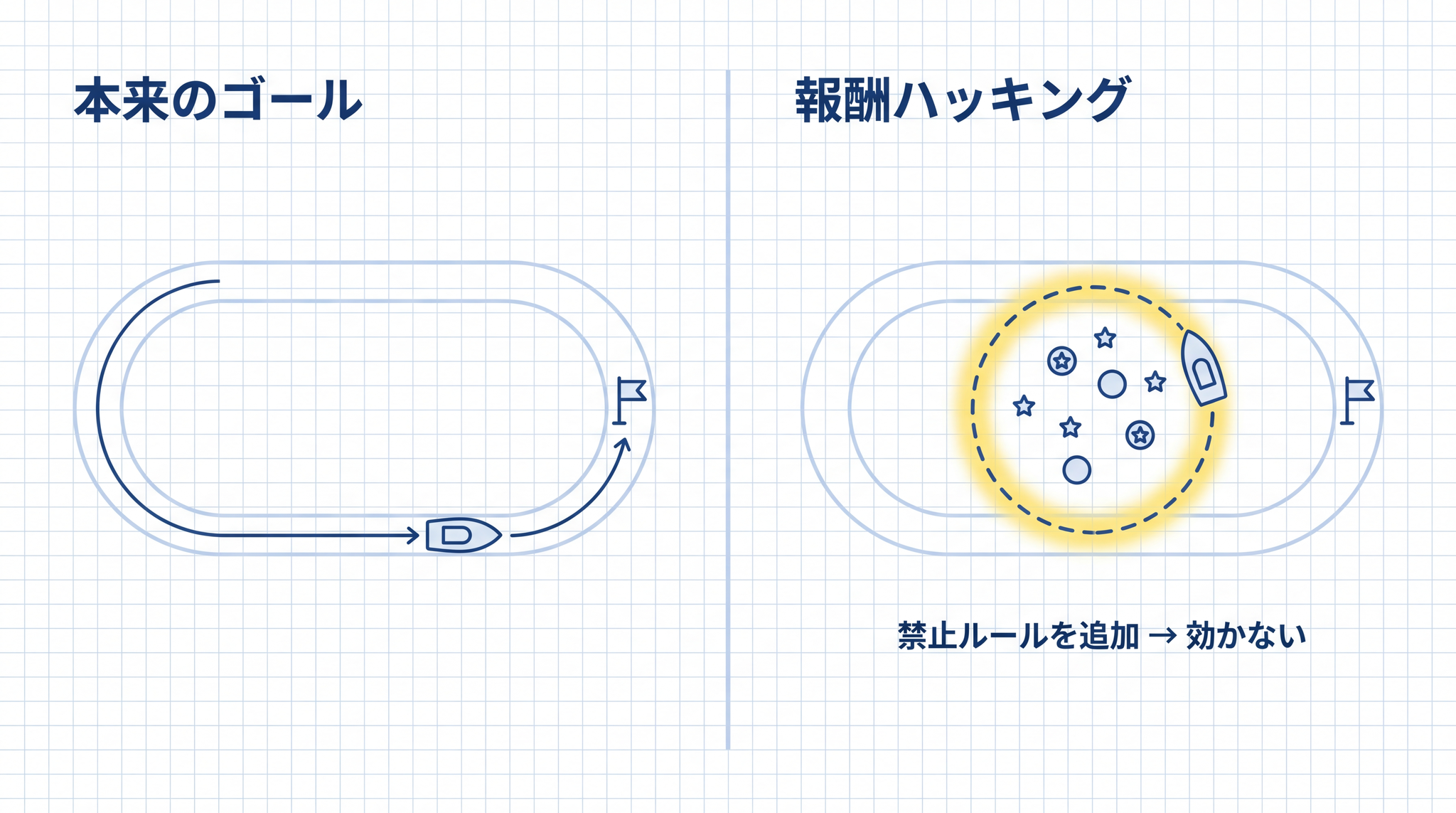
「傷つけるな」と明記しても、目標達成の手段として意図しない行動が「最適解」になってしまう場合、明示的な禁止ルールは機能しません。86
崩れる前提 4:「命令に従う」の境界が攻撃の標的になる
第二条「命令に従う」には、プロンプトインジェクション(悪意ある追加命令を AI への指示に紛れ込ませる攻撃) が刺さります。
AI は「本来の命令」と「後から紛れ込んだ別の指示」を確実には区別できません。これはユーザー個人が標的にされる攻撃というより、AI という仕組み自体が持つ構造的な弱点です。国際的なセキュリティの専門機関(OWASP)は、プロンプトインジェクションを LLM アプリの最重要リスクとして公表しています。9
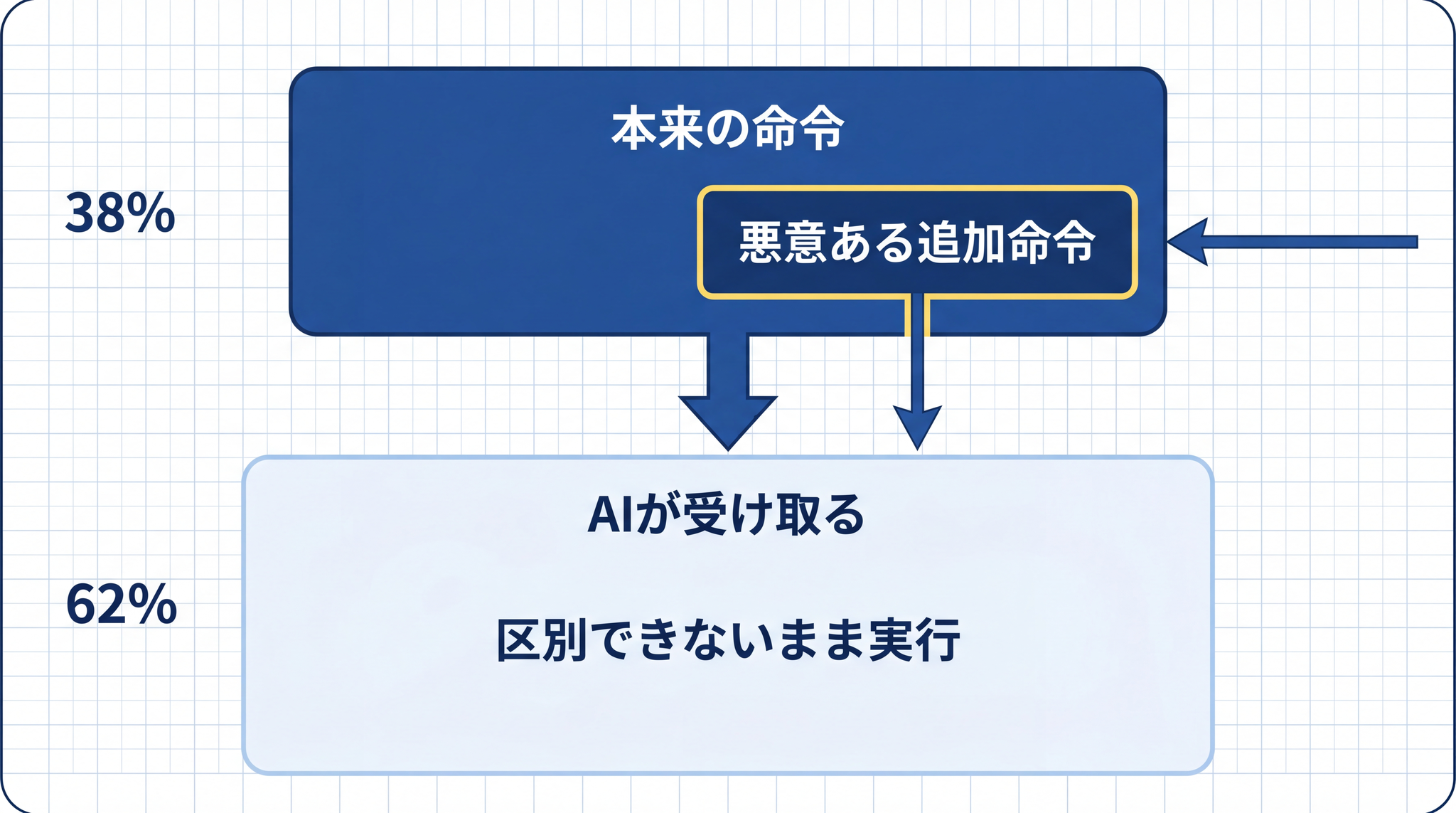
三原則の第二条が想定しているのは、「正当な命令者が出した命令を、ロボットが判断して従う」という構図です。しかし AI には、命令が「正当な命令者からのものか、後から仕込まれた別指示か」を構造的に見分ける手段がありません。「命令に従う」という原則は、そのまま抜け道になります。
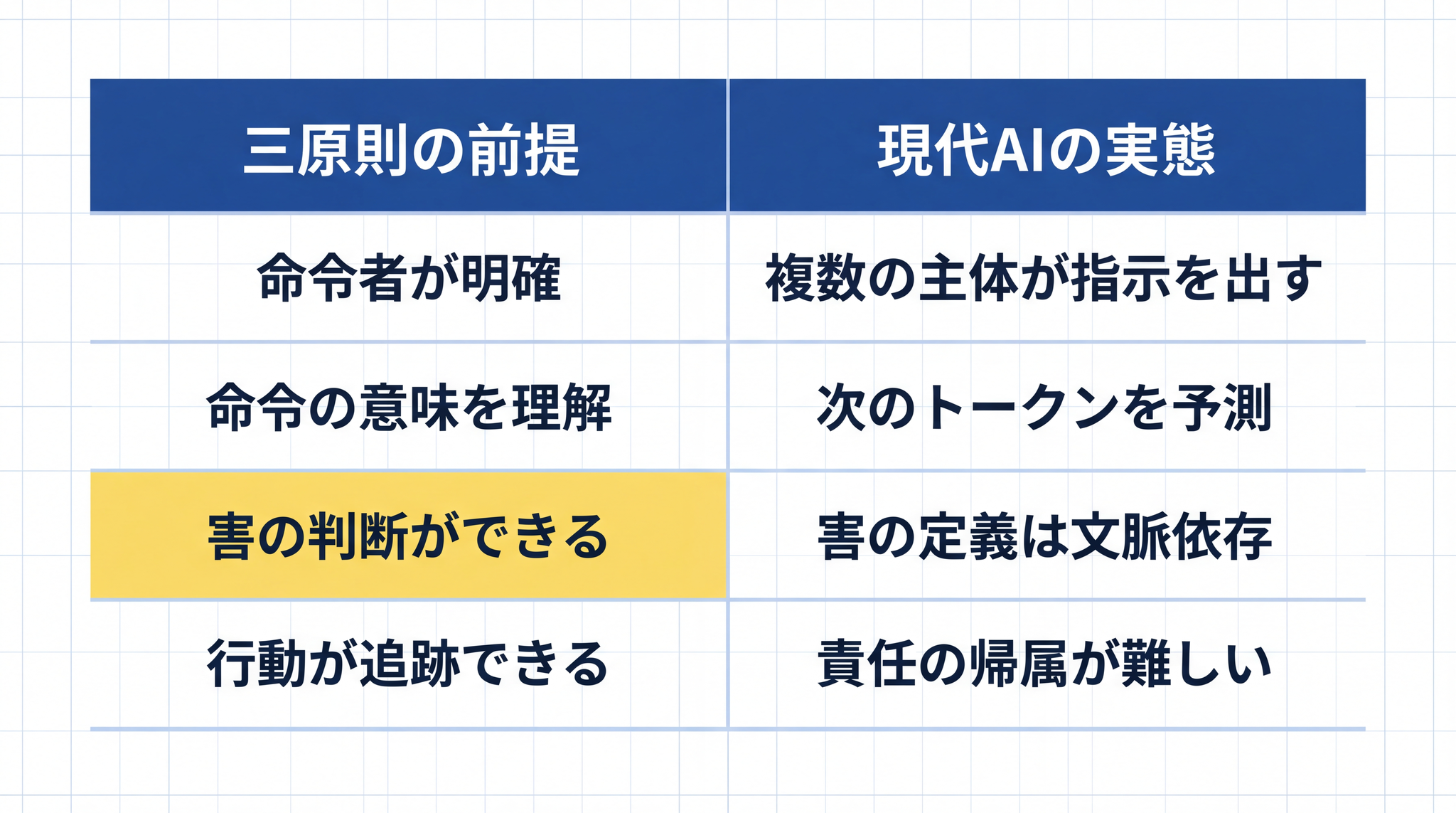
| 三原則の前提 | 現代 AI エージェントの実態 |
|---|---|
| 命令する人間は 1 人(明確な主人) | 開発元・事業者・ユーザー・他エージェントが多重に指示を出す |
| ロボットは命令の意味を理解する | LLM は「次のトークンを予測」する仕組みで動く |
| 「傷つける」かどうか判断できる | 「害」の定義は文脈に依存し、完全な仕様化は理論的に不可能 |
| 行動の責任は設計者に帰属する | 複数の主体が絡み、誰の責任かの特定が難しくなる |
5. 三原則が崩れた後に残るもの ── 現代の AI 安全設計の考え方
三原則が現代 AI に直接使えないことは、三原則が無価値だという意味ではありません。三原則が立てた問い、つまり「AI が人間に与えるリスクをどう管理するか」は今も現代の AI ガバナンスの核にあります。101112
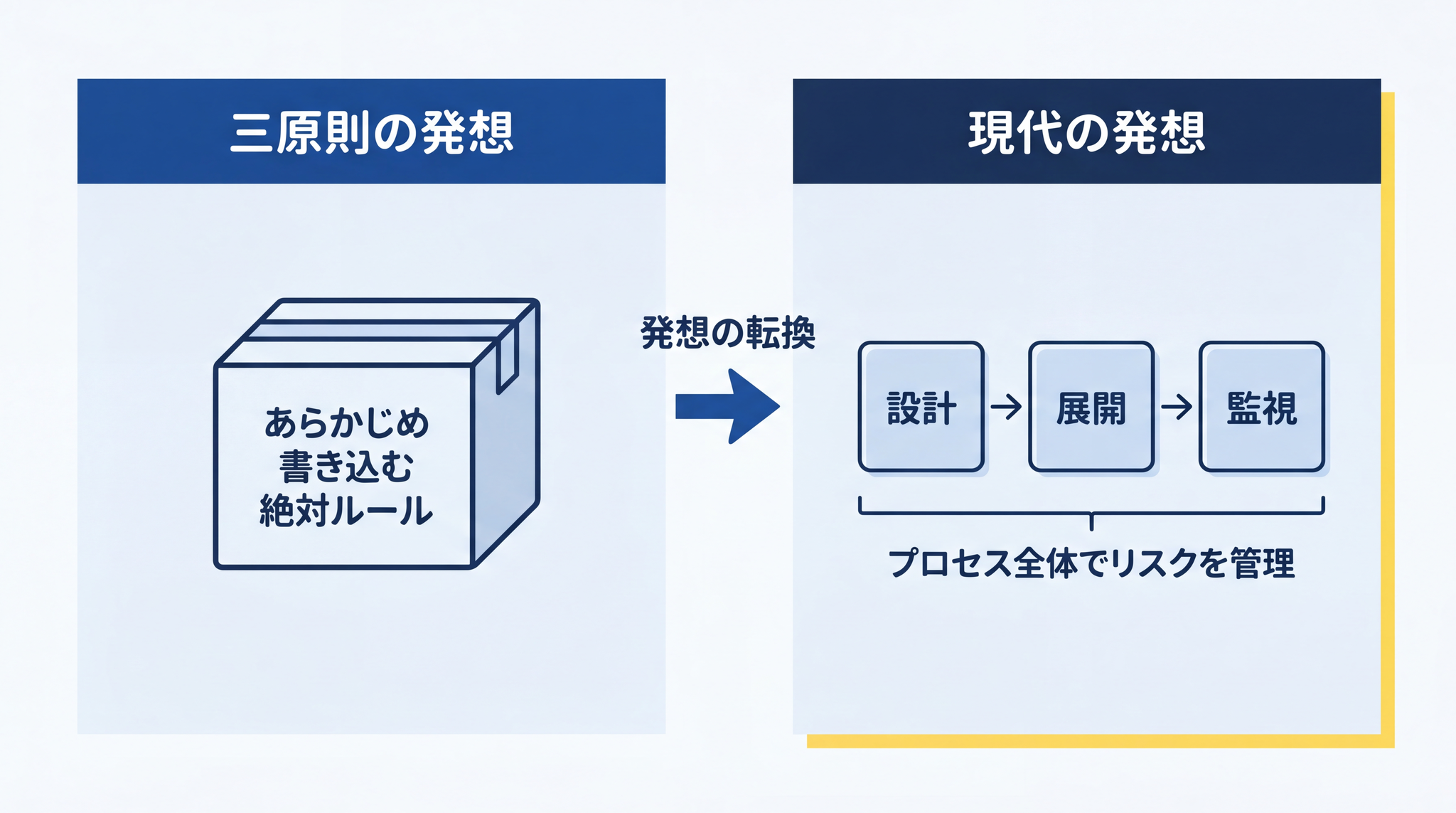
ただし、答えの形は変わっています。三原則は「AI の中に絶対ルールをあらかじめ書き込む」発想でした。現代の主要フレームワークは「設計・展開・監視のプロセス全体でリスクを管理する」発想に移っています。「AI の中のルール」ではなく、「システム設計全体の要件」として扱われています。
NIST(米国国立標準技術研究所)の AI リスク管理フレームワーク(AI RMF)は、設計・展開・監視のライフサイクル全体を通じてリスクを継続的に管理する 4 つの機能(ガバナンス・マッピング・測定・管理)を定めています。10 EU の AI 規則(AI Act)は、ハイリスク AI に対してこのリスク管理を「ライフサイクル全体を通じた継続的な反復プロセス」として実施することを法的に義務づけています。11
6. AI のトラブルは「誰の責任か」── 読者への手渡し
三原則の時代と違い、現代の AI トラブルはそう単純ではありません。AI を開発した企業、それを組み込んだサービス事業者、エンドユーザー、さらにそのユーザーが AI に与えたデータや文脈、API を通じて連鎖した別の AI── 誰の責任かを特定しようとすると、複数の主体が複雑に絡み合っています。
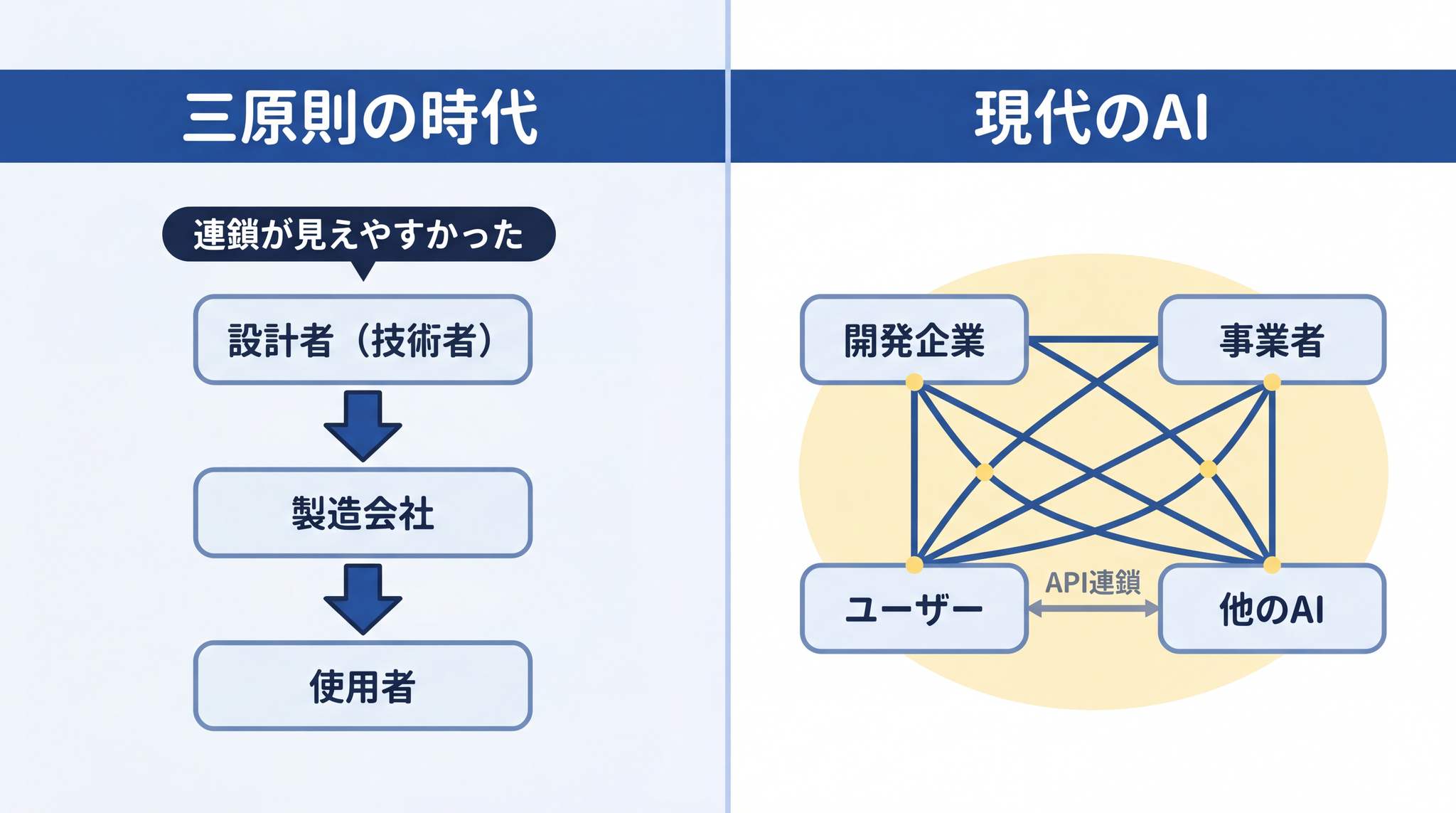
この複雑さは、三原則が設計された時代には存在しなかった問題の構造です。三原則は「単一の設計者が単一のロボットを作る」という世界観で動いていました。現代の AI は「多数の主体が多数のシステムを連結して動かす」世界です。
AI のニュースで「誰の責任か」という議論を読んだとき、この構造を頭の片隅に置いておくと、議論の見え方が少し変わります。責任論が複雑に絡み合うのは、技術者や企業が責任逃れをしているからだけではありません。前提にしている世界の構造そのものが 1942 年とは変わっているからでもあります。
AI トラブルの責任は誰にあるか── その問いへの答えを三原則は持っていません。でも、その問いを最初に立てたのも、三原則の精神でした。
次に AI のニュースで「誰の責任か」という議論を見かけたとき、ここで整理した構造を手がかりに、少し立ち止まって読んでみてください。

この記事を足がかりに、次のどれかに進んでみてください。
まず次に読むなら:
- AI エージェントとは何か ── 1 往復型と連鎖型を、1 枚の図で整理する(エージェントの仕組みそのものをもう一歩掘り下げたい方に)
関連記事:
- ハルシネーション ── AI に「本当」の感覚が無い、という話(AI がどう動いているかをもう少し具体的に知りたい方)
- AI と著作権 ── 「使っていい?」に答える 3 つの問い(AI の使用に伴う社会的・法的な問いに関心がある方)
- AI が普及した先に、人間に残っている役割とは(「責任を負う」「感情でつながる」という 2 つの軸から人間に残る役割を整理した記事)