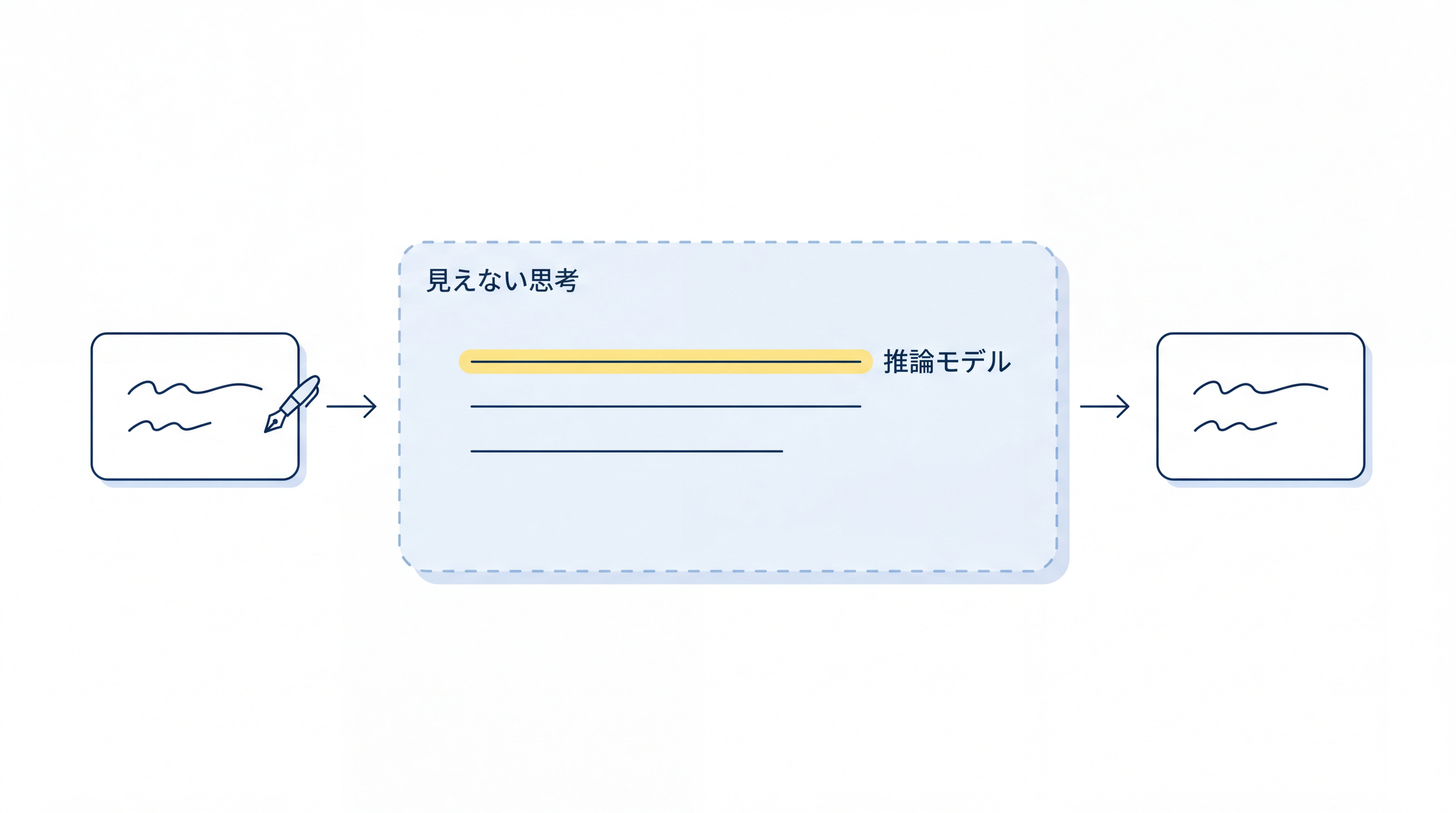
推論モデルとは ── 自分で考えてから答える AI の仕組みと使い方
目次
o3、Gemini 2.5 Pro、Claude Extended Thinking ── これらの名前を知っていても、「普通の ChatGPT と何が違うのか」と聞かれるとうまく説明できない。そんな状態で使っている方は、決して少数派ではないと思います。
一つだけ、見落としやすい話をしておきます。推論モデルを使うとき、プロンプトに細かい手順を書き込むと 逆効果 になります。推論モデルは、答えを出す前に自分で考えの筋道を組み立てる設計になっています。そこに外から「ステップ 1 はこれ、ステップ 2 はこれ」と手順を押し込むと、AI の内側の思考を邪魔してしまうのです。
この記事では、推論モデルが何者か・どのくらいの能力水準にあるか・どう使うべきかを整理します。
1. 使っているのに仕組みが見えない
2026 年現在、推論モデルはすでに日常的に使われています。でも「何が違うのか」という説明は、断片的な情報のまま広がっています。名前を知っていて、使い始めてもいる。それなのに仕組みが分からないのは、情報が整理されていないからです。
「ステップ 1:〜、ステップ 2:〜」のように 考え方の手順まで細かく指定する書き方 は、推論モデルでは逆効果になります。推論モデルは答えを出す前に内部で考えの道筋を組み立てるので、外から手順を押し込むとその思考と干渉します。なぜそうなるのか、§6 で詳しく扱います。
ここでの「推論」は、答えを出す前に考えの手順を自分で積み上げることを指します。機械学習の「推論(inference)」とは別の意味です。
2. 普通の AI と推論モデル ── 何が根本的に違うのか
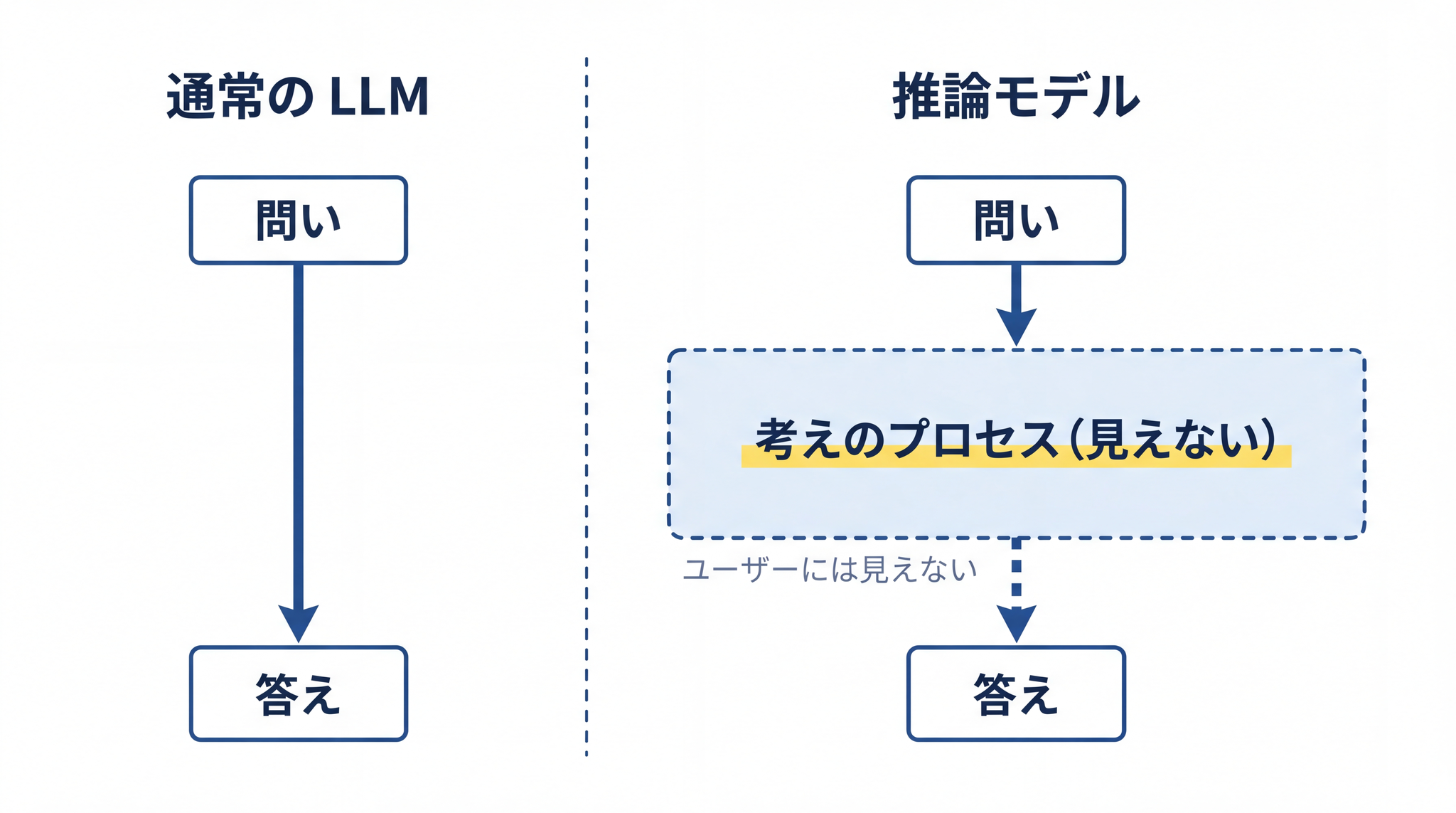
通常の LLM(大規模言語モデル。ChatGPT・Claude・Gemini などの AI の中身)は、「LLM の仕組み」で整理した通り、次の言葉を確率で選ぶことを繰り返して答えを出します。
推論モデルも、最終的には同じ仕組みで動いています。 違いは、答えが出てくるまでのプロセスにあります。推論モデルは、答えを出す 前 に、見えないところで考えのプロセスを自分で積み上げてから出力します。
| 通常の LLM | 推論モデル | |
|---|---|---|
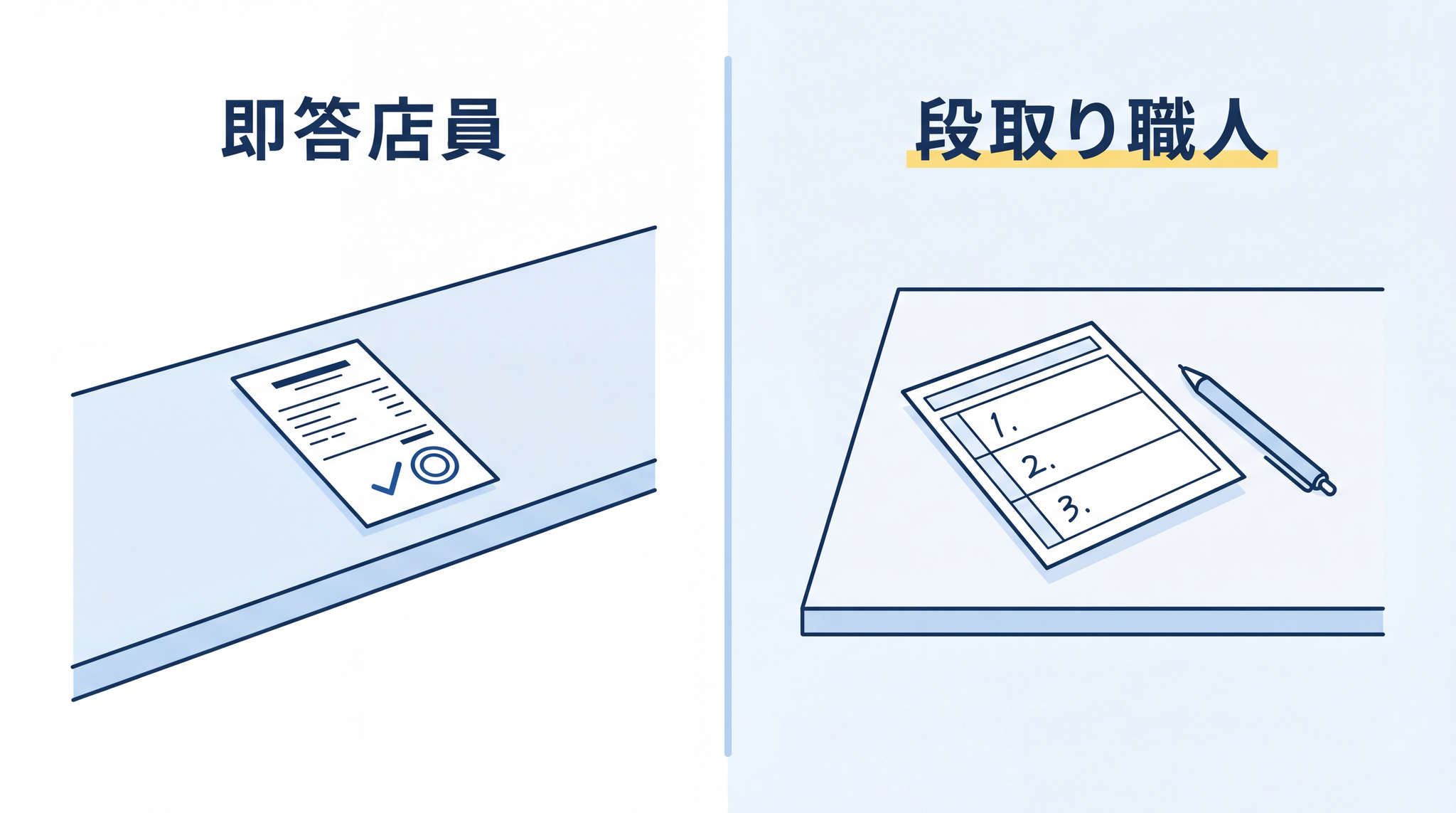
| 動き方 | 問いを受け取って即座に答えを組み立て始める | まず見えないところで考えの道筋を組み立ててから答える |
| イメージ | 一問一答で即答するアルバイト店員 | 段取りを確認してから動く職人 |
| 答えが出るまでの時間 | 速い | 遅い(考える時間がかかる) |
| 向いているタスク | 単純な質問・要約・翻訳・軽い対話 | 数学・論理・計画・複数条件が絡む問い |
OpenAI はこの「考える時間」を、入力・出力トークン(トークン=AI が文章を細かく区切って処理する単位)に加えて 推論トークン を導入し、それを使ってプロンプトを分解し、複数のアプローチを検討する仕組みだと説明しています1。
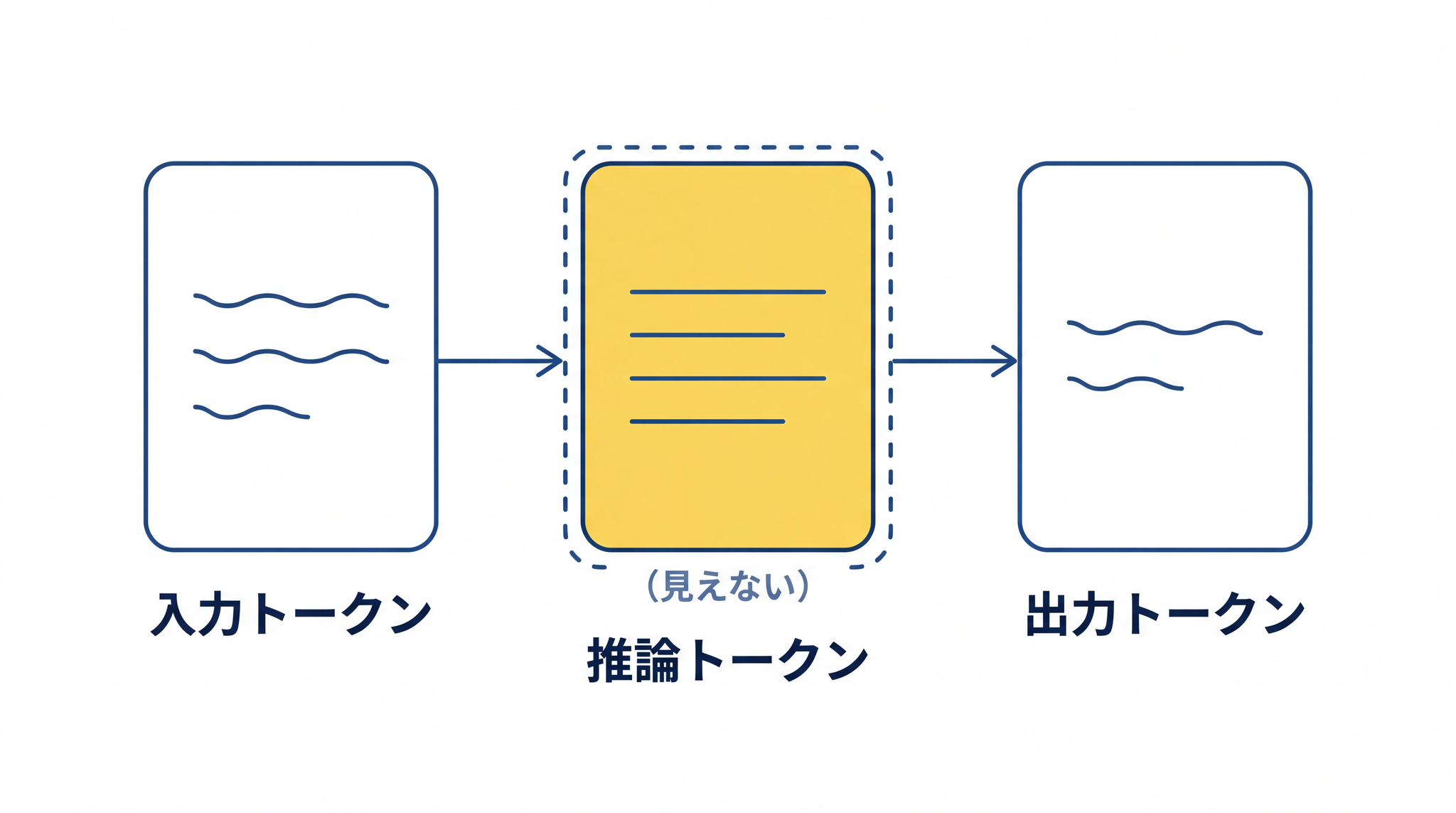
3. 推論モデルはどうやって「考える」のか
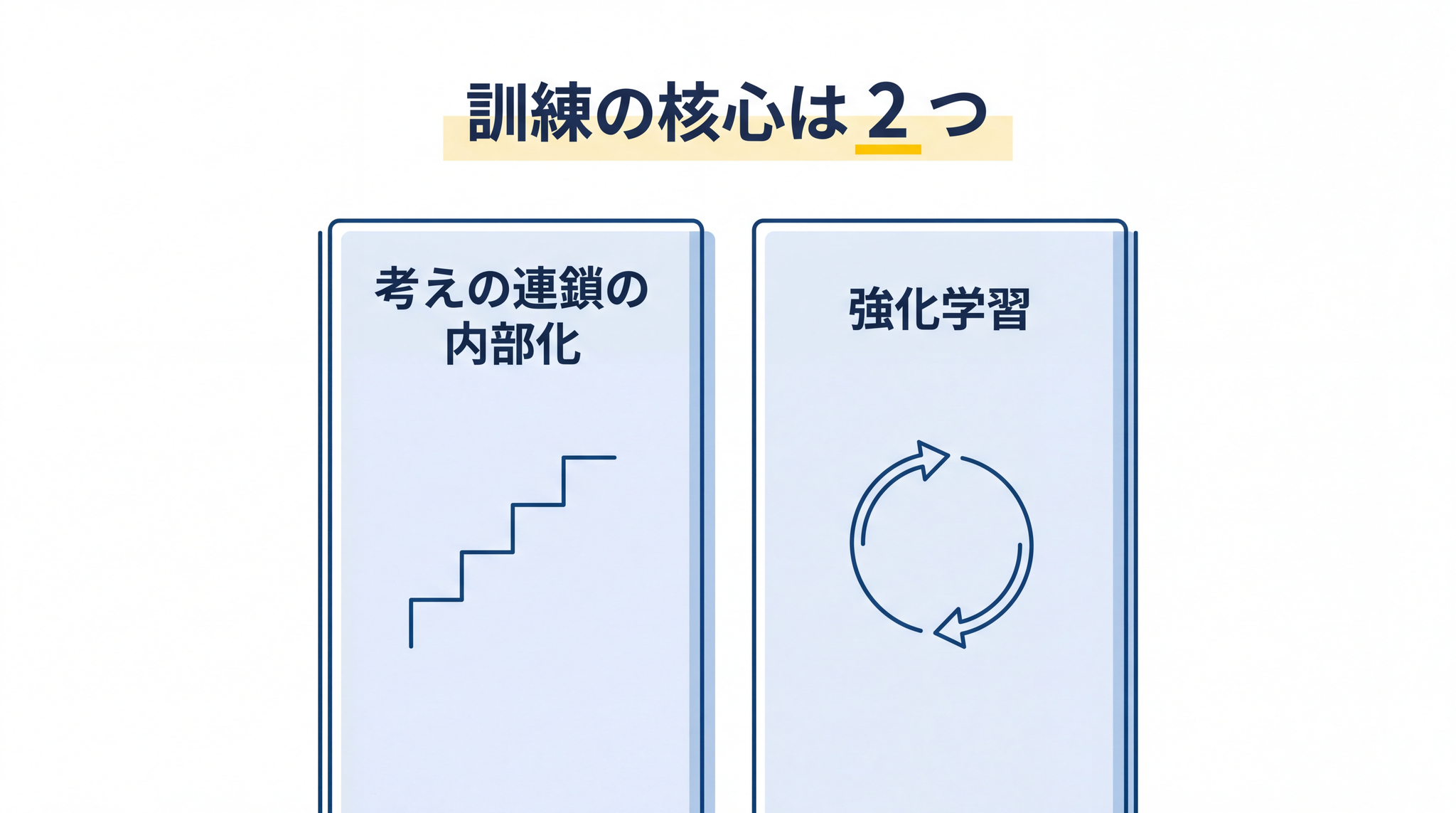
訓練の核心は 2 つです。
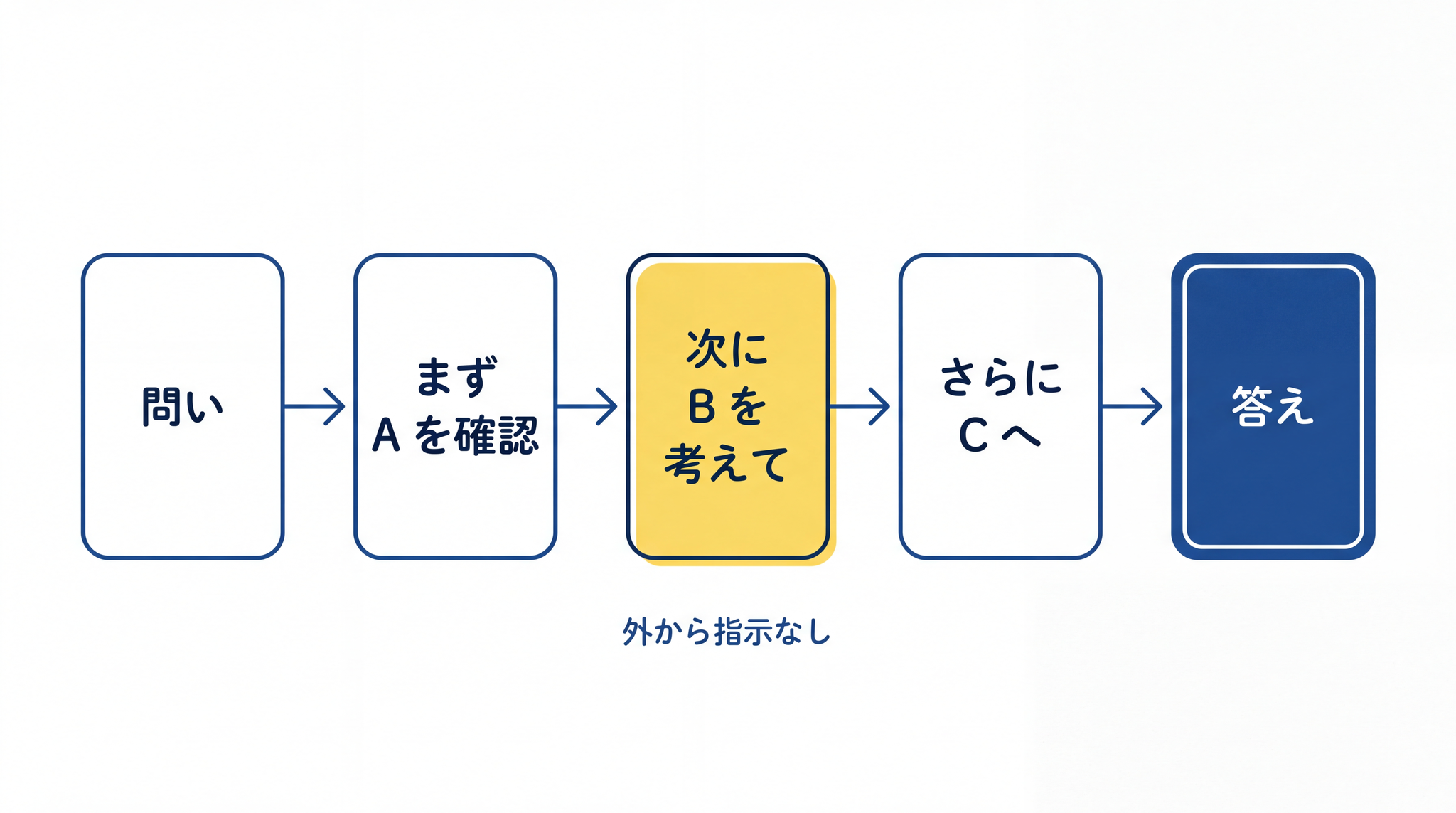
考えの連鎖の内部化:「まず A を確認して、次に B を考えて……」という思考の流れを、外から指示しなくても自動で展開できるよう、訓練の中に織り込まれています。「ステップバイステップで考えなさい」と人間が命令しなくても、モデルが自分でやります。
強化学習による訓練:正しい考え方の道筋をたどれば報酬が与えられ、間違った道筋にはマイナスの評価が返る。繰り返すことで、モデルは考え方を自分で磨いていきます。ちょうど、問題を解くたびに「そのやり方は正解・不正解」と教えてもらいながら上達していくイメージです。OpenAI も公式に、強化学習を通じて推論モデルが自分の考えの道筋を磨き、ミスを認識して修正し、難しいステップを単純なものに分解できるようになると説明しています2。
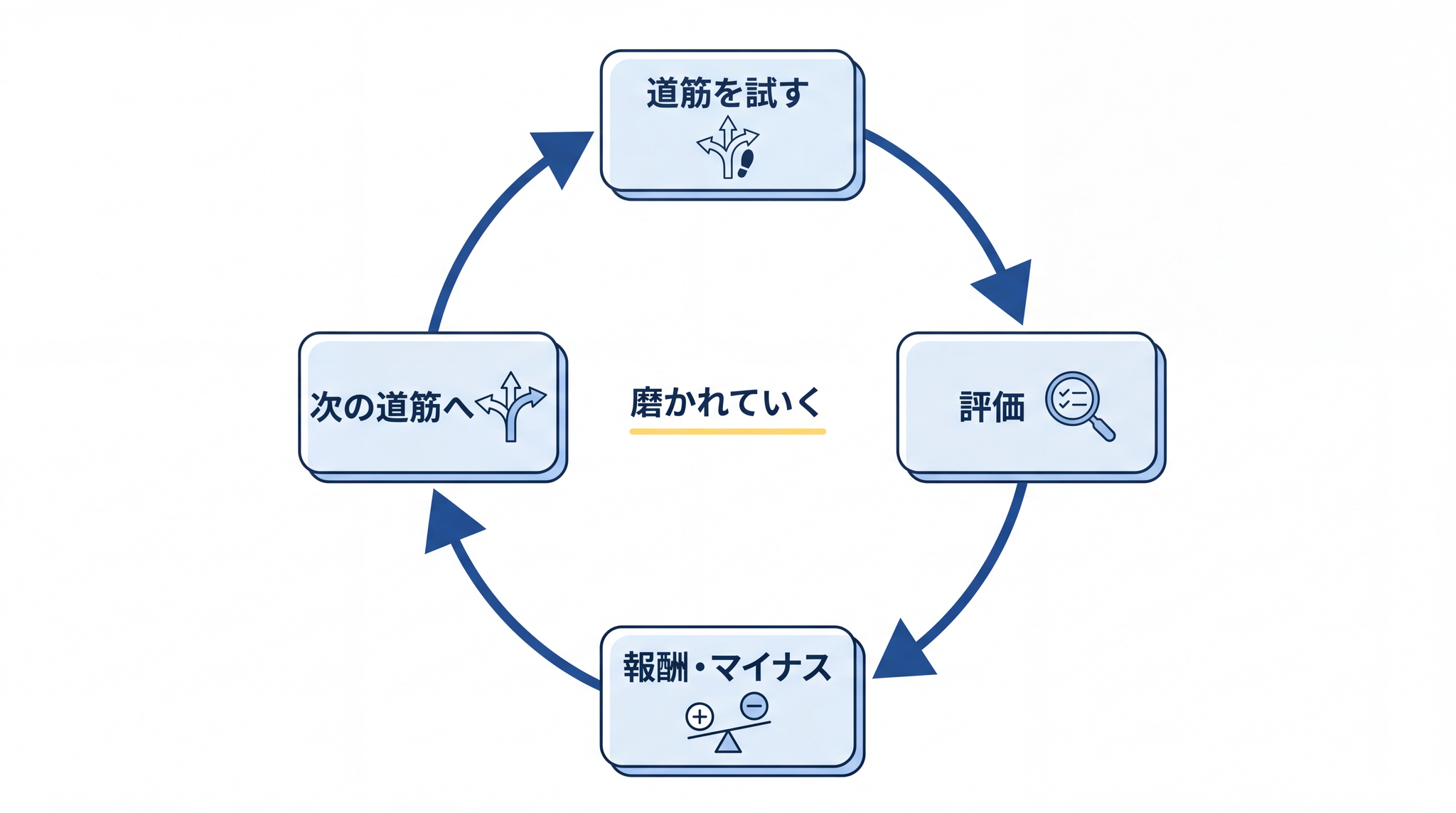
この 2 つが組み合わさることで、「難しい問いに対して、より長く考え、より正確な答えを出す」動作が実現しています。考える時間(計算量)を増やすほど性能が上がる性質があります。難しい問いほど、時間をかける価値があるわけです。
4. 人間で言うとどのくらい頭が良いのか
「博士レベルを超えた」「数学オリンピックで金メダル」── これらは誇張ではありません。主要なベンチマーク(性能を測るテスト。人間も同じ問題を解いて比べます)の結果を、「人間の何パーセンタイルに相当するか」という相対水準で見てみます。
| 分野 | ベンチマーク名 | 対象とする人間の水準 |
|---|---|---|
| 数学 | AIME(全米数学招待試験) | 全国上位 5%(招待制) |
| 専門知識 | GPQA Diamond | 博士課程レベル |
| プログラミング | Codeforces | 競技プログラマー世界トップ層 |
| 数学(最高峰) | IMO(国際数学オリンピック) | 金メダル水準 |
| 総合難問 | HLE(人類最後の試験) | 世界の専門家集団が設計 |
| 数学本選 | USAMO(全米数学オリンピック本選) | 全国選抜 |
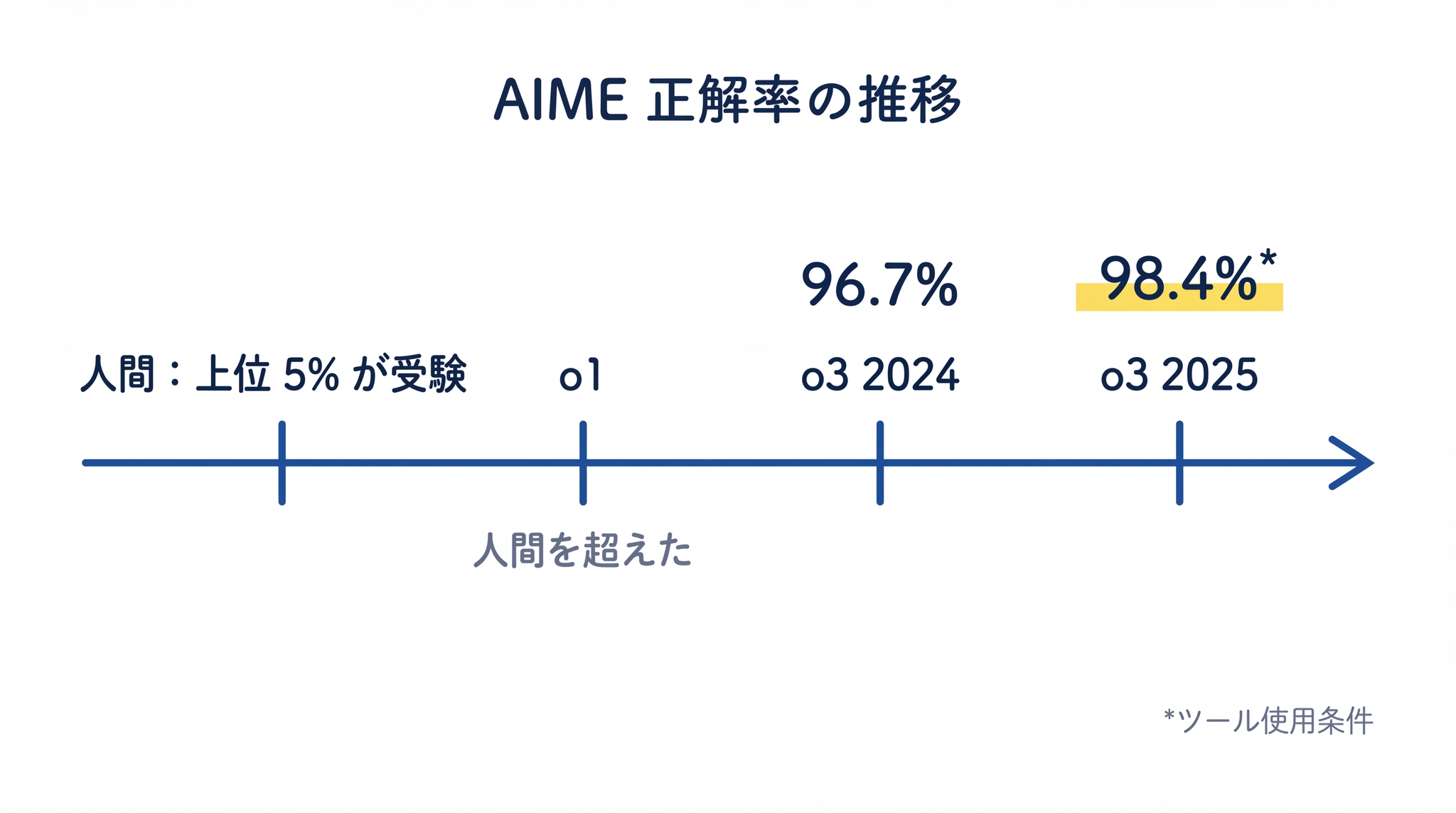
AIME ── 全米数学招待試験(アメリカの数学オリンピック予選):上位 5% だけが受験できる招待制の試験です。OpenAI は o1 の発表時点で「全米数学オリンピック予選〈AIME〉で全国上位 500 人レベルに位置する」と公表しました2。
o3 ではさらに性能が上がりました。AIME 2024 で 96.7% の正解率を記録し、2025 年の試験ではツールを使った条件で 98.4% に達しています3。招待制の試験で上位 5% だけが受験できる問題を、ほぼ全問正解できる水準です。
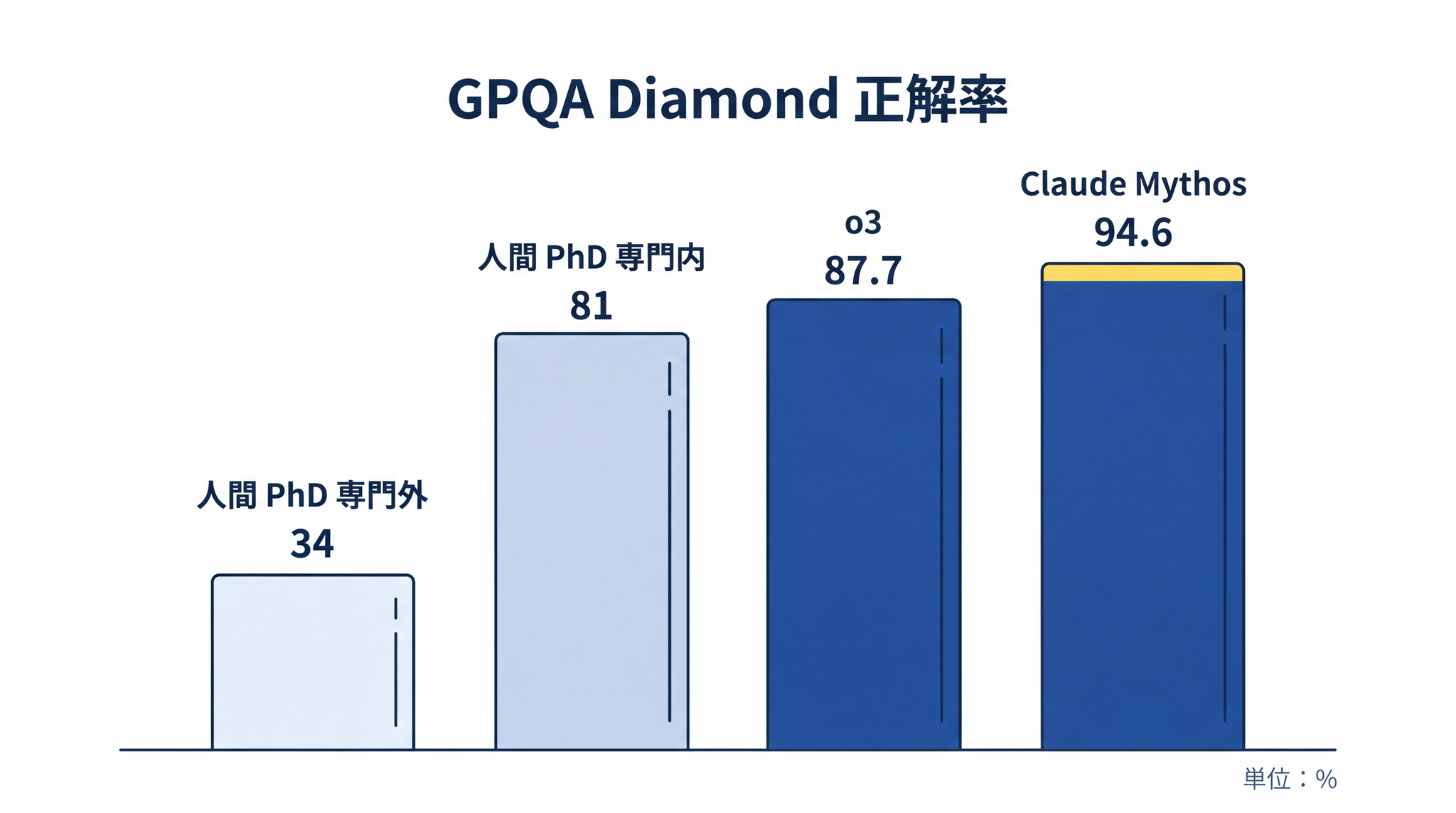
GPQA Diamond ── 博士課程レベルの専門問題集:生物・物理・化学の博士課程レベルの問題集で、「ネット検索でも解けない」を設計条件とした 198 問のセットです。OpenAI は o1 の発表時点で「物理・生物・化学の問題ベンチマーク〈GPQA〉において 人間の博士レベルの正解率を超えた (exceeds human PhD-level accuracy)」と公表しました2。
これは o1 の発表時の公式表現 です。博士号を持つ専門家でも、専門外の問題では 34% 程度しか解けず、専門内でも 81% 前後が上限です3。推論モデルはその水準を上回っています。
OpenAI の o3 はこのテストで 87.7% を達成し3、Anthropic の最新推論モデル Claude Mythos(クロード・ミュートス。Anthropic が研究者向けに限定公開している最新モデル)は 94.6% を記録しています4。
Codeforces ── 競技プログラミングの世界大会:将棋やチェスのように、Elo レーティング(強さを数値で表す仕組み)で人間参加者と直接比較できます。OpenAI の公式発表によると、o3 は Elo レーティング 2706 を達成しました3。世界の競技プログラマーの上位 0.2%(99.8 パーセンタイル)、世界ランキング上位 200 人水準に相当します。ただし「最高位の人間選手にはまだ及ばない」とも公式に明記されています。
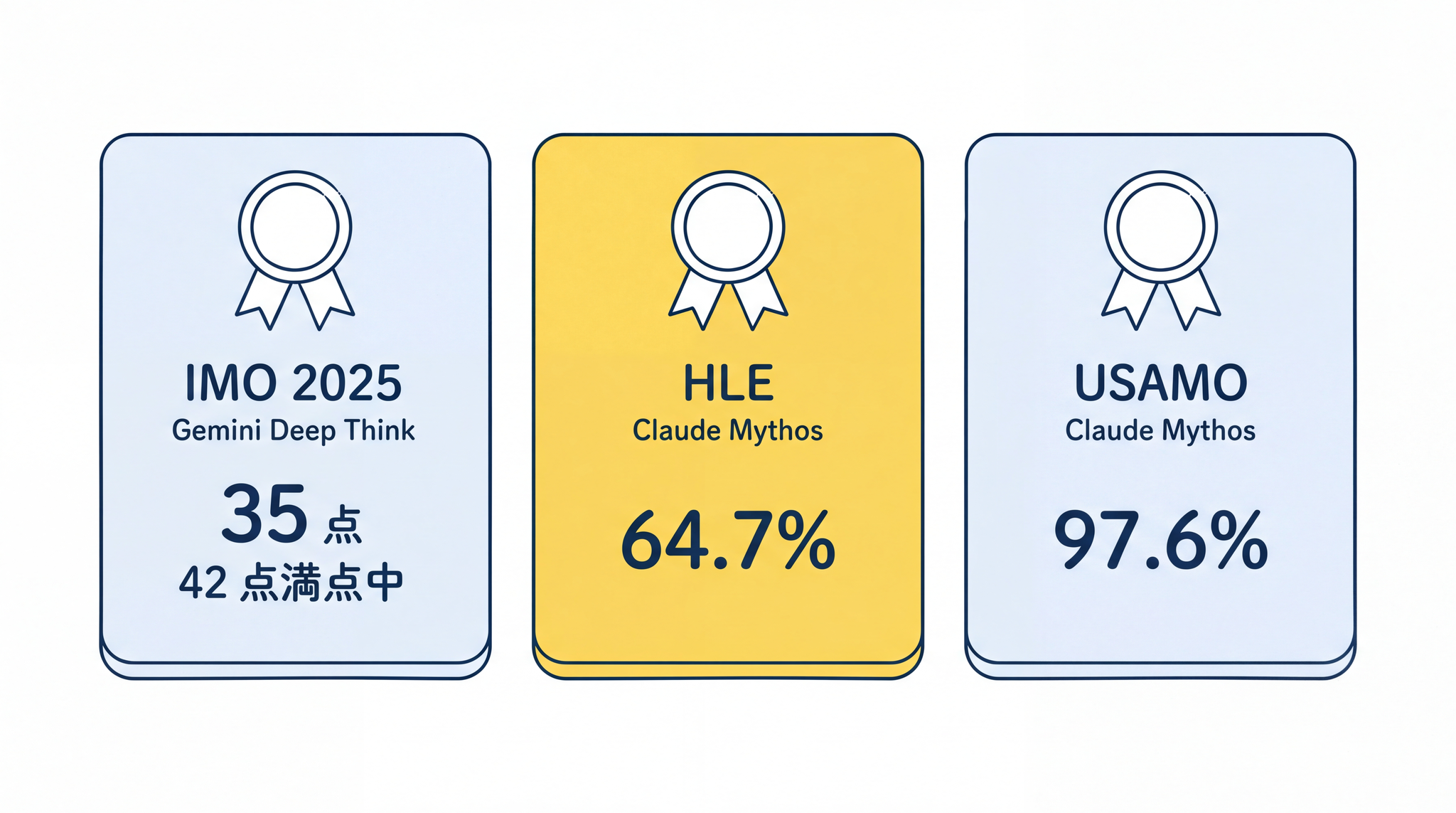
IMO 2025 ── 国際数学オリンピック:2025 年 7 月、Google DeepMind の Gemini(Deep Think モード)が、国際数学オリンピックで 42 点満点中 35 点を獲得しました5。金メダル水準のスコアで、IMO の公式組織が承認しています。
HLE と USAMO ── さらに難しい試験:HLE(Humanity’s Last Exam。「人類最後の試験」と呼ばれる、世界の専門家集団が設計した最難関の問題集)では、Claude Mythos がツールを使った条件で 64.7% を達成し、発表時点の最高値となっています4。全米数学オリンピック本選(USAMO)では 97.6% を記録しました6。いずれも限定パートナー向けに非公開で提供されており、一般には公開されていません。
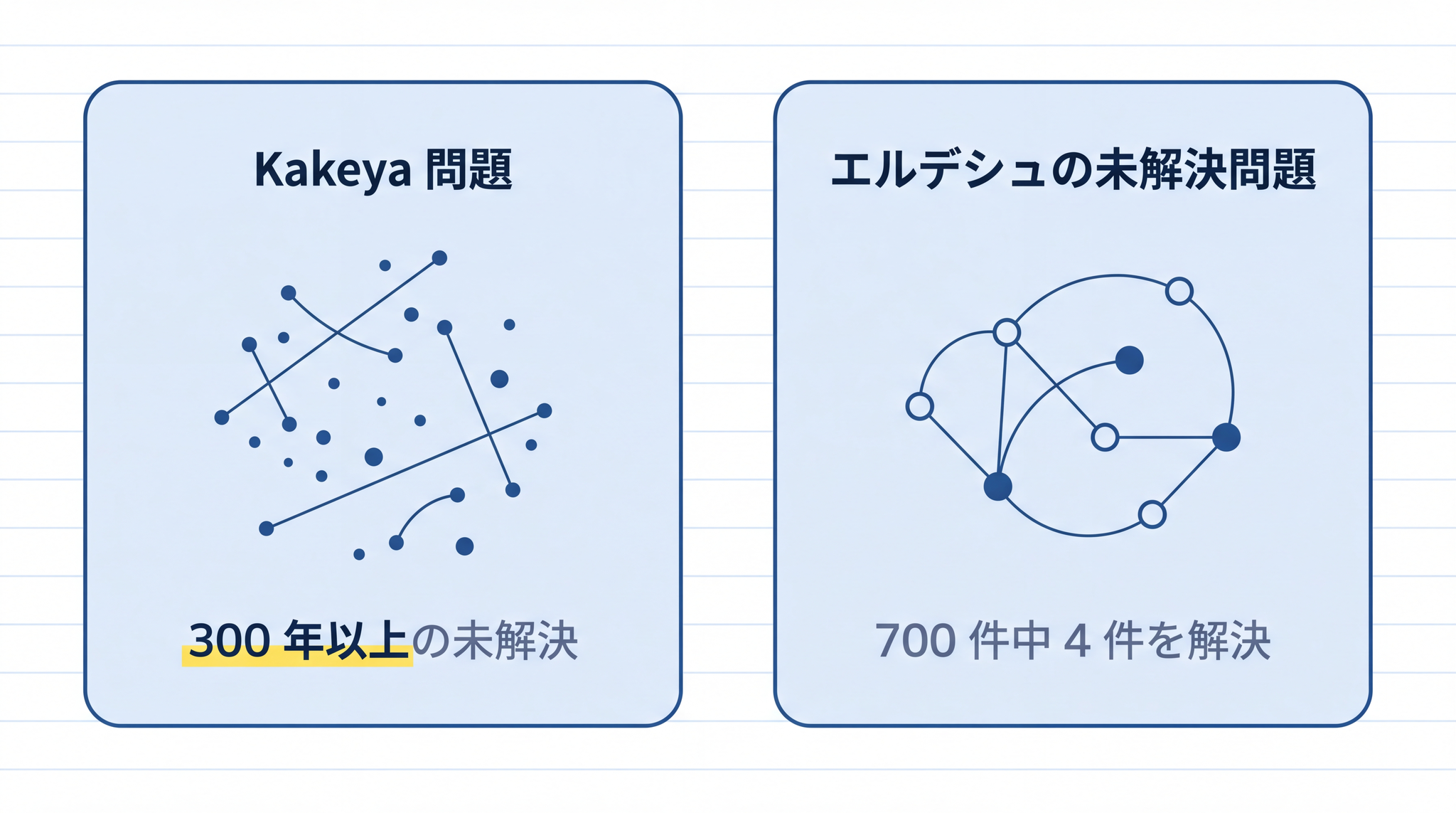
スコアで測れない範囲にも踏み込んでいる:AI が出力した構成をもとに、300 年以上誰も解けなかった数学の未解決問題の新証明が論文化されました7。別の未解決問題群でも、AI が複数の問題を自律的に解決しています8。
これらは「正解が存在する問い」でのスコアです。創造性・文化的文脈・人間の経験に根ざした判断では、能力の限界が別の形で現れます。ハルシネーション(もっともらしい嘘)もゼロにはなっていません。
※ 2026 年 5 月時点の情報です。主要なベンチマーク結果が大きく更新されたタイミングで見直します。
5. どんな問いで力を発揮するか ── 使い分けの目安
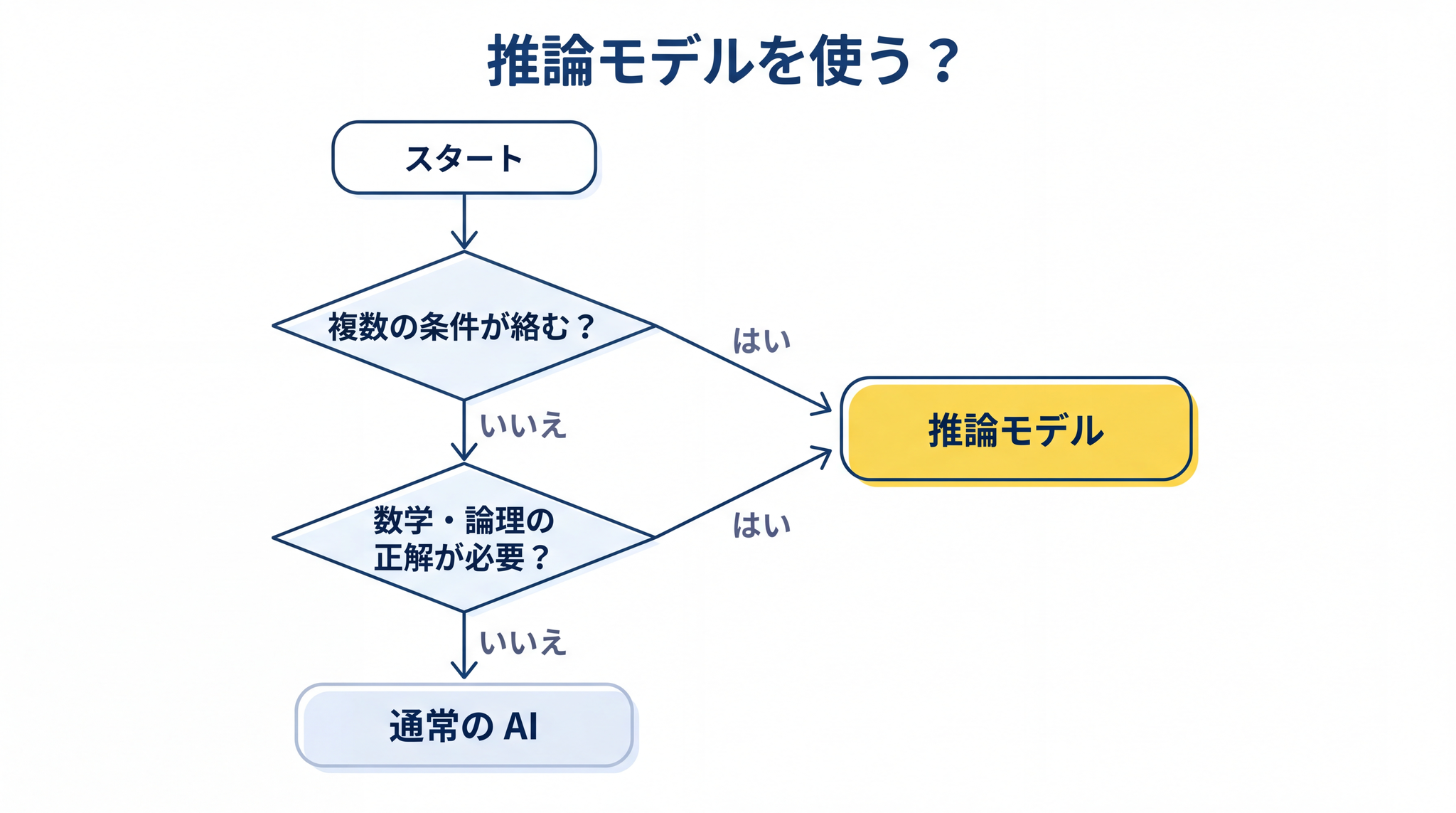
推論モデルは、考える時間がかかります。単純な問いでは「待った割に答えが変わらない」という状況が起きます。
| 問いのタイプ | 向き不向き | 例 |
|---|---|---|
| 数学・論理・証明 | ◎ | 計算問題、論理パズル、数式の検証 |
| 複数の条件を同時に考える問い | ◎ | 「A かつ B かつ C を満たす計画を立てて」 |
| 複雑な計画・段取りの立案 | ◎ | プロジェクトの工程設計、構造化レポートの骨格 |
| 翻訳・要約 | △ | 速度と精度のバランスは通常 LLM が優れる |
| 日常的な質問・会話 | △ | 天気、調べもの、雑談 |
| 素早い繰り返し対話 | × | 回答に時間がかかるため |
OpenAI は公式に、推論モデルが有効な領域として「数学、科学、エンジニアリング、金融、法務」を挙げています9。共通するのは「正解が存在して、複数の条件を論理的に踏まえた上で答える必要がある」という性質です。
Gemini の Thinking モードについて Google は 3 段階の使い分けを公式に示しています10。事実取得のような簡単なタスクには Thinking は不要で、高度な数学や多段階計画では最大思考を使う設計です。
6. 手順を書きすぎると逆効果になる
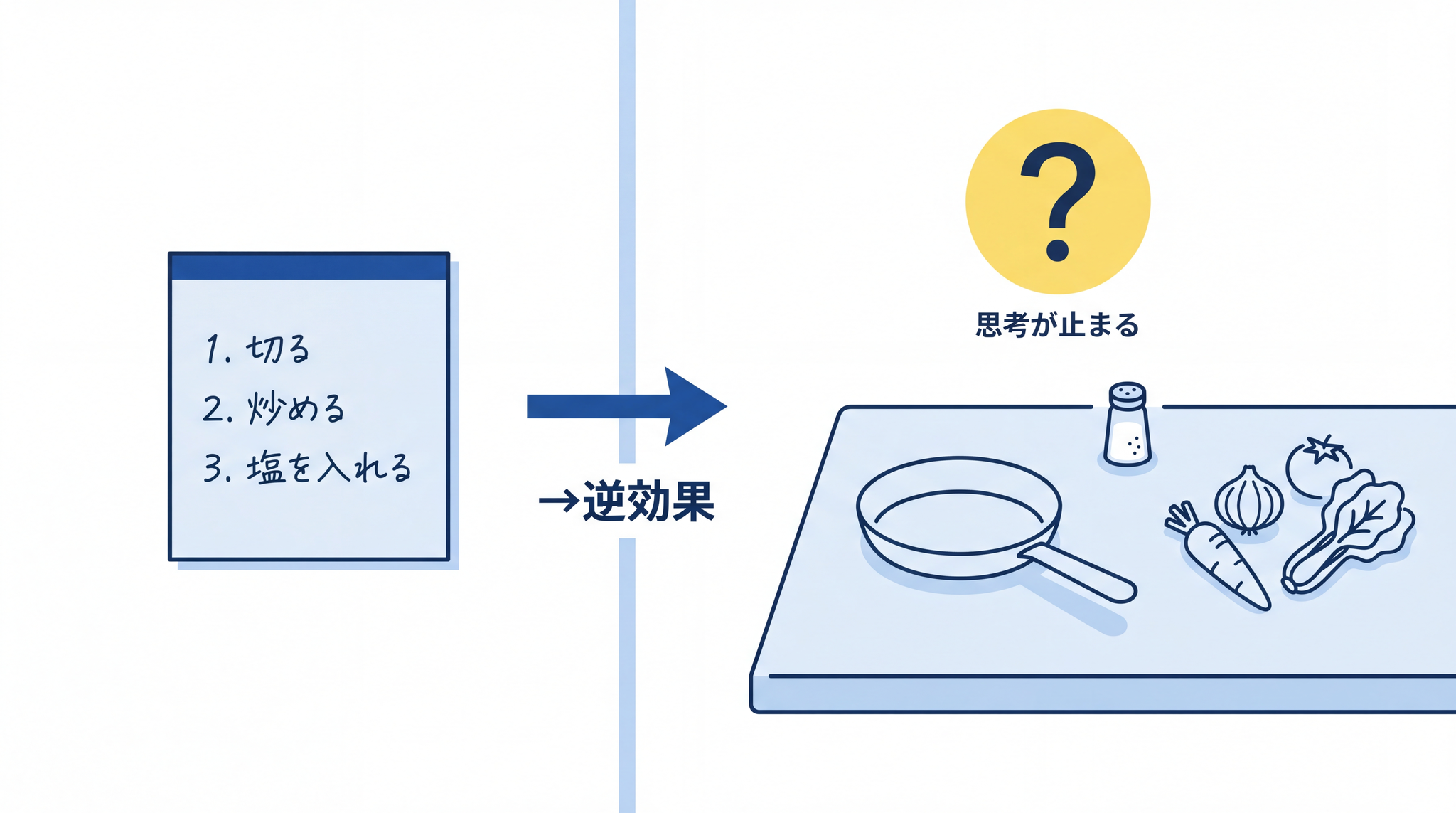
推論モデルにプロンプトを渡すとき、考え方の手順(ステップ 1:〜、ステップ 2:〜)まで細かく指定する書き方 は逆効果になります。
なぜか。料理が得意な人に「材料を切ってから炒めて、塩を小さじ 1 入れて、次に水を足して」と細かく手順を指示するとどうなるでしょうか。その人は自分の段取りで動けなくなり、むしろ下手な料理になってしまうことがあります。
推論モデルにも同じことが起きます。訓練を通じて「最適な考え方の進め方」がすでに内部に組み込まれています。そこに外から「ステップ 1 はこれ、ステップ 2 はこれ」と手順を押し込むと、モデルが自律的に選んだ推論の道筋と干渉してパフォーマンスが落ちます。
三社の公式文言
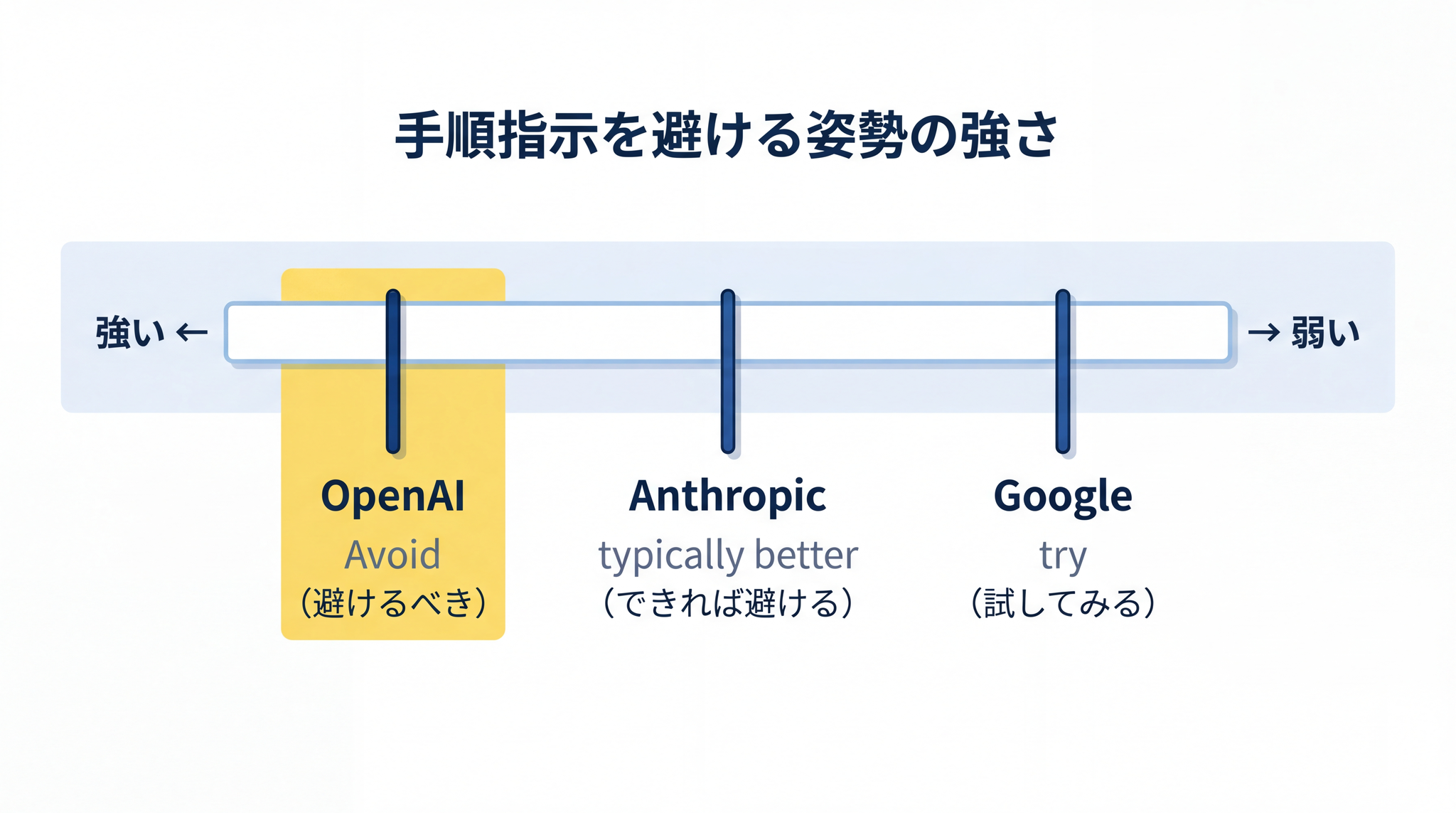
三社がこの点を公式に認めており、表現の強さはそれぞれ異なります。
- OpenAI:「避けてください(Avoid)」と最も強く断言し、内部で推論を行うため『ステップバイステップで考えなさい』と促すことは不要、場合によっては 妨げになる(may sometimes hinder)とまで明示しています9
- Anthropic:「徹底的に考えなさい」のような一般的な指示のほうが、手書きの細かいステップバイステップ計画よりも、通常はより良い推論を生み出す(typically produce better reasoning)と比較形で述べています11
- Google:Thinking を使うときは ステップバイステップの指示なしで試してみてください(try prompting without step-by-step instructions)と実験推奨形で提案しています12
表現の強度に差はありますが、「手順の細かい指定を書かないほうがよい」という方向性は三社共通です。
何を変えて、何を変えないか
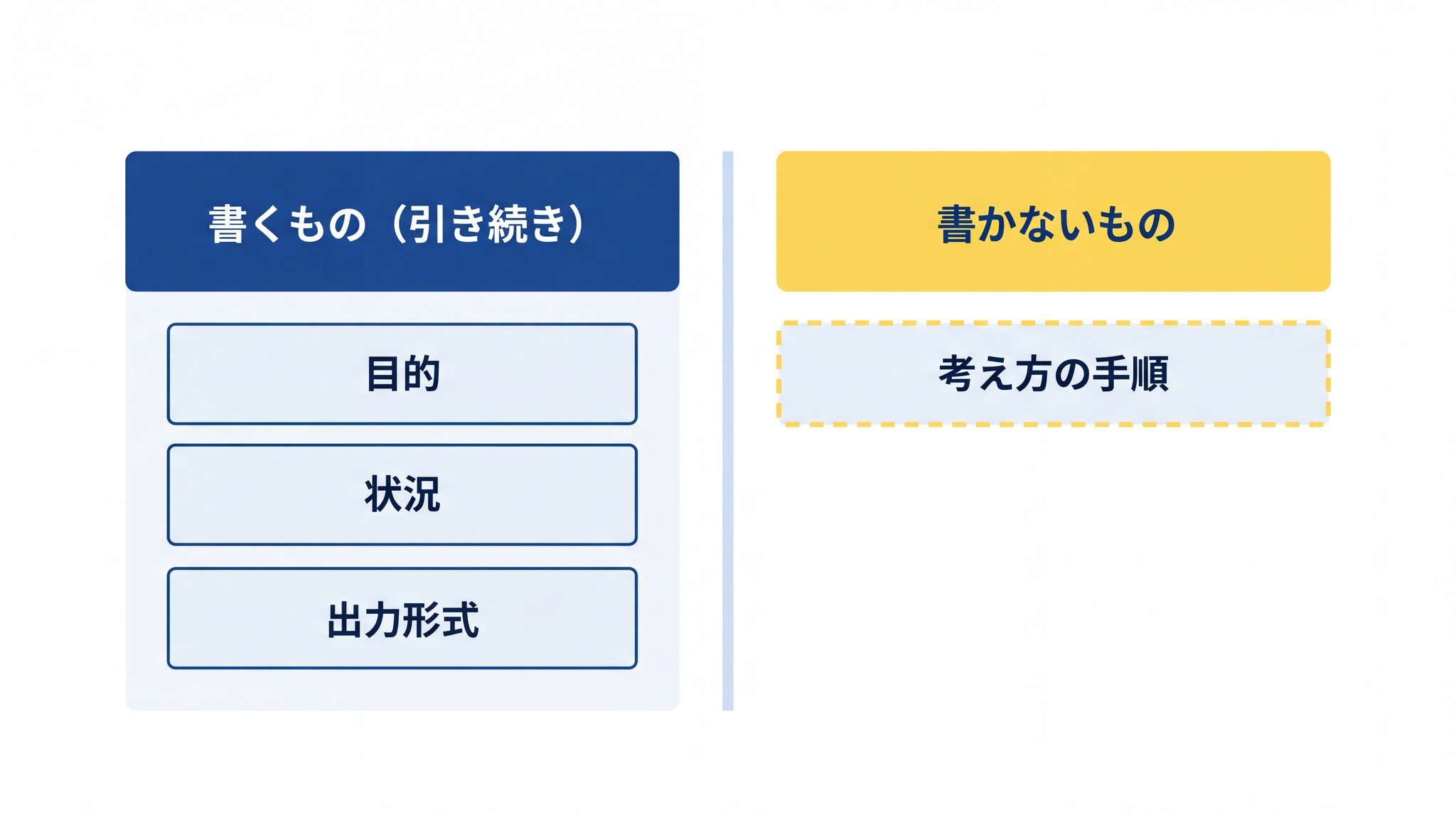
| プロンプトの要素 | 推論モデルへの渡し方 |
|---|---|
| 目的(何のためか) | 引き続き書く |
| 状況(あなたは誰で、何を知っているか) | 引き続き書く |
| 出力形式(どんな形で返してほしいか) | 引き続き書く |
| 考え方の手順(ステップ 1 は…ステップ 2 は…) | 書かない。AI に任せる |
変えるのは「考え方の手順を指定すること」だけです。目的・状況・出力形式は引き続き渡してください。
逆効果になりやすい書き方:
この問題を解いてください。
まずステップ1として前提条件を洗い出してください。
次にステップ2として条件を式に変換してください。
最後にステップ3として計算を進めてください。推論モデルに合う書き方:
この問題を解いてください。
答えと、その根拠を示してください。目的(「問題を解く」)と出力形式(「答えと根拠」)は渡します。考え方の進め方は AI に任せます。

7. この記事からつながる場所
LLM そのものの動き方(次トークン予測・コンテキストウィンドウ・学習の 3 段階)を基礎から知りたい方は、「LLM の仕組み」を参照してください。
プロンプトの「5 つの型」に戻りたい方は、「プロンプトの書き方」を参照してください。§6 の「考え方の手順は渡さない」は、この記事の型と組み合わせると実践できます。
各社の設計思想の違いは、「ChatGPT・Claude・Gemini はなぜ違うのか」で整理しています。
推論モデルが普通に使える時代になったいま、まず試せることは一つです。プロンプトから手順を抜いて、目的と欲しい出力形式だけを渡してみてください。
出典・参考文献
-
Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Mathematical Olympiad — Google DeepMind ↩
-
New Nikodym set constructions over finite fields | arXiv:2511.07721 ↩
-
Accelerating Mathematical and Scientific Discovery with Gemini Deep Think — Google DeepMind ↩
-
Overview of prompting strategies | Generative AI on Vertex AI | Google Cloud Documentation ↩