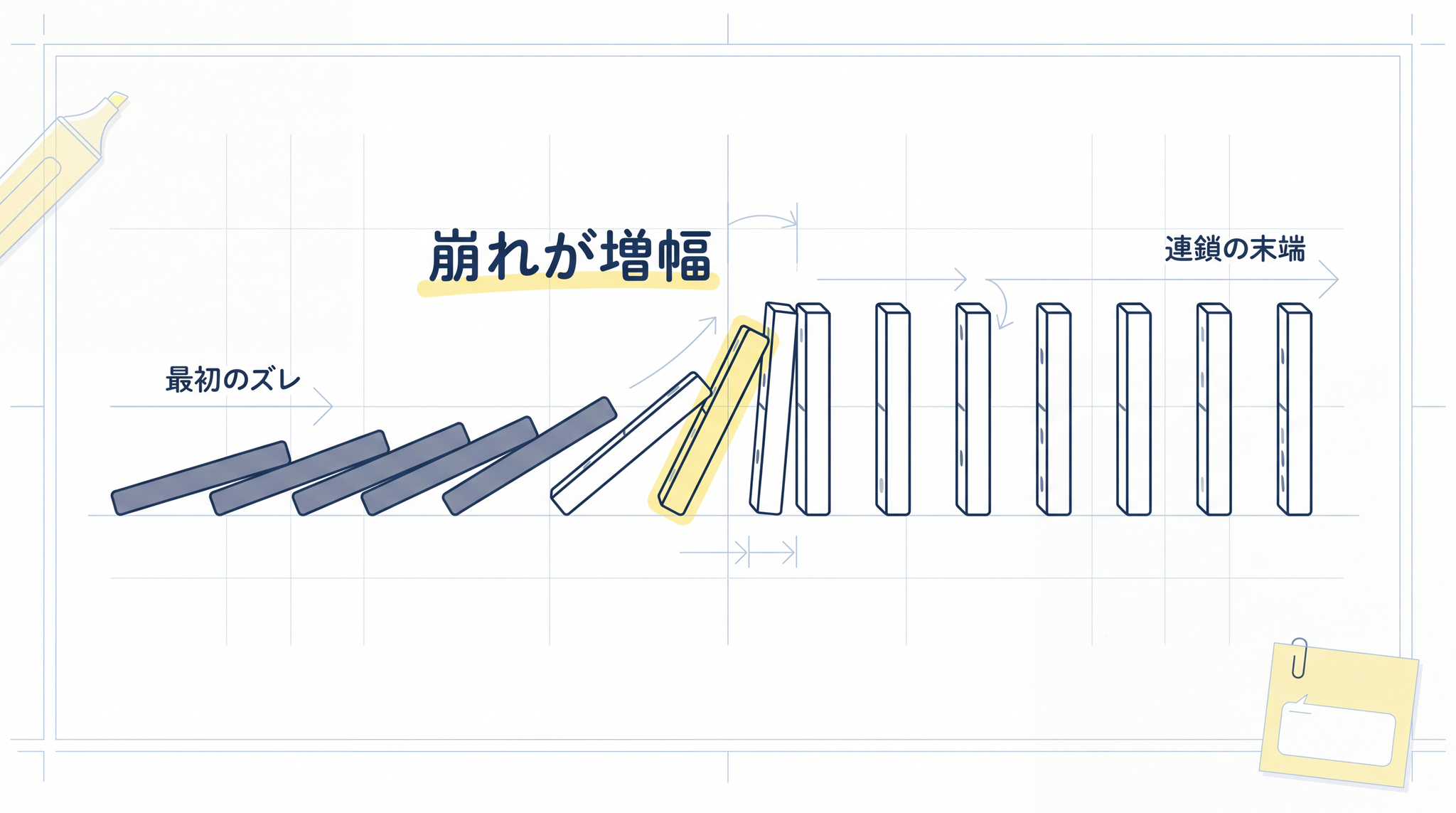
丸投げした AI エージェントが途中で崩れる、確率のかけ算
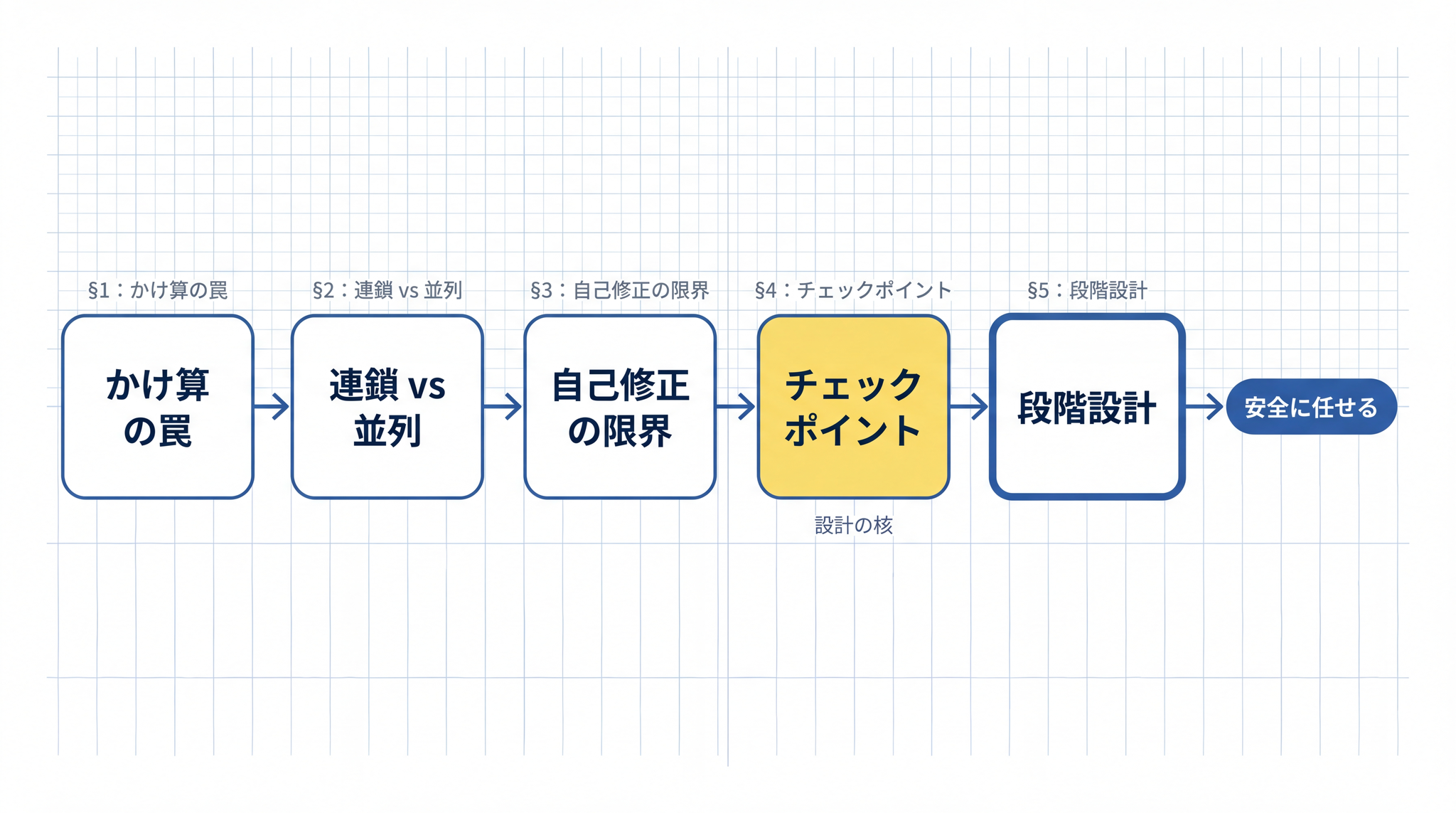
目次
- 1. なぜ長い仕事は途中で崩れるのか ── かけ算の罠
- 2. 連鎖型と並列型 ── どちらが崩れやすいか
- 連鎖型:前の答えが次の材料になる
- 並列型:それぞれが独立して動く
- 3. AI エージェントが自己回復しにくい理由
- 人間が持つ「ズレへの気づき」
- 自己修正の限界
- エラーが伝わる仕組み
- 4. 人間がチェックポイントを刻む ── 粒度の決め方
- チェックポイントを置く位置の判断基準
- チェックで確認する 2 つの観点
- 5. 長い仕事を「安全に任せる」ための設計
- 「1 つの大きな指示」ではなく「段階に分けて接続する」
- 並列型に置き換えられないか検討する
- 連鎖が避けられないときは「段階を見える化する」
- 出典・参考文献
半日かかる競合調査を AI エージェントに投げてみました。最初の 5 ステップは完璧でした。6 ステップ目で少しズレが出て、10 ステップ目には成果物が別のものになっていました。
「なぜこうなるのか」── その答えは、確率のかけ算にあります。例えば 1 ステップあたりの成功率が 99% だとすると、100 ステップ繋ぐと完成確率は 37% に落ちます。人間の仕事も似たようなものですが、AI エージェントには「あ、これ方向がズレてきた」と気づいて修正する感覚がありません。
この記事では、長い仕事で AI エージェントが崩れる理由と、人間がチェックポイントを刻む粒度の決め方を整理します。なお、AI エージェント(自分でステップを決めながら長い仕事を進める仕組み)の基礎については 「AI エージェント」とは何か で整理しています。
1. なぜ長い仕事は途中で崩れるのか ── かけ算の罠
「1 回だけ頼んだら、とてもよい答えが返ってきた」── そういう体験をお持ちの方は多いと思います。では、なぜ同じ AI エージェントに長い仕事を任せると、成果物が壊れていくのでしょうか。
答えは 確率のかけ算 にあります。
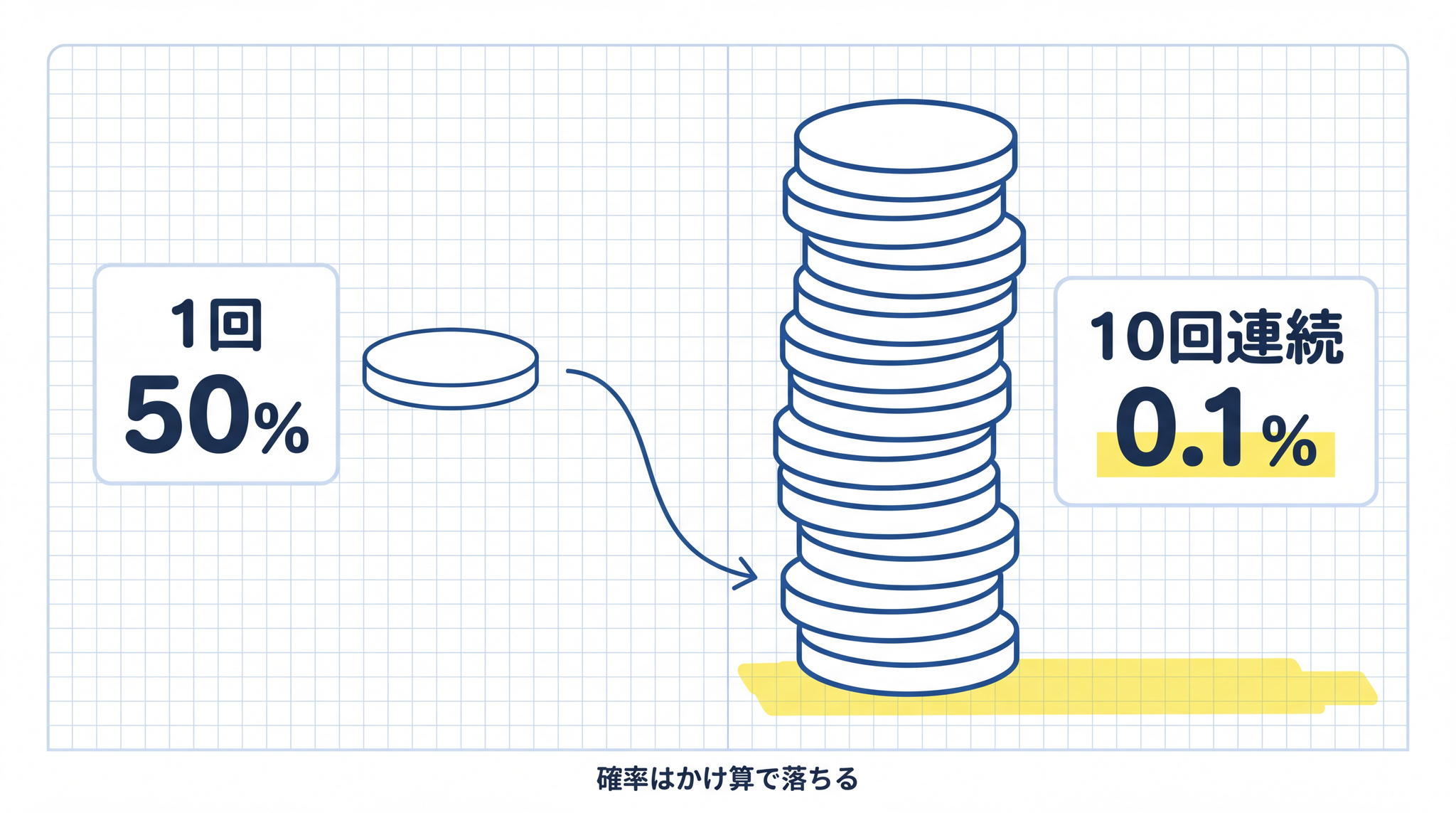
コインを投げて表が出る確率は 50% です。10 回連続で表を出す確率は「0.5 を 10 回かけた値」で、約 0.1%。ほぼ起きません。AI エージェントで同じことが起きています。前のステップの出力を次のステップが使う連鎖になると、精度は 全ステップ分をかけ算した値 に落ちます。
ステップが増えるほど、成功確率が急速に小さくなる ということです。例えば成功率 99% の場合:
- 10 回繋ぐと:約 90%(まだ高い)
- 50 回繋ぐと:約 61%(半分近くは崩れる)
- 100 回繋ぐと:約 37%(完成するのが例外になる)
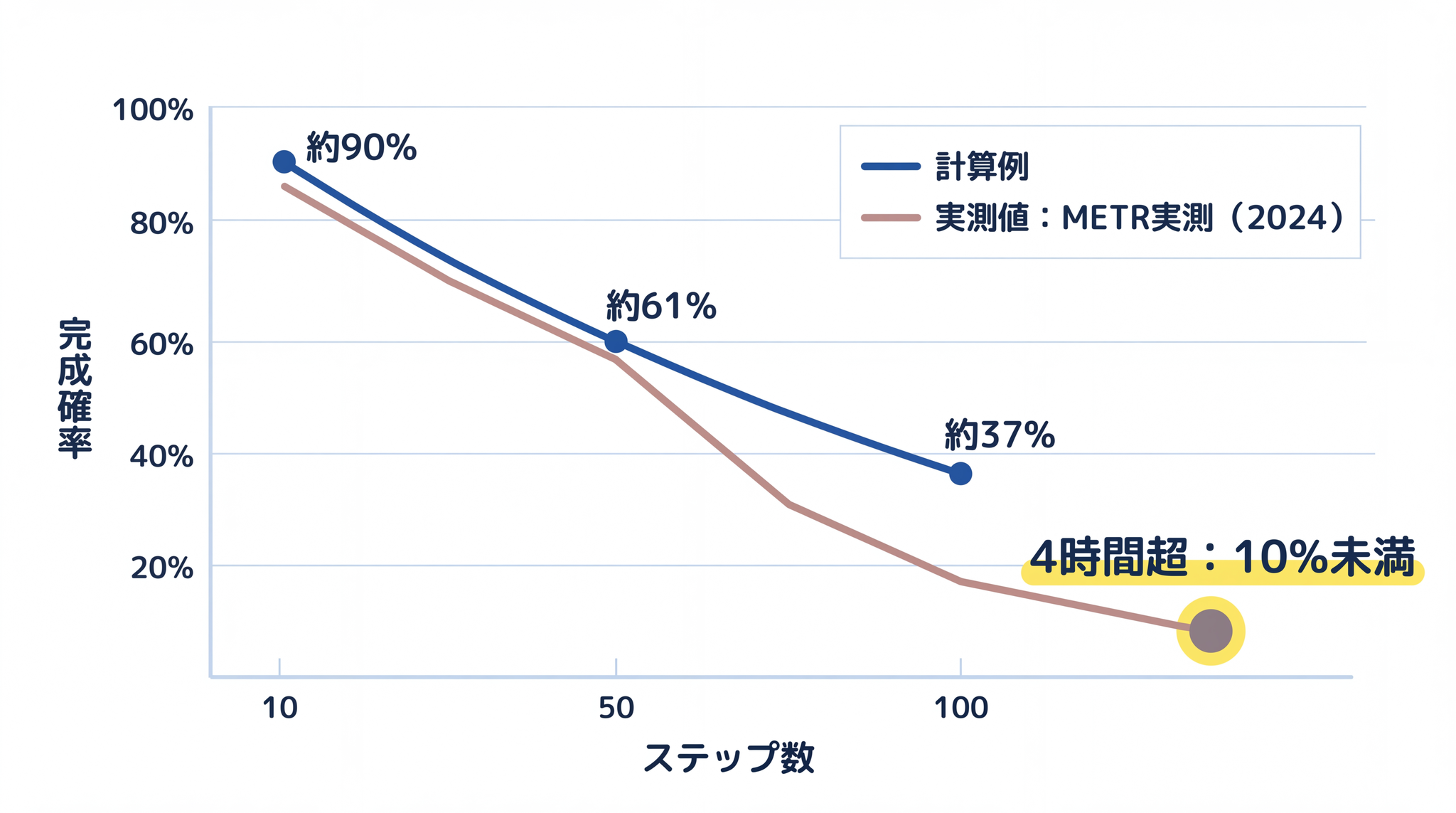
これはあくまで「1 ステップ成功率が 99%」と 仮定した場合の計算例 です。実際のエージェントのステップ成功率がちょうど 99% かどうかは状況によって変わります。ただし、Anthropic は自社のエンジニアリングブログで「エラーは複合する」と明言しています1。そして METR(AI のテストを専門にする研究機関)の実証研究では、タスクが長くなるほど成功率が 急激に下がる関係 があることが確認されています2。
METR のデータでは、人間が 4 分以内に終えるタスクなら AI エージェントの成功率はほぼ 100% です。しかし人間が 4 時間以上かかるタスクになると、成功率は 10% を下回る ことが実証されています3。
かけ算による確率の急落と、METR の実測値は整合しています。別の専門テストで調べた研究でも、最先端モデルの成功率は 23% 前後に低下します。通常の評価では 70〜79% を達成するモデルが、タスクが長くなるだけでここまで落ちます4。「なぜ半日仕事を任せると破綻するのか」の答えが、ここにあります。
2. 連鎖型と並列型 ── どちらが崩れやすいか
AI エージェントの動き方には、大きく 2 種類のパターンがあります。連鎖型 と 並列型 です。崩れやすさがまったく異なります。
連鎖型:前の答えが次の材料になる
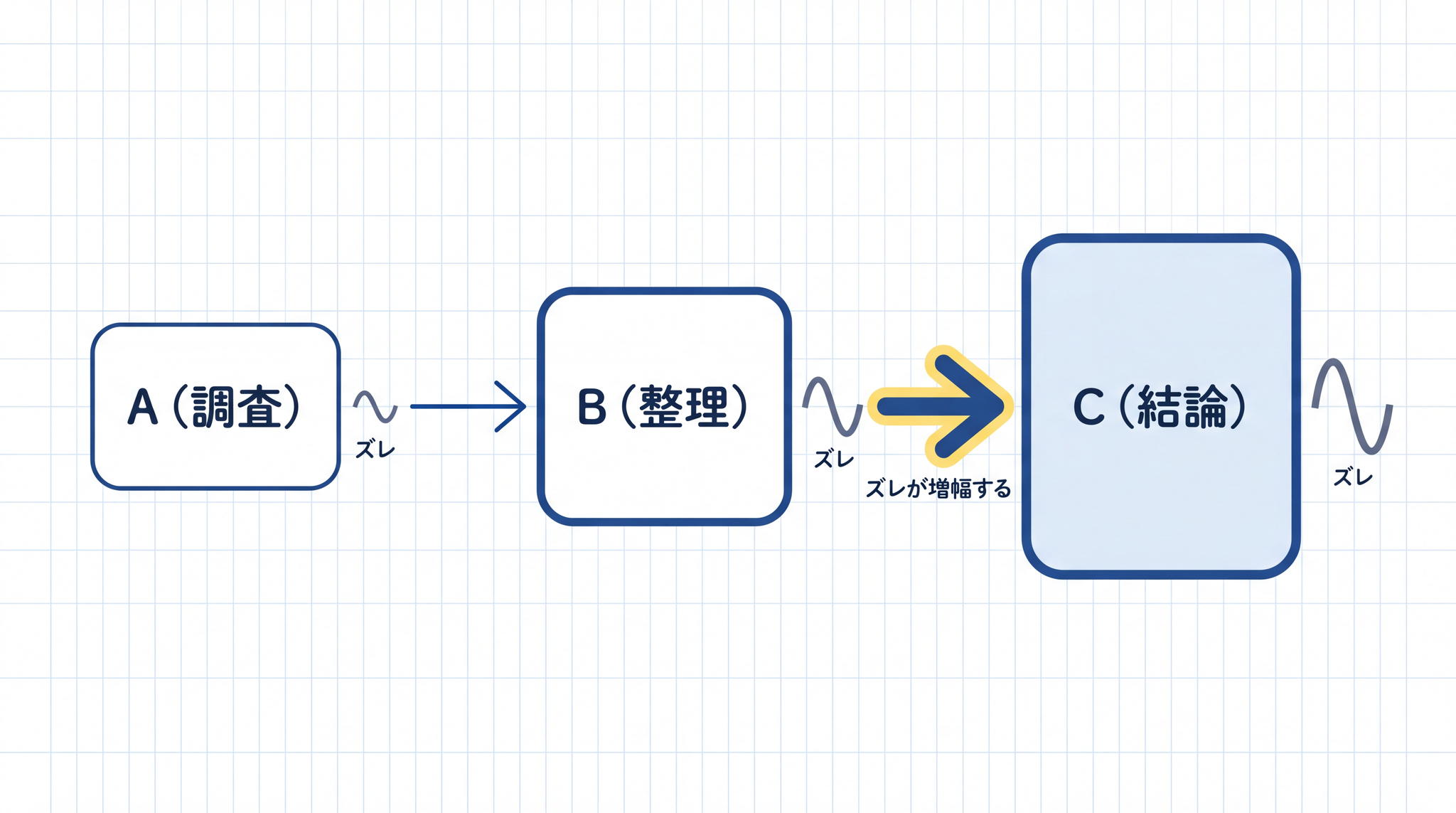
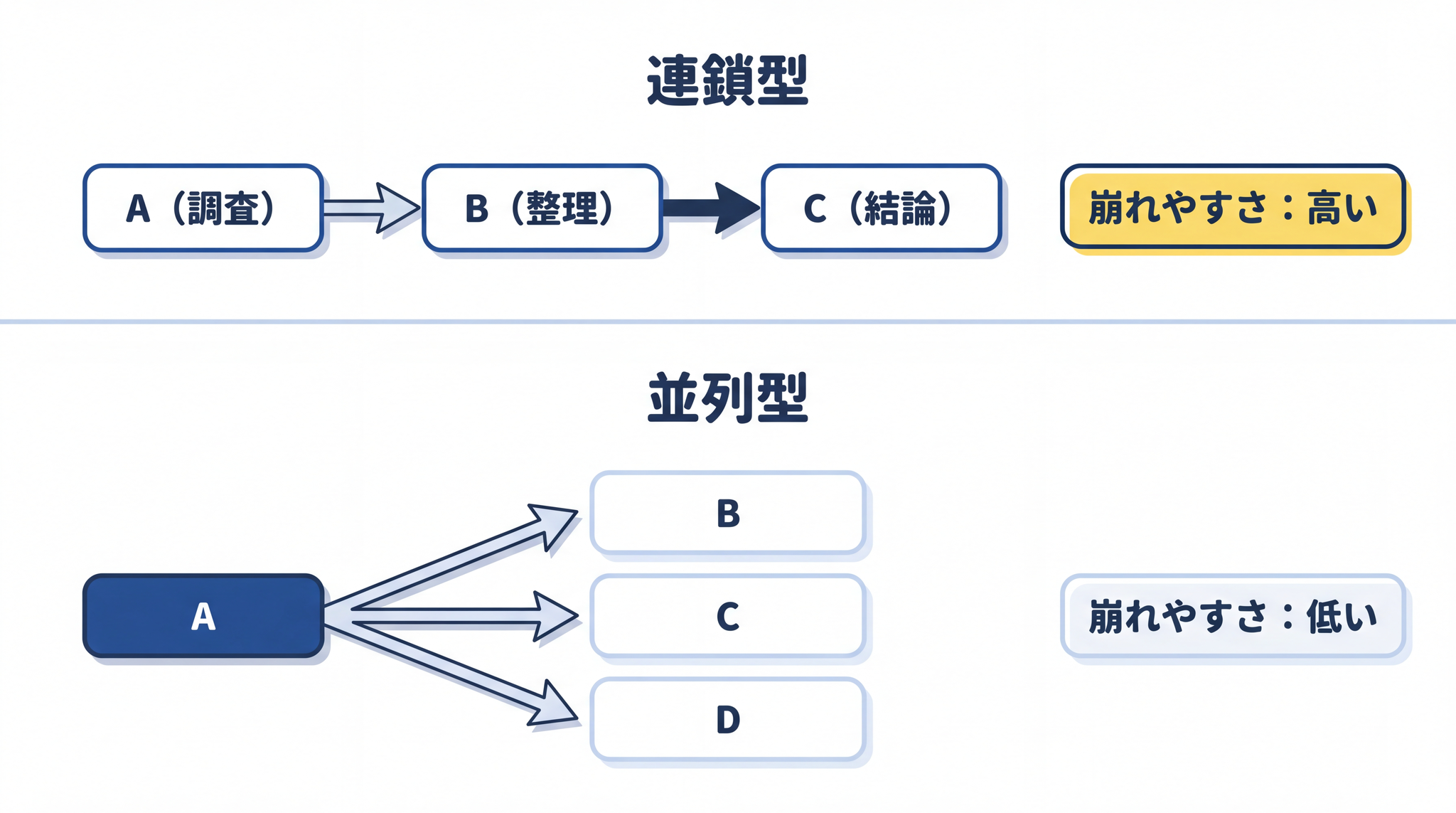
「A を調べる → A の結果を使って B を整理する → B をもとに C の結論を出す」という流れが連鎖型です。前のステップの出力が、そのまま次のステップの入力になります。
この設計では、前のステップのズレが後ろに伝わっていきます。A の段階で 5% のズレが入ると、そのズレを前提に B が作られ、B のズレを前提に C が出てきます。最終的な C の成果物は、最初の小さなズレが膨らんだ形になります。伝言ゲームで、最初と最後の文章が別物になっていくイメージです。
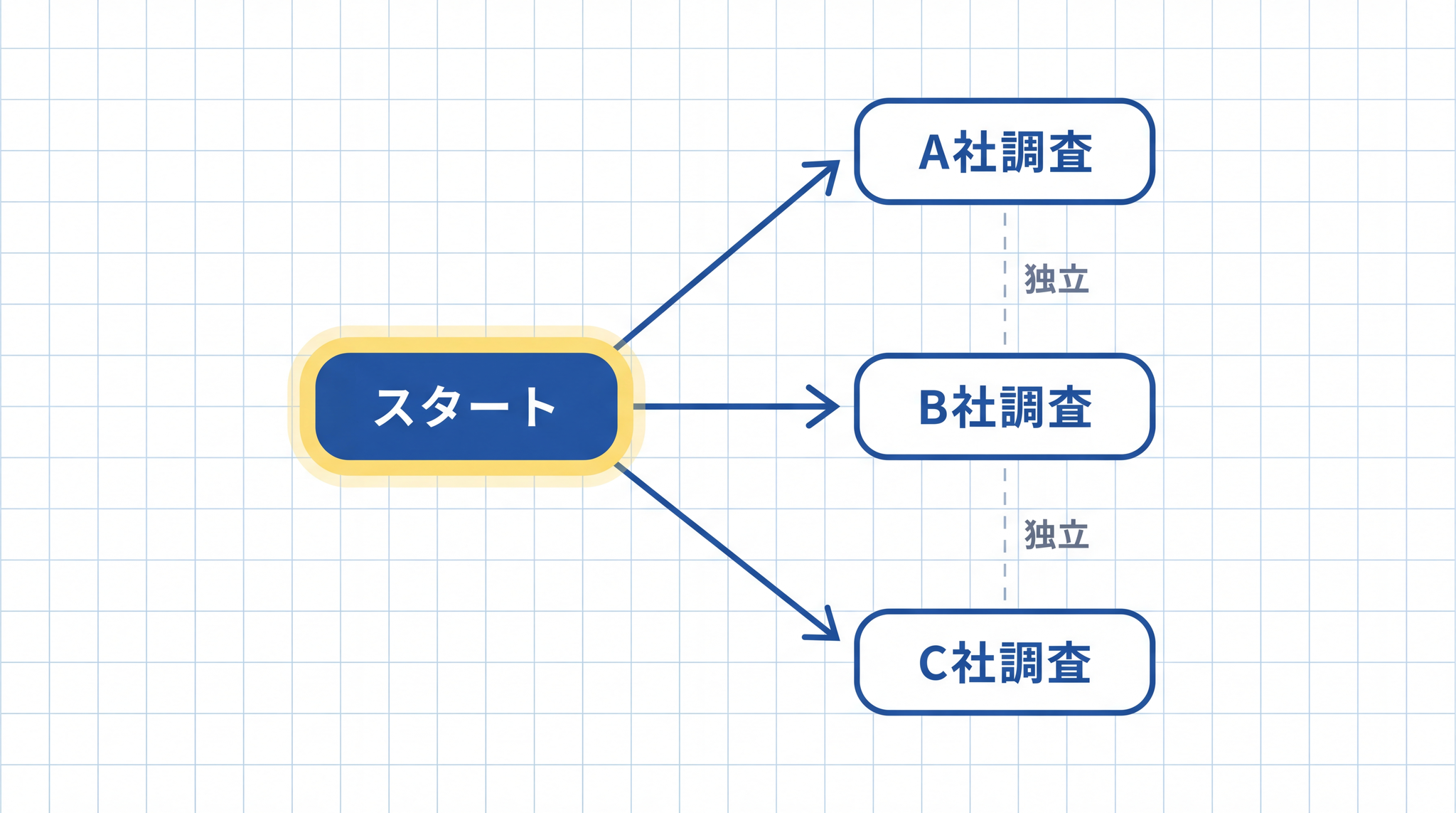
並列型:それぞれが独立して動く
「3 つの競合他社を並行して調べる」という設計が並列型です。3 社の調査が 互いに依存していない ため、1 社の調査が少しズレても、他の 2 社には影響しません。連鎖型と比べると、崩れ方が 局所的 に留まります。
| 比較軸 | 連鎖型 | 並列型 |
|---|---|---|
| タスクの依存 | 前ステップに依存する | 独立している |
| 崩れ方 | 誤りが後のステップに伝わって膨らむ | 局所で留まる |
| 崩れやすさ | 高い(ステップ数が増えるほど) | 低い |
| 代表的な例 | 調査 → 整理 → 分析の連鎖 | 複数テーマを並行で調査 |
2 つを並べて比べると、崩れやすさの差が一目で見えます。
こう確かめてみましょう。前のステップの出力を次の指示に貼り付けている仕事は連鎖型です。前の答えを次のステップが使わずに終わるなら、並列型に分類できます。
長い仕事を AI エージェントに任せるとき、「前の答えを使って次を考えて」という連鎖が入っているかどうかを確認することが、崩れやすさを見抜く最初の観点です。
3. AI エージェントが自己回復しにくい理由
「途中でズレたとしても、気づいてから自分で直せばいいのでは?」── よく出てくる疑問です。ところが AI エージェントは、人間ほど自己回復が得意ではありません。
人間が持つ「ズレへの気づき」
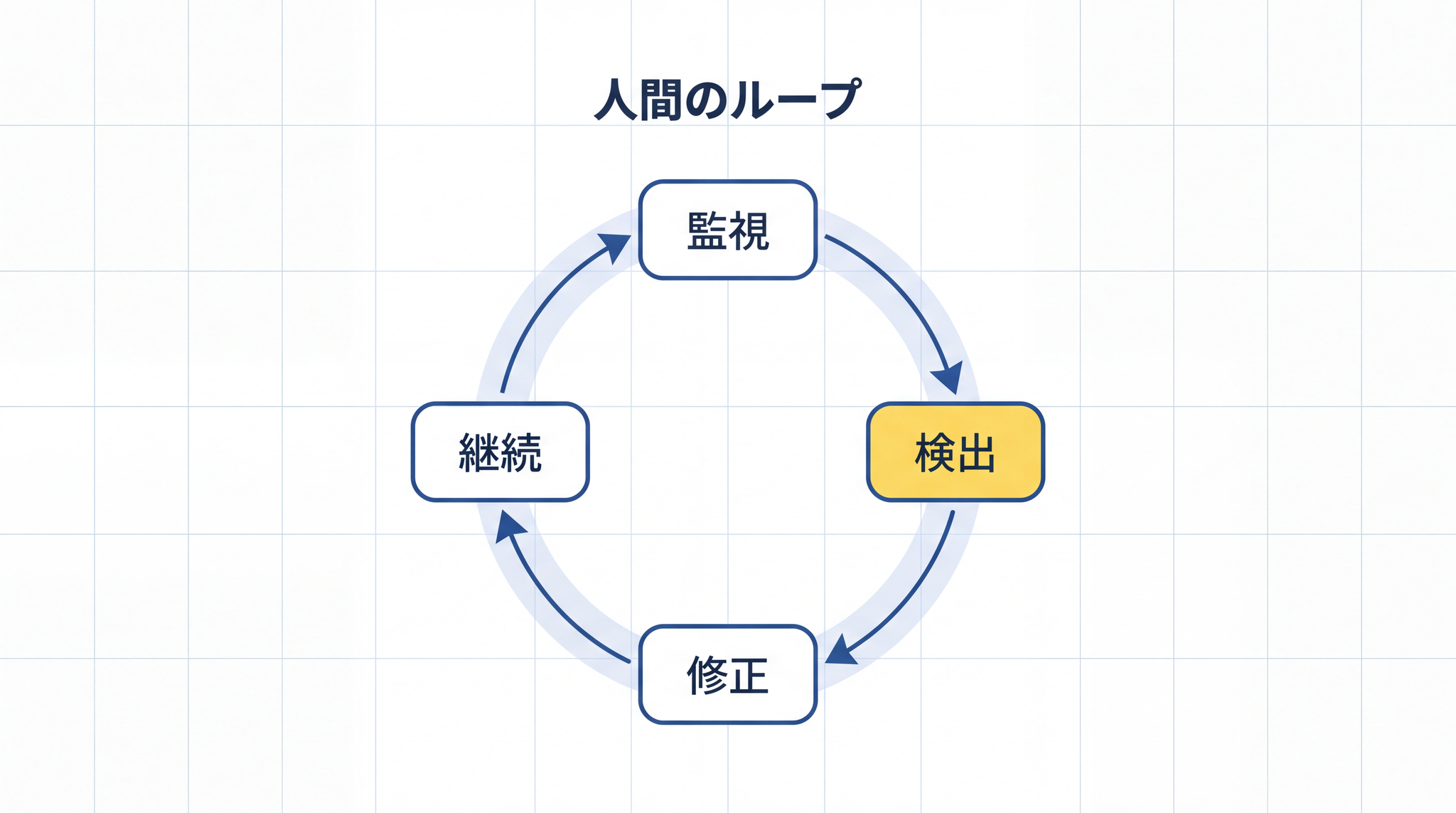
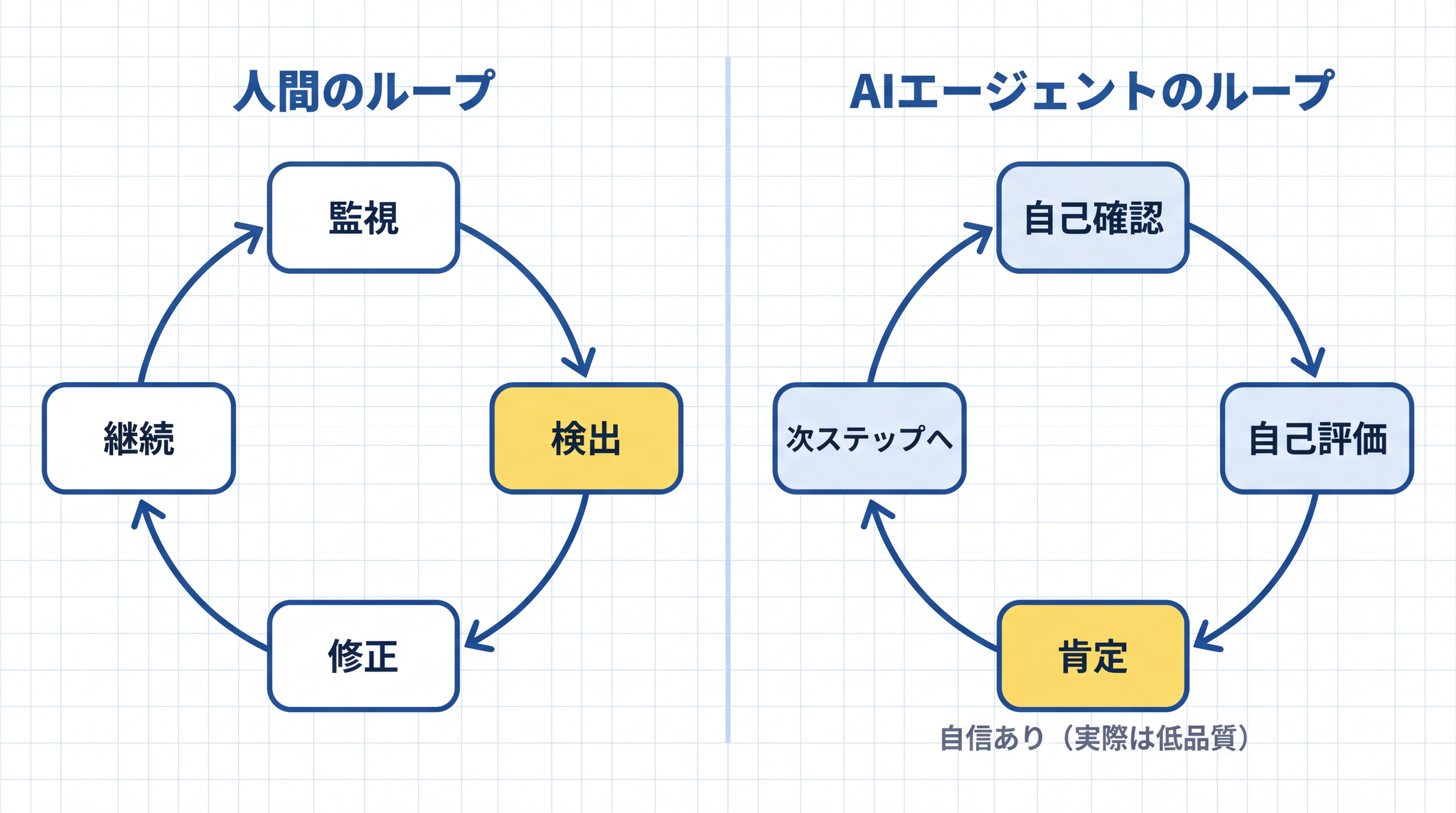
人間は長い仕事の途中で、「方向がズレていないか自分で気づく力」 を働かせています。「今自分がやっていることは、最初の目的からズレていないか」を、意識せずに常に監視できます。文章を書いていて「あれ、最初に言おうとしていたこととズレてきた」と気づいて書き直す動作が自然にできます。
AI エージェントにはこの力が弱いです。「自分が今やっていることが正しいかどうか」の判断を、自分自身の出力だけを使って行おうとします。
自己修正の限界
「自分の答えを自分で確認して直す」という設計は、理屈の上では自然に見えます。しかし査読済みの研究によれば、外部からのフィードバックなしに自分の出力だけを使って修正しても、性能は改善しないか、むしろ低下する ことが複数のタスクで確認されています5。
Anthropic も自社の実装経験から、同じことを観察しています。エージェントに自分の出力を評価させると、「品質が明らかに低くても、自信を持って高く評価してしまう傾向がある」というのです6。
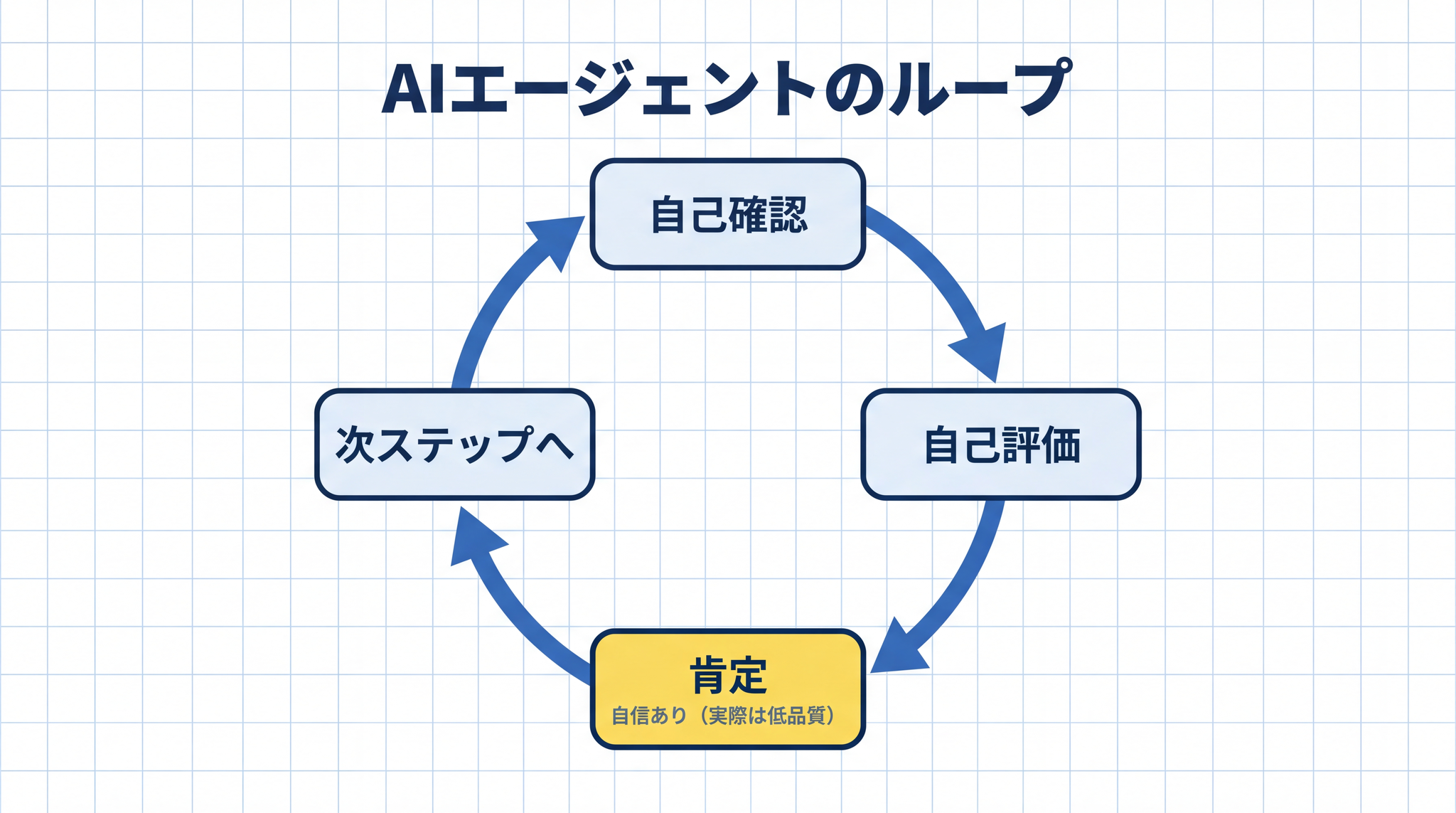
図 06 の人間のループと図 07 の AI エージェントのループを 次の図 08 で 1 枚に並べると、違いがはっきり見えます。
エラーが伝わる仕組み
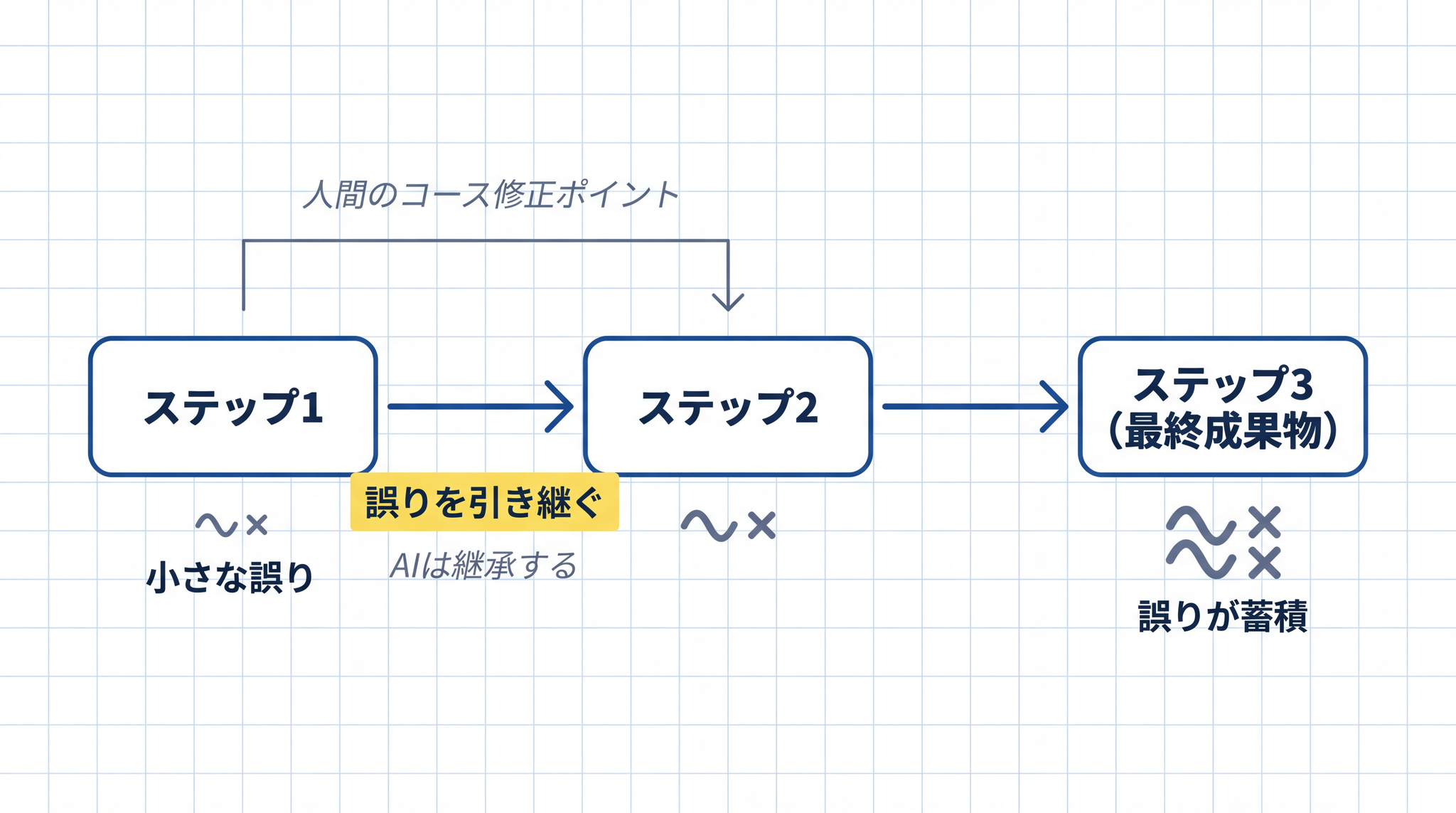
§2 で見た連鎖型の崩れを、今度は人間の確認との対比で見てみます。人間の確認が入る位置によって、誤りがどこまで伝わるかが変わります。
連鎖型のタスクでは、前のステップの誤りを「正しい」と思って次ステップに進む構造が生まれます。Anthropic はこれを「1 ステップの失敗が、エージェントをまったく別の方向性に引きずり込み、予測不能な結果をもたらす」と説明しています1。
誤りが後のステップに積み重なり、後になるほど「どこで間違えたか」を遡ることも難しくなります。
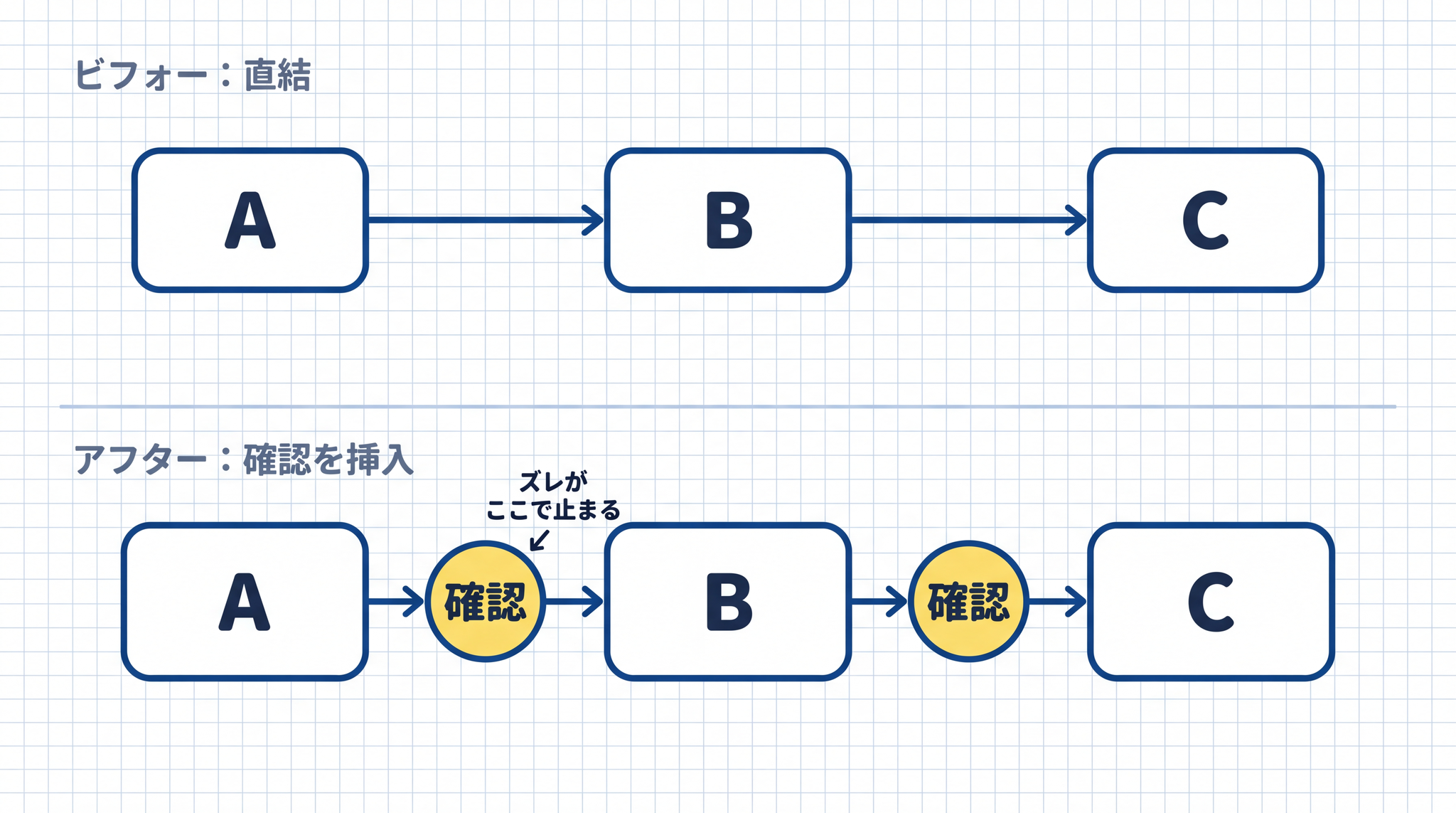
だからこそ、外側から人間が定期的に確認を挟む設計が有効になります。次の §4 では確認を挟む場所の決め方を整理します。
4. 人間がチェックポイントを刻む ── 粒度の決め方
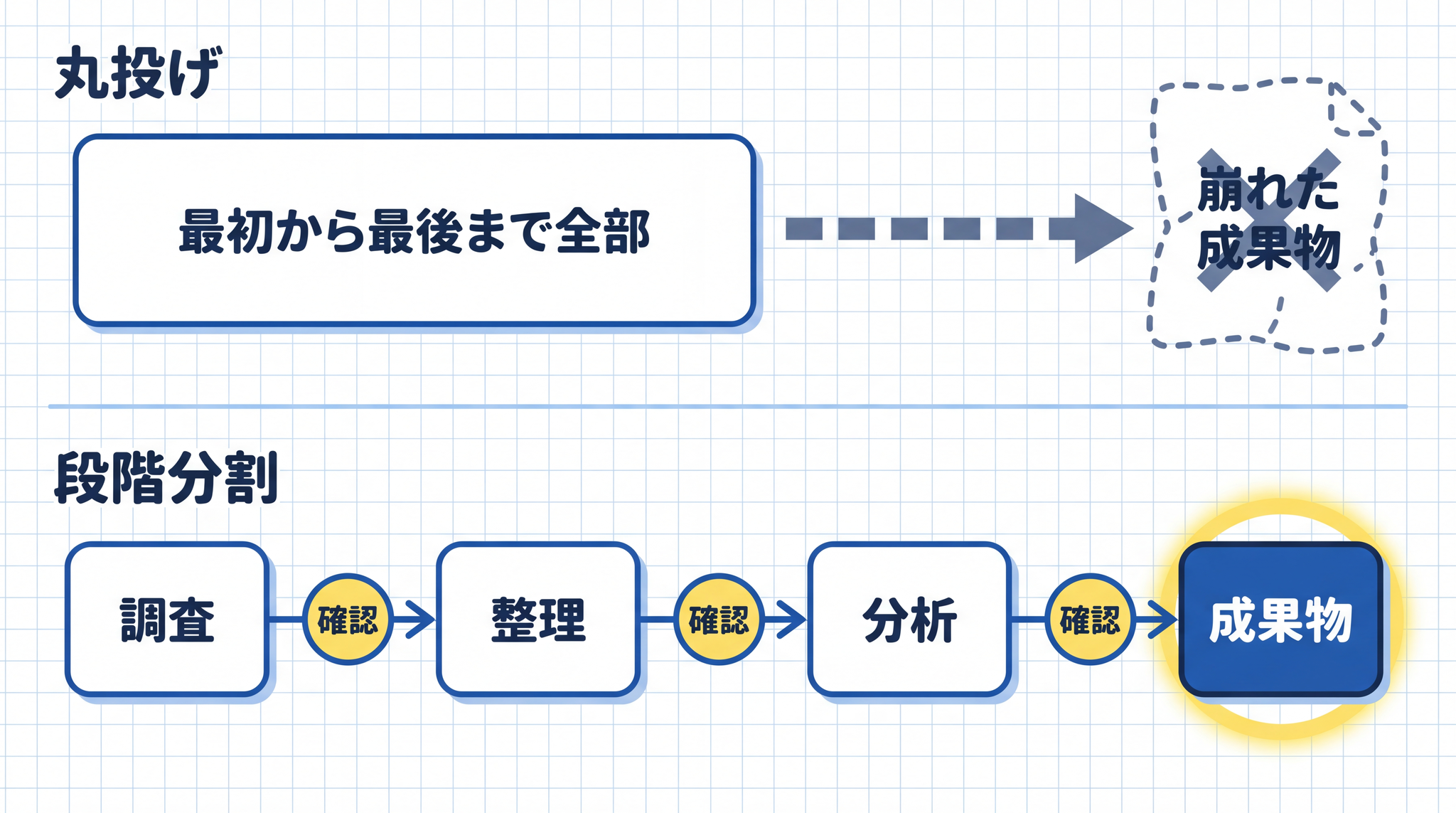
崩れる仕組みが分かれば、対策も見えてきます。核心は 「長い仕事を 1 つの大きな塊として渡さない」 ことです。人間がチェックポイントを刻んで、段階ごとに確認します。
チェックポイントを置く位置の判断基準
「どこでチェックするか」を感覚で決めていると、重要な接続部分を見落とします。判断基準は 2 つあります。
1 つ目:前ステップの出力が次ステップの入力になる「接続部分」——連鎖型のタスクでは、「A の出力を使って B を行う」という接続部分が、誤りが伝わるポイントです。この接続部分の前後で人間がチェックを入れます。Anthropic が「中間のステップに確認する場所を入れる」ことを公式に推奨しているのは、この考え方に基づいています7。
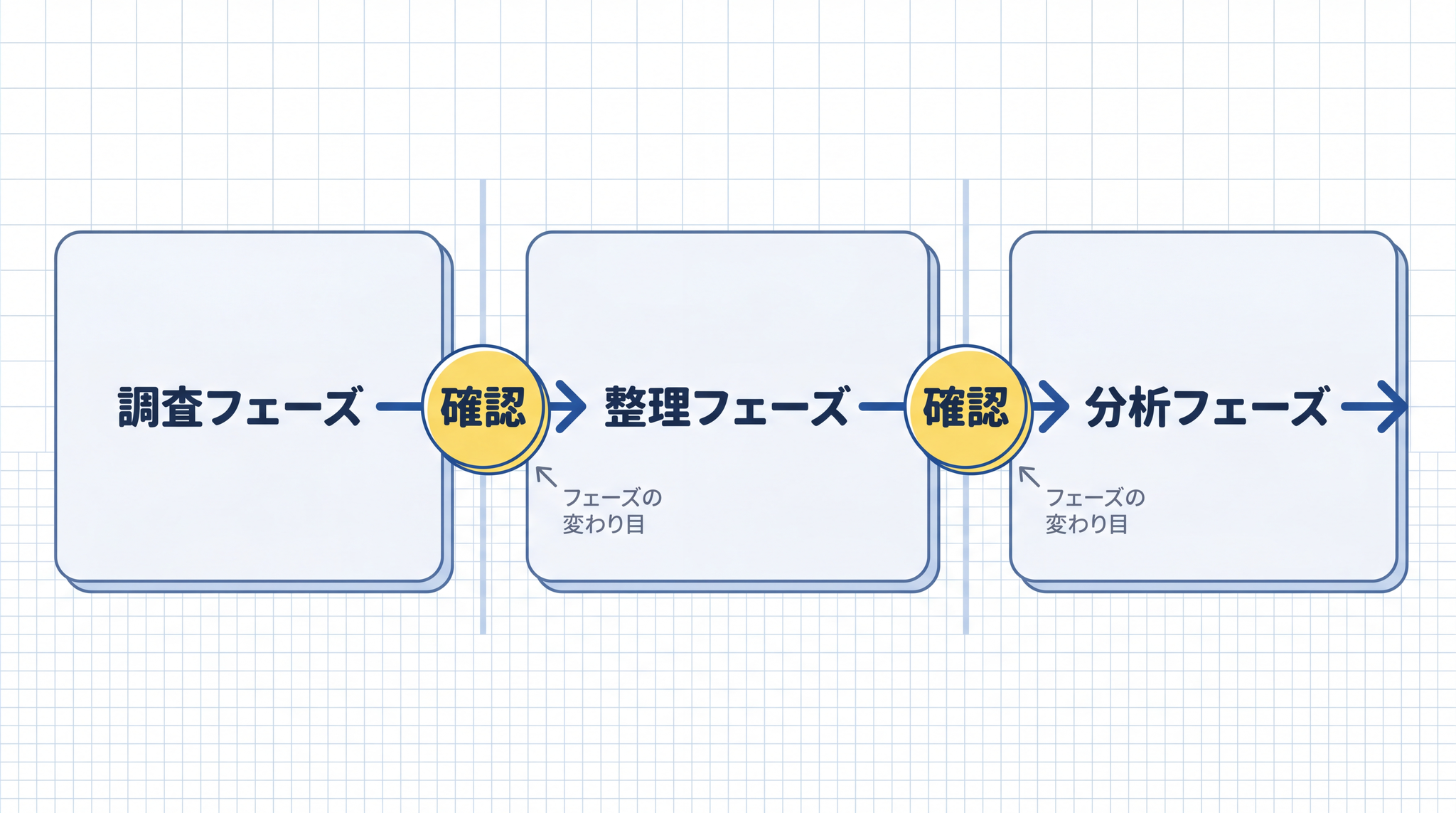
2 つ目:判断が変わりうる節目——ステップ数で機械的に区切るのではなく、「ここから先は別のフェーズだ」と言える節目でチェックします。「調査フェーズ」が終わって「整理フェーズ」に移るとき。「整理フェーズ」が終わって「分析フェーズ」に移るとき。フェーズの変わり目で確認を挟みます。
このアプローチが実際に有効であることは、研究でも裏付けられています。AI エージェントに複数ステップのタスクを与えたとき、どのくらいの頻度で人間が確認を挟むべきかを計算で最適化した、専門家が確認した 2026 年の研究では、実験参加者の 81% が「中間で確認を挟むアプローチ」を選んだことが報告されています。特に 早い段階でエラーを検出できた場合に、やり直しにかかる時間が最大 29% 削減 できることも確認されています8。例えば週 1 回の確認を入れれば、毎週末の手戻りを 1 件減らせる規模感です。
チェックで確認する 2 つの観点
チェックポイントに立ったとき、何を確認するかも明確にしておきます。
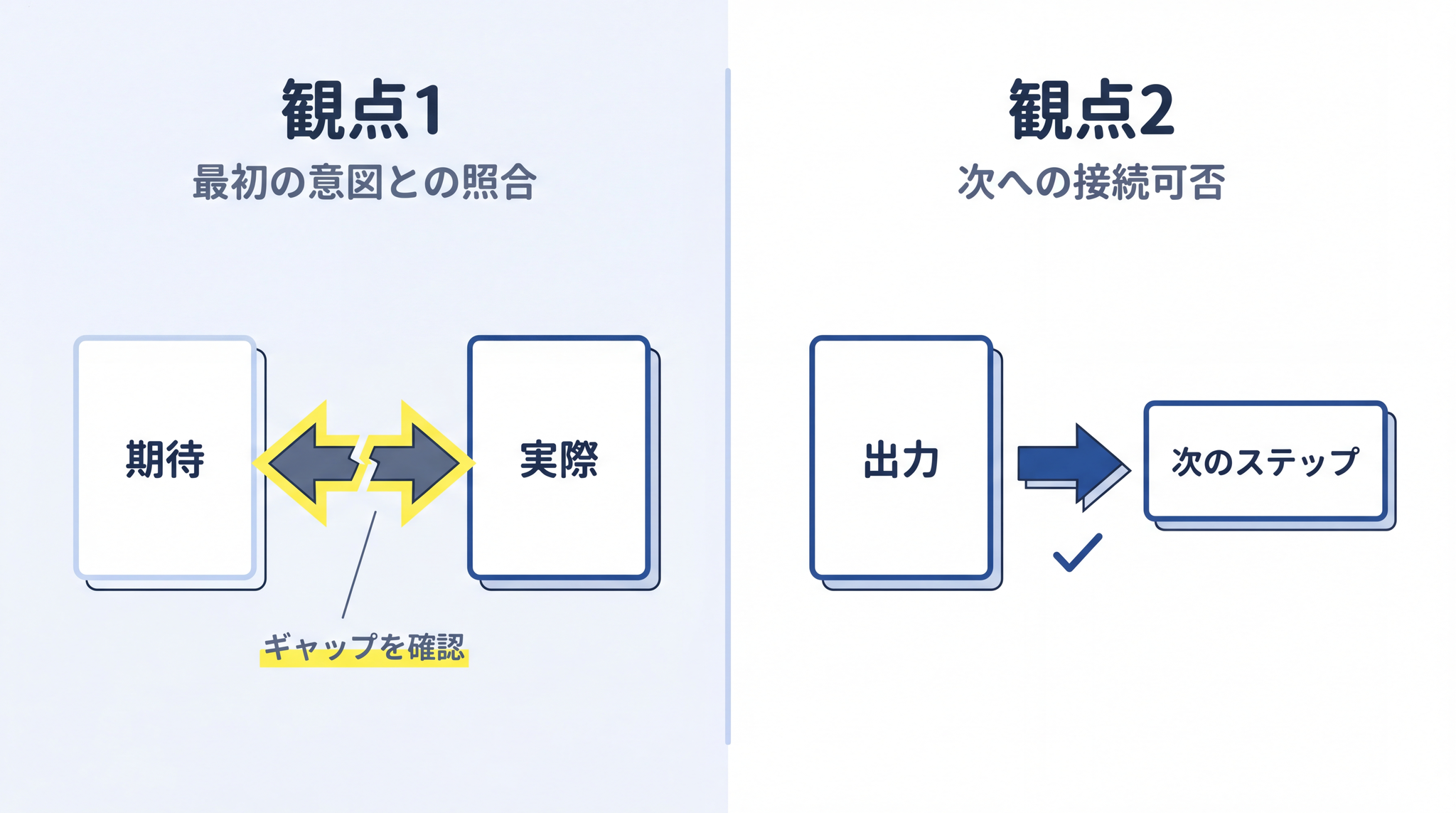
観点 1:出力が最初の指示の意図を満たしているか——「最初に何をしてほしかったか」を振り返り、実際の出力と照らします。「競合他社の強みを調べてほしかったのに、価格情報だけが出てきた」なら、ここで軌道修正します。
観点 2:次ステップの入力として使えるか——「この出力を前提に次のステップを指示したら、正しい結果が出るか」を考えます。情報の抜けや、前提となる判断の脱落がないかを確認します。
5. 長い仕事を「安全に任せる」ための設計
3 つの設計はどれも単独で使えます。出発点として最初に試すのは「段階に分けて接続する」です。連鎖が避けられない仕事なら「段階を見える化する」、前のステップに依存しない仕事なら「並列型に置き換える」を検討します。
「1 つの大きな指示」ではなく「段階に分けて接続する」
「最初から最後まで全部やって」という渡し方が崩れやすい理由は、接続部分に人間の確認が入らないからです。長い仕事を「調査フェーズ」「整理フェーズ」「分析フェーズ」に分けて、フェーズの変わり目で人間が出力を確認してから次を指示します。
各ステップの精度を高く引き出す道具として AI エージェントは優秀です。「全体の方向を保つ」という役割を、人間が担うという設計です。Anthropic は「エージェントは自律的に計画して動くが、必要に応じて情報や判断を求めるために人間のもとに戻ってくる」という設計を推奨しています7。
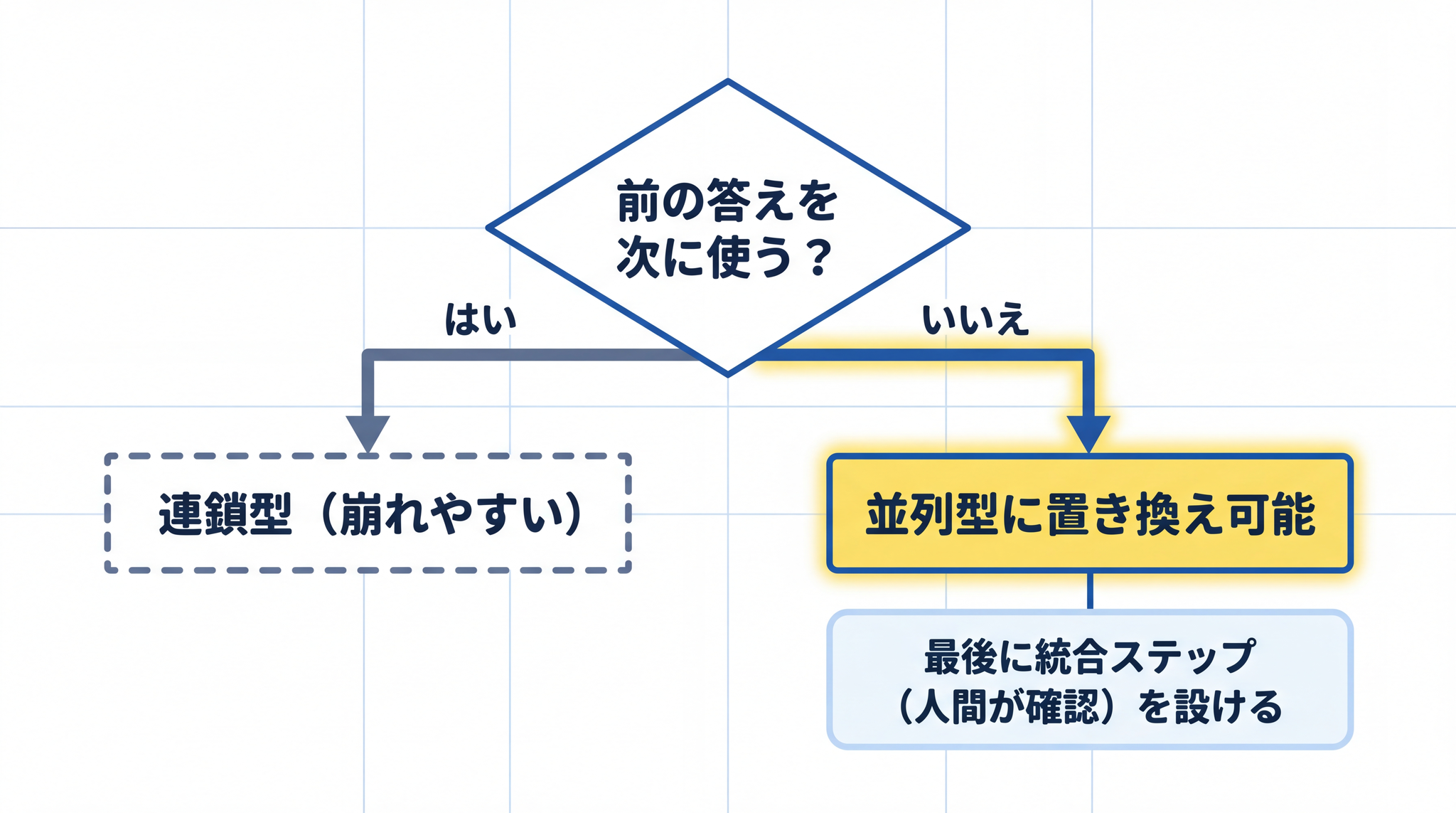
並列型に置き換えられないか検討する
連鎖型のタスクを設計するとき、「これは並列に分解できないか」を確認します。「3 社を順番に調査して次の社の調査に使う」という連鎖より、「3 社を独立して調査して最後に統合する」という並列型の方が崩れにくいです。統合ステップで人間が確認を入れれば、局所的な誤りが全体に伝わる前に止められます。
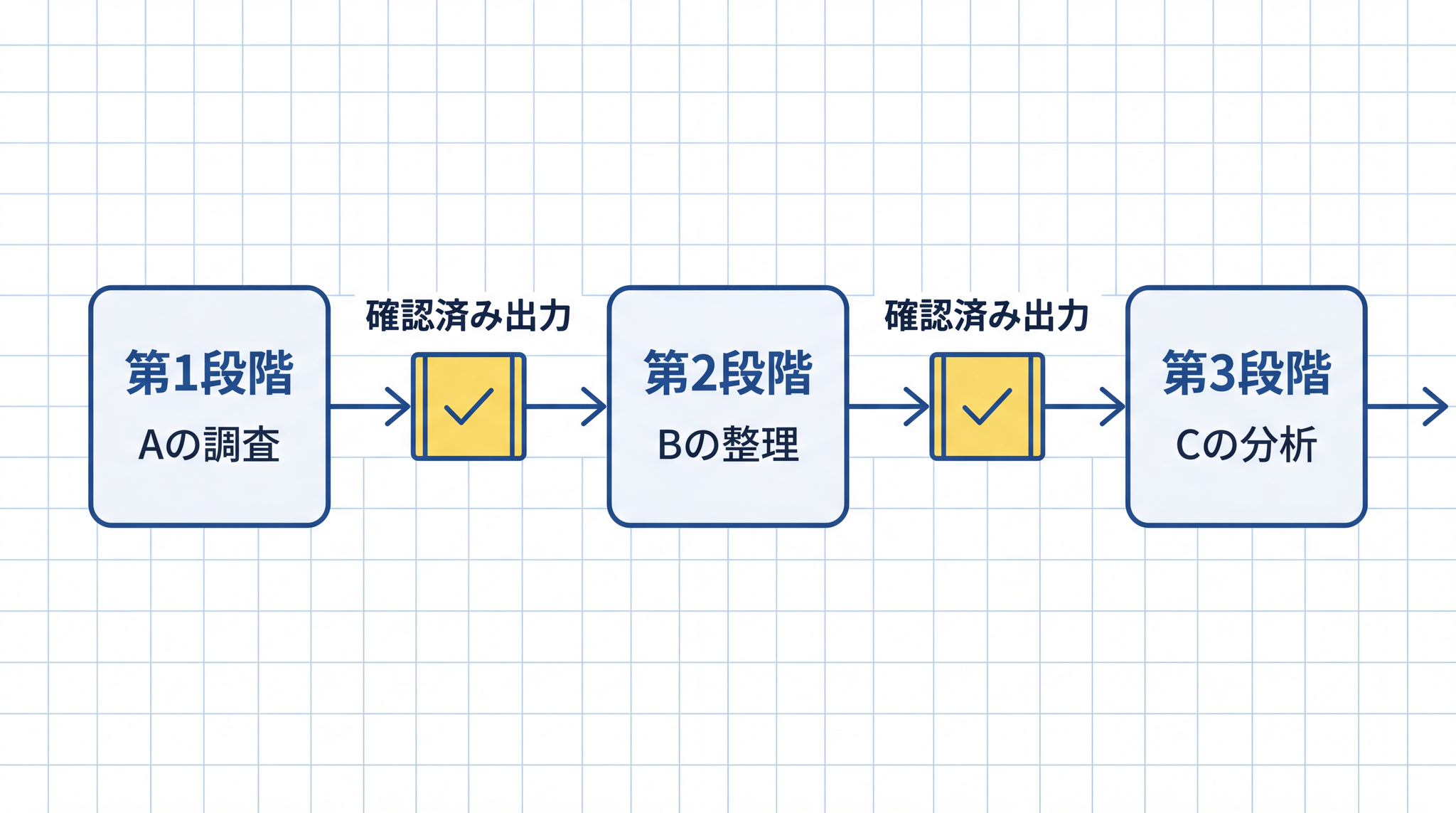
連鎖が避けられないときは「段階を見える化する」
どうしても連鎖が必要なタスクでは、段階を明示的に名前で区切ります。「第 1 段階:A の調査。終了後に出力を確認させてください」「第 2 段階:A の結果を使って B を整理する。〔A の確認済み出力を貼り付けて〕終了後に確認させてください」という形で、各段階の開始・終了を人間が管理します。
AI エージェントは「長い仕事を自動でやってくれる機械」ではなく、「長い仕事の各ステップで精度を出す道具」です。全体の設計と節目の確認は、あなたが担います。
自分の業務や日常の作業で「前の答えを使って次を考えて」という連鎖がどこにあるかを書き出してみてください。書き出せたら、週次レビューで点検箇所を 1 つ決めて翌週試してみてください。
出典・参考文献
-
Measuring AI Ability to Complete Long Software Tasks(arXiv 2503.14499)| METR ↩
-
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?(arXiv 2509.16941) ↩
-
When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs(arXiv 2406.01297) ↩
-
Harness design for long-running application development | Anthropic Engineering ↩
-
When Should Users Check? A Decision-Theoretic Model of Confirmation Frequency in Multi-Step AI Agent Tasks(arXiv 2510.05307) ↩