
AI と著作権 ── 「使っていい?」に答える 3 つの問い
目次
- 1. 「著作権の問い」を 3 つに整理する
- 2. 問い 1:AI の「学習」は著作権侵害になるか
- 2026 年 5 月時点の答え:原則として適法
- ただし書:例外もある
- 3. 問い 2:AI が生成したものを仕事や SNS で使う場合、何が問題か
- 焦点は「既存著作物との類似」
- 依拠性の判断:3 つの場合
- 「画風指定」と「キャラクター名指定」
- 各サービスの利用規約(2026 年 5 月時点)
- 実務上の確認ポイント
- 4. 問い 3:AI が生成したものの著作権は誰にあるか
- 2026 年 5 月時点の答え:AI だけが生成したものには著作権が生まれにくい
- 判断のカギは「創作的寄与」の有無
- 「著作権がない」という状態の実務上の意味
- 「規約でユーザーに権利を帰属させる」と「著作権法上の権利が発生しない」の整理
- 5. 3 つの問いの答えを一覧で確認する
- 出典・参考文献
研修で AI の話をすると、必ずといっていいほど同じ質問が来ます。
「この AI が作った画像、本当に使って大丈夫なんですか?」
「ChatGPT で作った文章を資料に使ったんですが、著作権は問題ありませんか?」
これを聞いてくるのは AI をまったく使っていない人ではありません。すでに使い始めた人から出てくる。使いながら、「大丈夫なのかな」という感覚だけが残ったまま、です。
この記事はその感覚に答えるものです。法律の条文を読まなくても、「これは問題ない」「これは要注意」を自分で仕分けできる、 判断の地図 を作ります。
ただし先に断っておきます。この記事の内容は 2026 年 5 月時点の日本著作権法と公式ガイドラインに基づいています。著作権法の解釈は判例の蓄積とともに変わりうるもので、この記事は法的アドバイスではありません。具体的な事案については、弁護士等の専門家に相談してください。
1. 「著作権の問い」を 3 つに整理する
AI と著作権のニュースが混乱しやすいのは、全部ごちゃまぜになっているからです。「AI が学習に使ったのは問題か」という話と、「AI が作ったものを私が使っていいか」という話と、「著作権は誰にある?」という話が、一緒くたに語られる。
文化庁も同じ理由で、まず「AI が著作物(著作権で守られる作品)を学習に使う段階」と「AI が生成したものを使う段階」に分けて整理しています1。
この記事では、読者の視点から問いを 3 つに分けます。
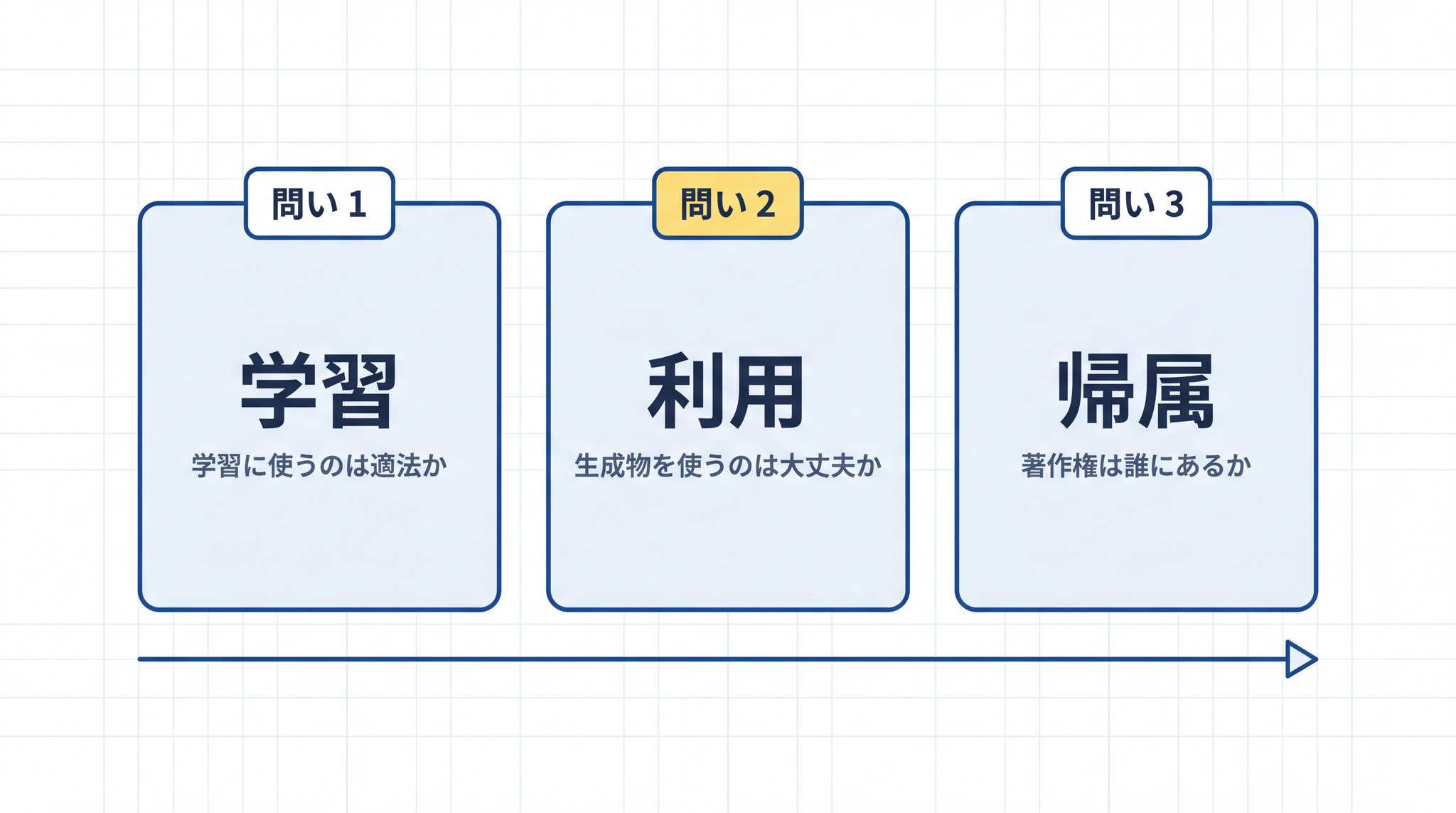
| 問い | 問いの内容 | 典型的な場面 |
|---|---|---|
| 問い 1 | AI が学習に使ったのは著作権侵害か | ネット上の画像・文章が学習データに使われていると聞いた |
| 問い 2 | AI が生成したものを使うのは大丈夫か | 生成した文章・画像を仕事や SNS に使いたい |
| 問い 3 | AI が生成したものの著作権は誰にあるか | 自分が作ったと言えるか、他人に使われても文句を言えるか |
2. 問い 1:AI の「学習」は著作権侵害になるか
この章は主に AI を開発・提供する立場の人に関係します。ChatGPT や Claude を使うだけであれば、問い 2・問い 3 が直接関係します。
2026 年 5 月時点の答え:原則として適法
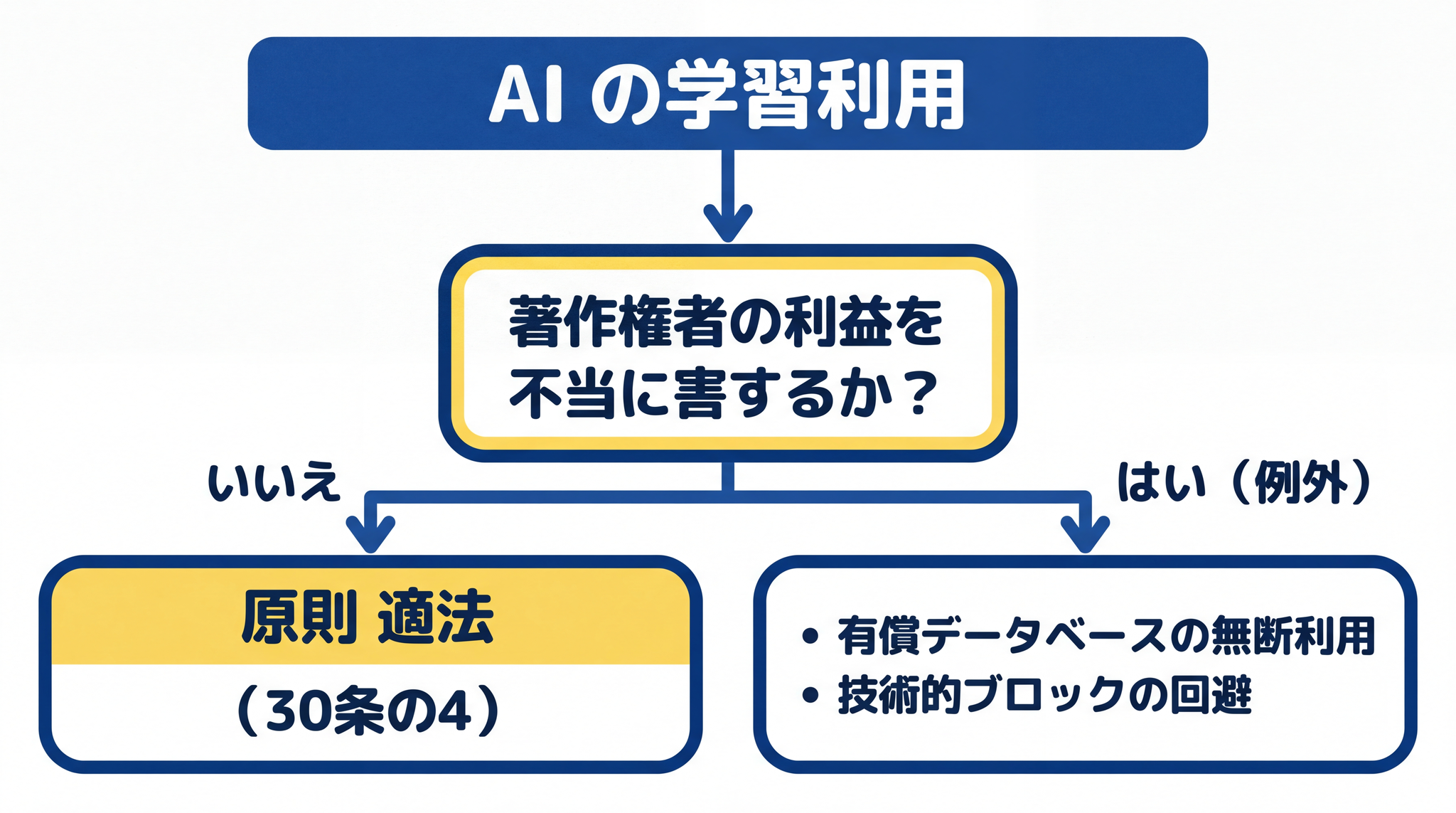
AI が著作物を学習データとして使うことは、いまの日本の著作権法では原則として「違法ではない」とされています(2026 年 5 月時点)。
根拠は 著作権法第 30 条の 4 という条文です。「著作物に表現された思想や感情を楽しむことを目的としない利用なら、権利者の許可なしに使ってよい」という内容です。
少し難しいので、身近な例で考えてみます。小説を読んで感動するのは「楽しむ」行為です。でも同じ小説を「この作家はどんな文体を使っているか」と分析するのは、楽しんでいるわけではなく、パターンを取り出す作業です。AI が大量のデータを学習するのは後者と同じ ── 言葉の並び方や画像の特徴を数値として取り出すだけで、作品を「楽しんでいる」わけではない。だから許可が不要と整理されています。
この整理のキーになる言葉が 「享受目的」 (じゅきょもくてき)です。「享受」とは「作品そのものを楽しむ・味わうこと」。AI の学習は享受目的ではない、というのが条文の考え方です。
この条文は 2018 年の改正(2019 年施行)で加わりました。AI 開発のような大量データ処理に著作権の壁を作らないという趣旨で作られました2。
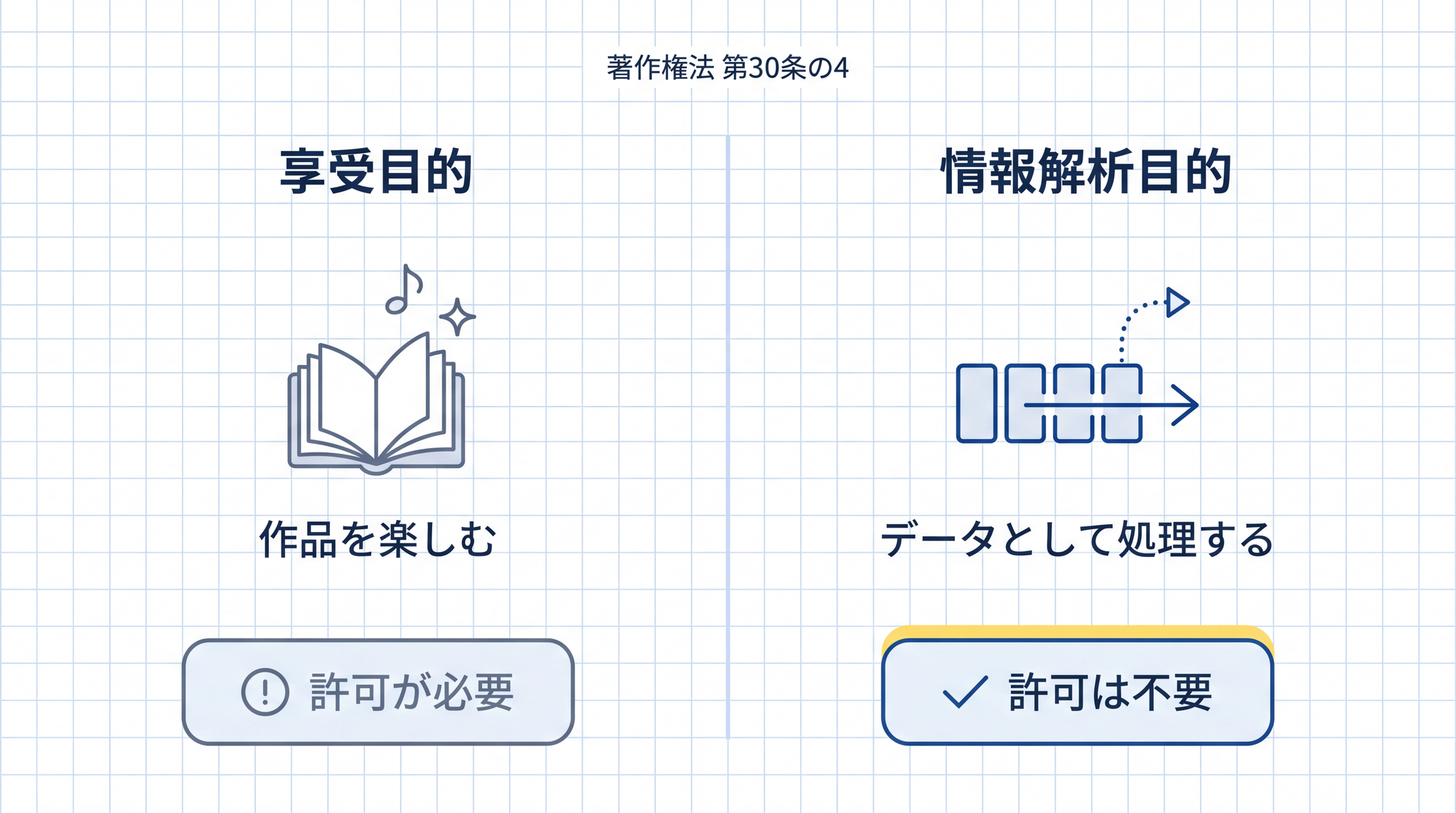
もう一つ、条文に出てくる 「情報解析」 (じょうほうかいせき)という言葉も確認しておきます。AI の機械学習は、著作権法が「情報解析」として認めている行為に当たります3。
ただし書:例外もある
条文には「ただし、著作権者の利益を不当に害する場合は例外」という除外条件があります。その文を引用すると「著作権者の利益を不当に害することとなる場合は、この限りでない」です。文化庁「AI と著作権に関する考え方について」(令和 6 年 3 月 15 日)は典型例を 2 つ示しています4。
- 情報解析用に有償提供されているデータベースを、ライセンス契約なしに収集・学習に使う行為 ── 権利者が得るはずだったライセンス収益を直接奪うため、例外に当たる可能性が高い
- robots.txt 等の技術的な制限を意図的に回避してデータを集める行為 ── 同文書のただし書の例として、意図的な回避が例外に当たりうると示されている
なお、文化庁チェックリスト&ガイダンス(令和 6 年 7 月 31 日)でも、ウェブサイト管理者の技術的なブロック(robots.txt 等)を「尊重することが望ましい」との推奨が出ています(法的義務ではなく、作り手への配慮として)5。
3. 問い 2:AI が生成したものを仕事や SNS で使う場合、何が問題か
焦点は「既存著作物との類似」
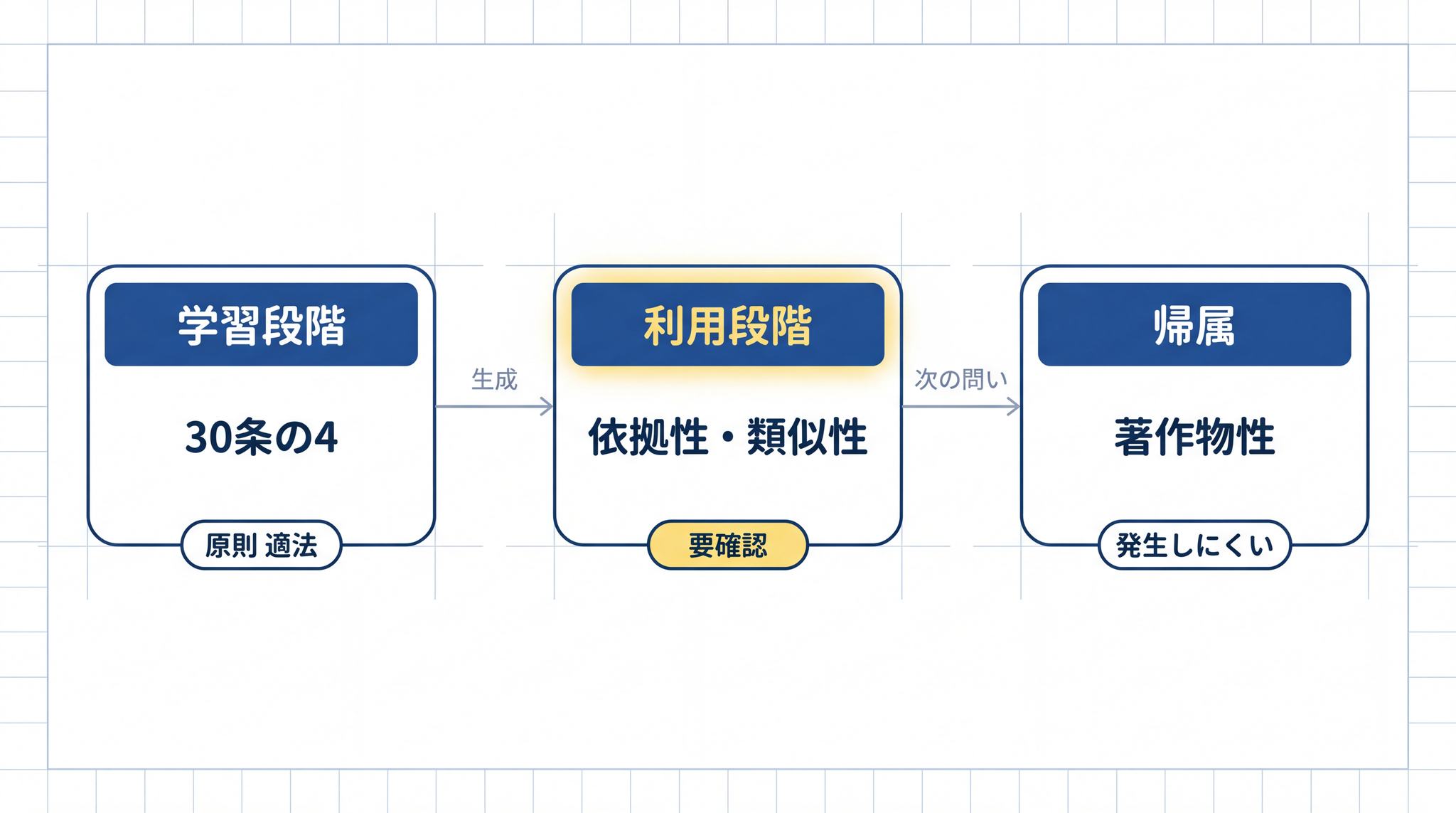
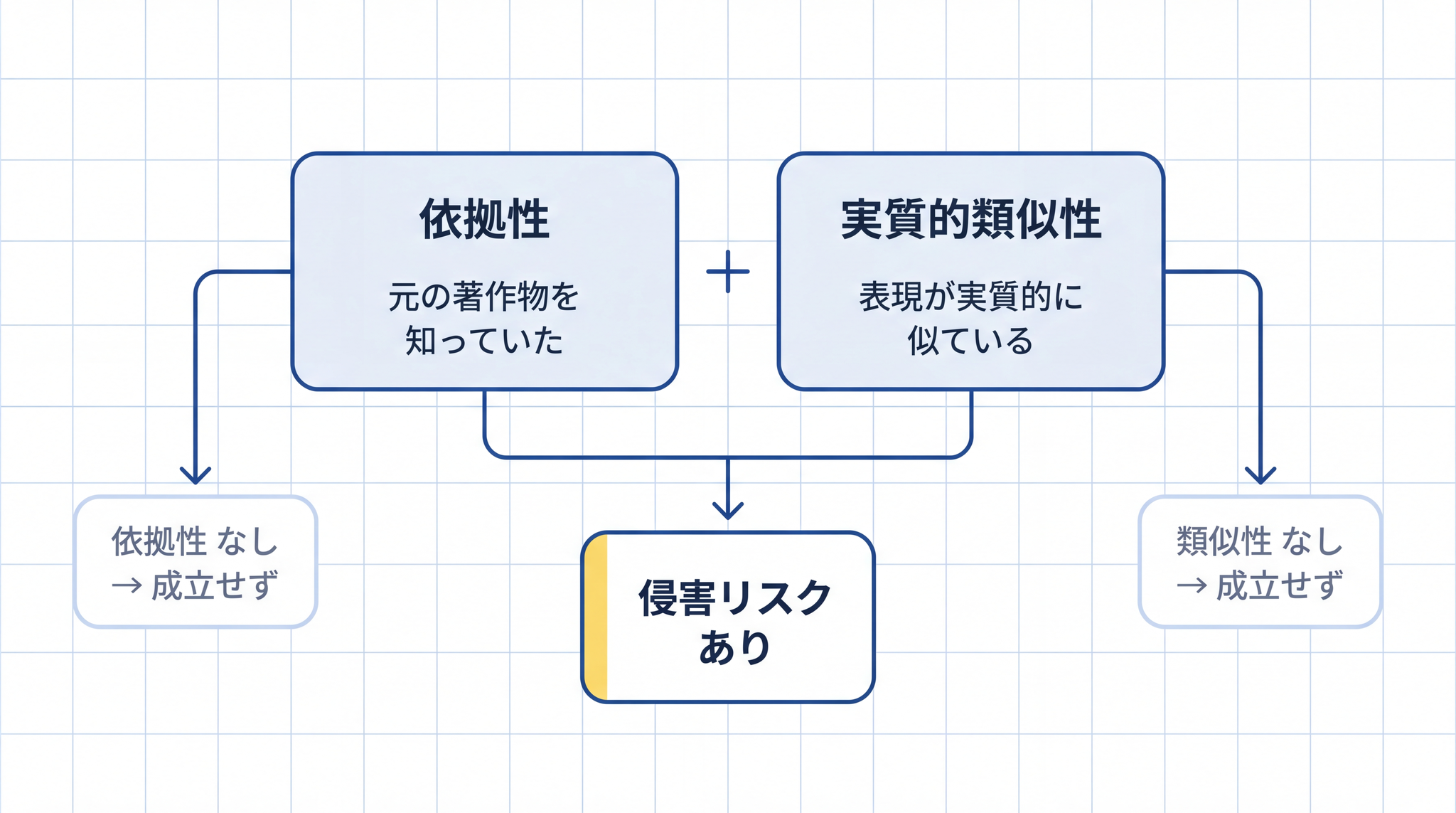
AI が作った文章や画像を公開・利用する段階では、著作権侵害の判断の見方が変わります。従来の著作権侵害と同じ 2 つのチェックポイントで判断されます4。
1 つ目が 「依拠性」 (いきょせい)。「元になる著作物を知っていて、それをもとに作ったかどうか」という確認です。知らずにたまたま似てしまった場合は依拠性がなく、著作権侵害は成立しません。
2 つ目が 「実質的類似性」 (じっしつてきるいじせい)。「既存の著作物の表現上の大事な特徴を、見る人が感じ取れるほど再現しているかどうか」という確認です。アイデアが似ていても表現が違えば類似性はあてはまりません。著作権法が守るのは具体的な「表現」であり、スタイル・画風・アイデアは保護の対象外です。
料理で例えると、依拠性は「元の料理のレシピを知っていて、それを見て作ったか」、実質的類似性は「出来上がったものが元と区別がつかないほど似ているか」です。2 つが揃って初めて「真似た」と判定されます。
AI を使ったかどうかは、この 2 つの確認の基準を変えません。
依拠性の判断:3 つの場合
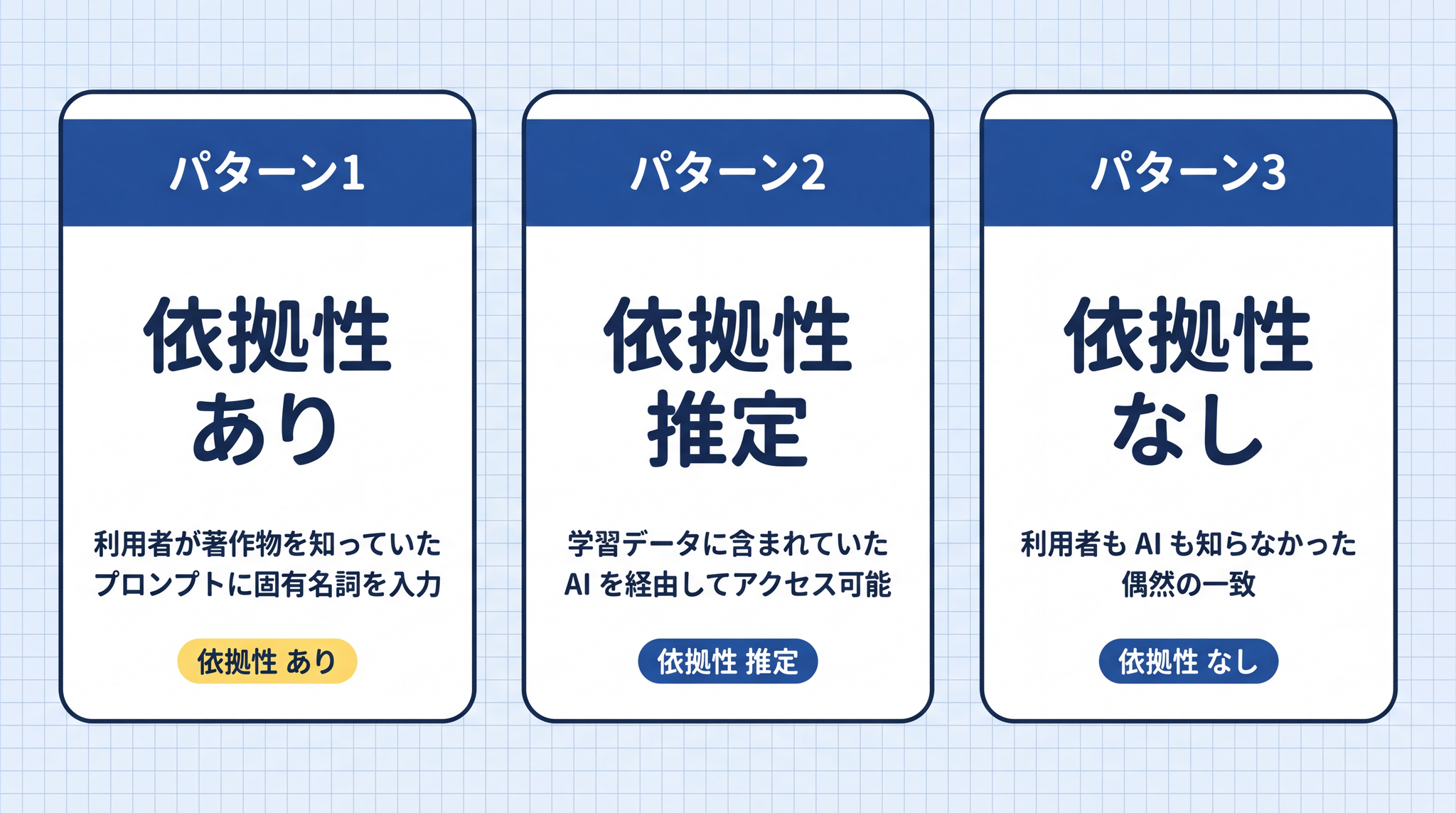
文化庁は依拠性の判断を 3 パターンに整理しています。
パターン 1(依拠性あり):利用者が既存の著作物を知っていた場合。特定の作品名・キャラクター名をプロンプトに入れた場合、または既存の画像を直接入力した場合です。知っていたことが明らかなので、依拠性が認められます。
パターン 2(依拠性が推定される):利用者は知らなかったが、AI の学習データに含まれていた場合。「AI を通じてその著作物にアクセスできる状態にあった」として、通常は依拠性があったと判断されます。反証できれば覆せる余地もあります。
パターン 3(依拠性なし):利用者も知らず、AI の学習データにも入っていなかった場合。偶然の一致として依拠性は認められず、著作権侵害は成立しません。ただしこれを証明するのは難しい場合があります。
「画風指定」と「キャラクター名指定」
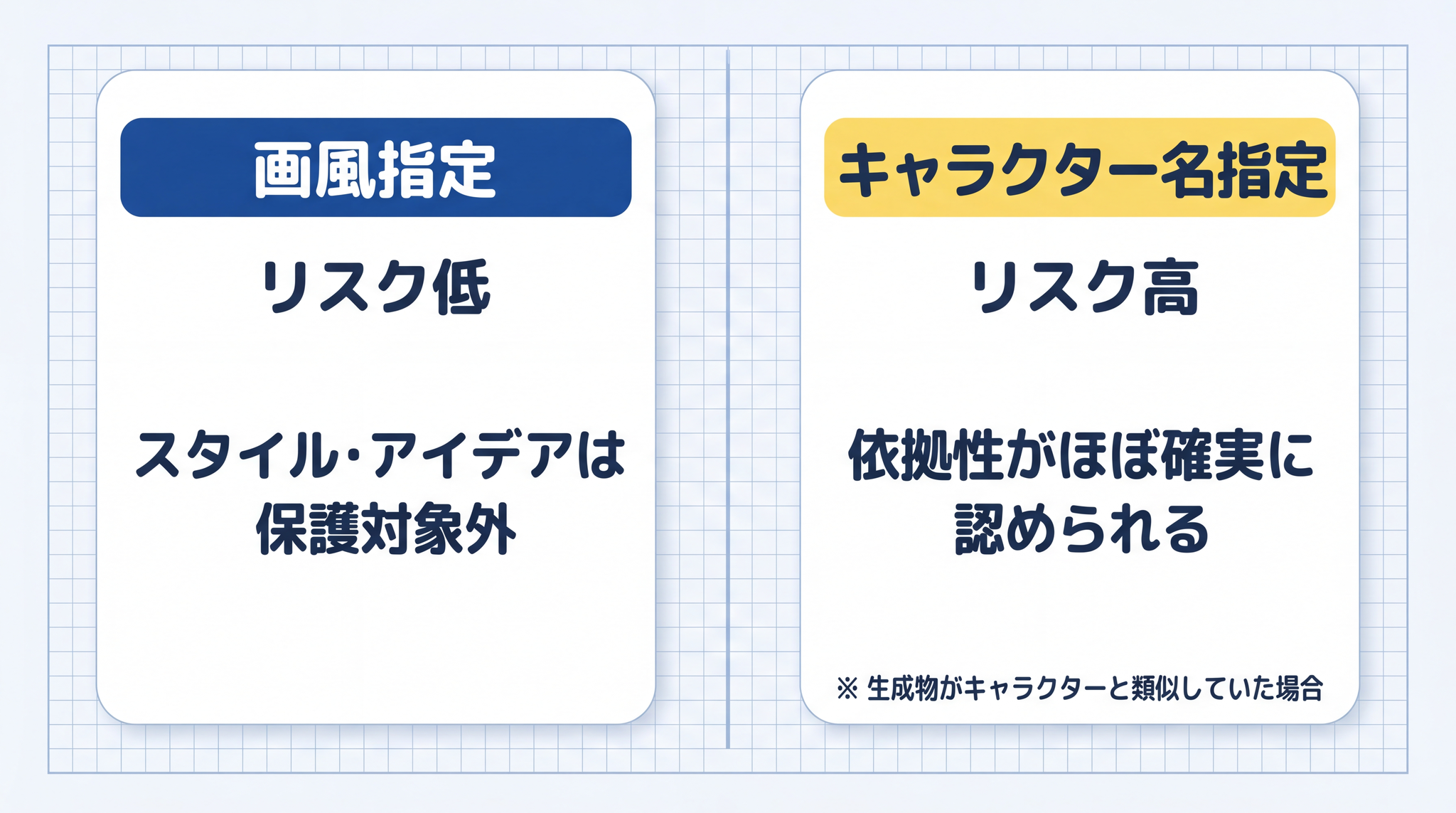
「〇〇風に」とプロンプトを入れること自体は、すぐに著作権侵害にはなりません。スタイル・アイデアは保護の対象外だからです。
一方、特定のキャラクター名(「トトロ」「ミッキーマウス」等)をプロンプトに入れて生成する場合は、依拠性がほぼ確実に認められます。生成物がそのキャラクターのデザインと似ていれば、複製権・翻案権(コピーする権利・アレンジする権利)の侵害 になる可能性が高い4。
「画風を指定する」のと「特定の著作物に似せた表現を出させる」のは別問題、と覚えておくと整理しやすいです。
各サービスの利用規約(2026 年 5 月時点)
著作権法の話とは別に、利用規約(サービスとの契約)の確認も必要です。
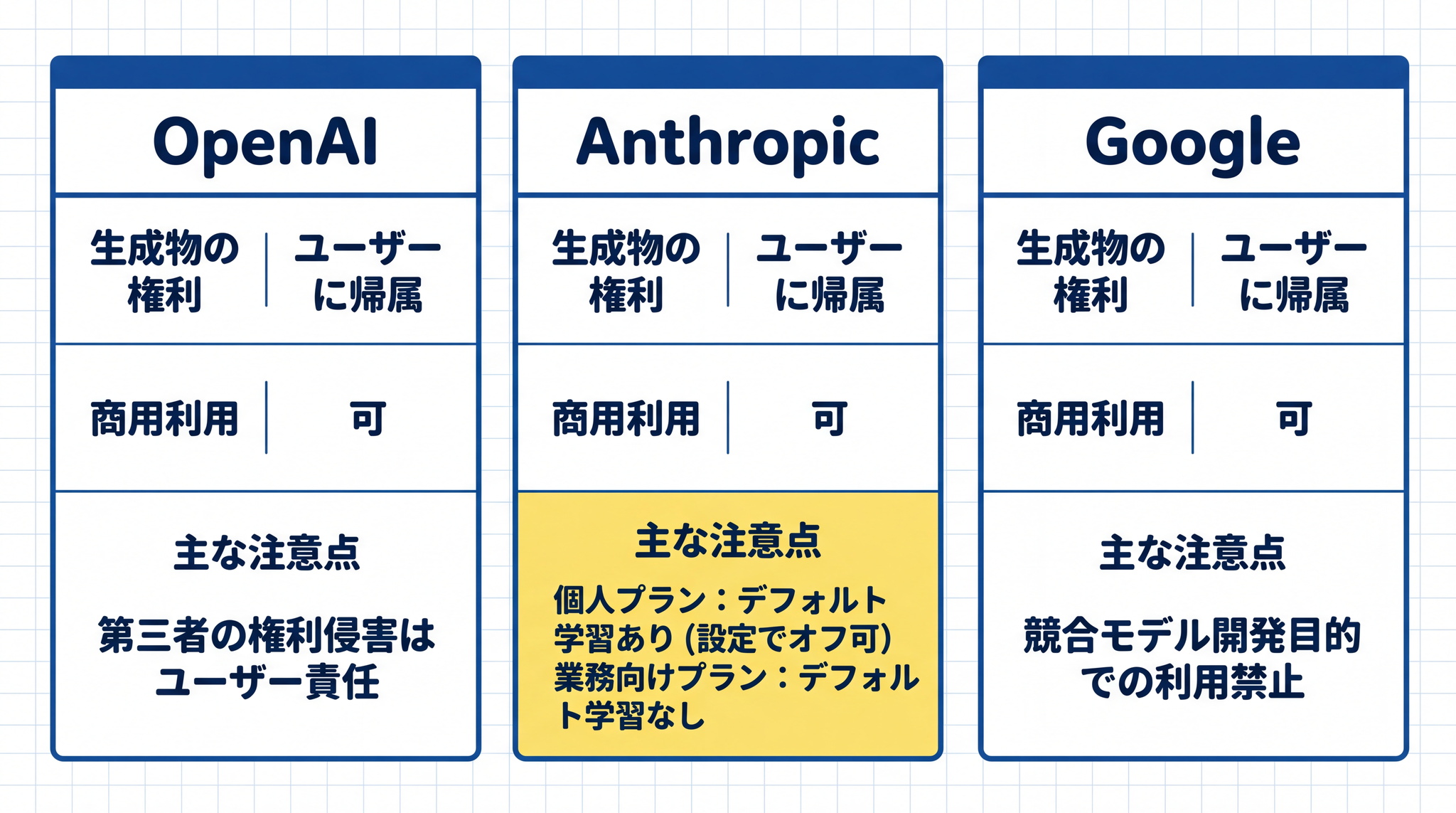
| サービス | 生成物の所有権 | 商用利用 | 主な注意点 |
|---|---|---|---|
| OpenAI(ChatGPT) | ユーザーに権利を譲渡(権利が存在する場合) | 可 | 第三者の権利侵害の法的責任はユーザーが負う6 |
| Anthropic(Claude) | ユーザーに権利を譲渡(権利が存在する場合) | 可 | 個人向けプラン(claude.ai)はデフォルトで入力内容が学習に使われる場合がある。設定から学習に使われないよう変更できる。業務向けプラン(API・エンタープライズ)はデフォルトで学習に使用しない7 |
| Google(Gemini) | Google は所有権を主張しない(ただし同一・類似コンテンツを他者に生成する権利を Google が留保) | 可 | 競合モデルの開発・学習目的での利用は禁止8 |
ここで大事な点があります。「サービスが生成物の権利をユーザーに帰属させる」と「著作権法上の著作権がユーザーに発生する」は別の話です(詳細は問い 3 で整理します)。
実務上の確認ポイント
文化庁チェックリスト(令和 6 年 7 月 31 日)は利用者向けに以下を勧めています。
- プロンプトに既存の著作物のタイトルや特定のキャラクター名等の固有名詞を入力しない
- 公開・利用前に類似画像検索ツール(Google 画像検索や TinEye など)で既存著作物と似ていないか確認する
- 万が一「似ている」と指摘された際に「偶然の一致」を説明できるよう、生成に使ったプロンプト履歴を保存しておく

4. 問い 3:AI が生成したものの著作権は誰にあるか
2026 年 5 月時点の答え:AI だけが生成したものには著作権が生まれにくい
日本の著作権法は著作物を「思想又は感情を創作的に表現したもの」と定めています(著作権法第 2 条第 1 項第 1 号3)。「創作的に表現した」の主体は「人」とされています。
AI は法律上の「人」ではないため、 AI が自律的に生み出したものには著作権が発生しない ── これが現行法の主な解釈です4。
「著作物性」 (ちょさくぶつせい)という概念があります。「その作品が著作権で守られる資格を持っているかどうか」ということです。資格があれば著作権が生まれ、他の人が勝手に使うのを止められます。AI だけで作ったものは、その資格がまず認められません。
判断のカギは「創作的寄与」の有無
著作権が生まれるかどうかのカギは 「創作的寄与」 (そうさくてききよ)── 「人間が独自の工夫・発想を加えたかどうか」── にあります。
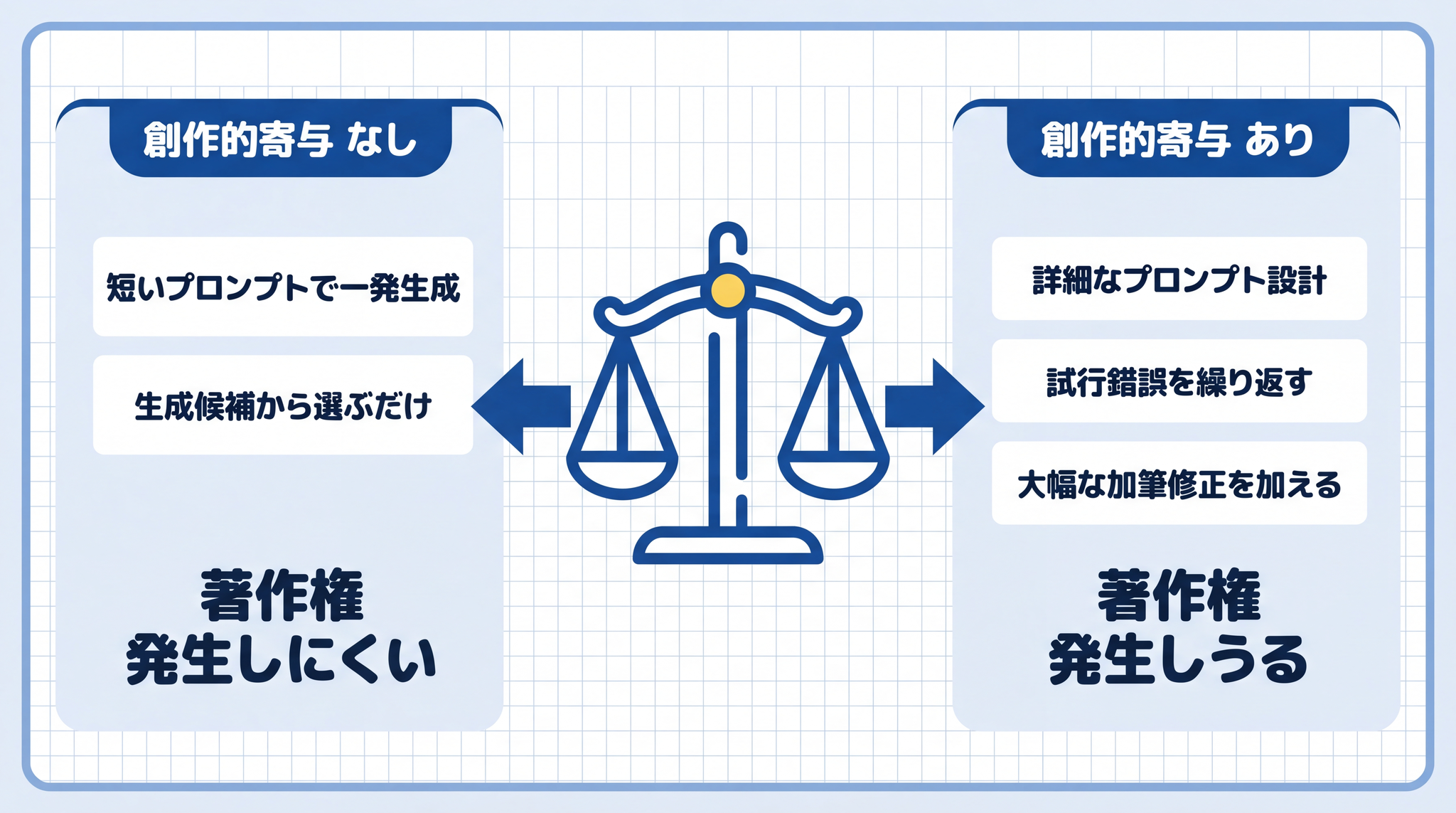
調理で例えると、AI はレシピを大量に覚えた機械です。「カレーを作って」と頼んだだけで出てきた料理は、誰の「表現」でしょうか。一方、「スパイスの配合をこうして、盛り付けはこう」と細かく指示して、試作を何度も重ねて仕上げたなら、そこには作り手の工夫がある。この違いが「創作的寄与」の有無です。
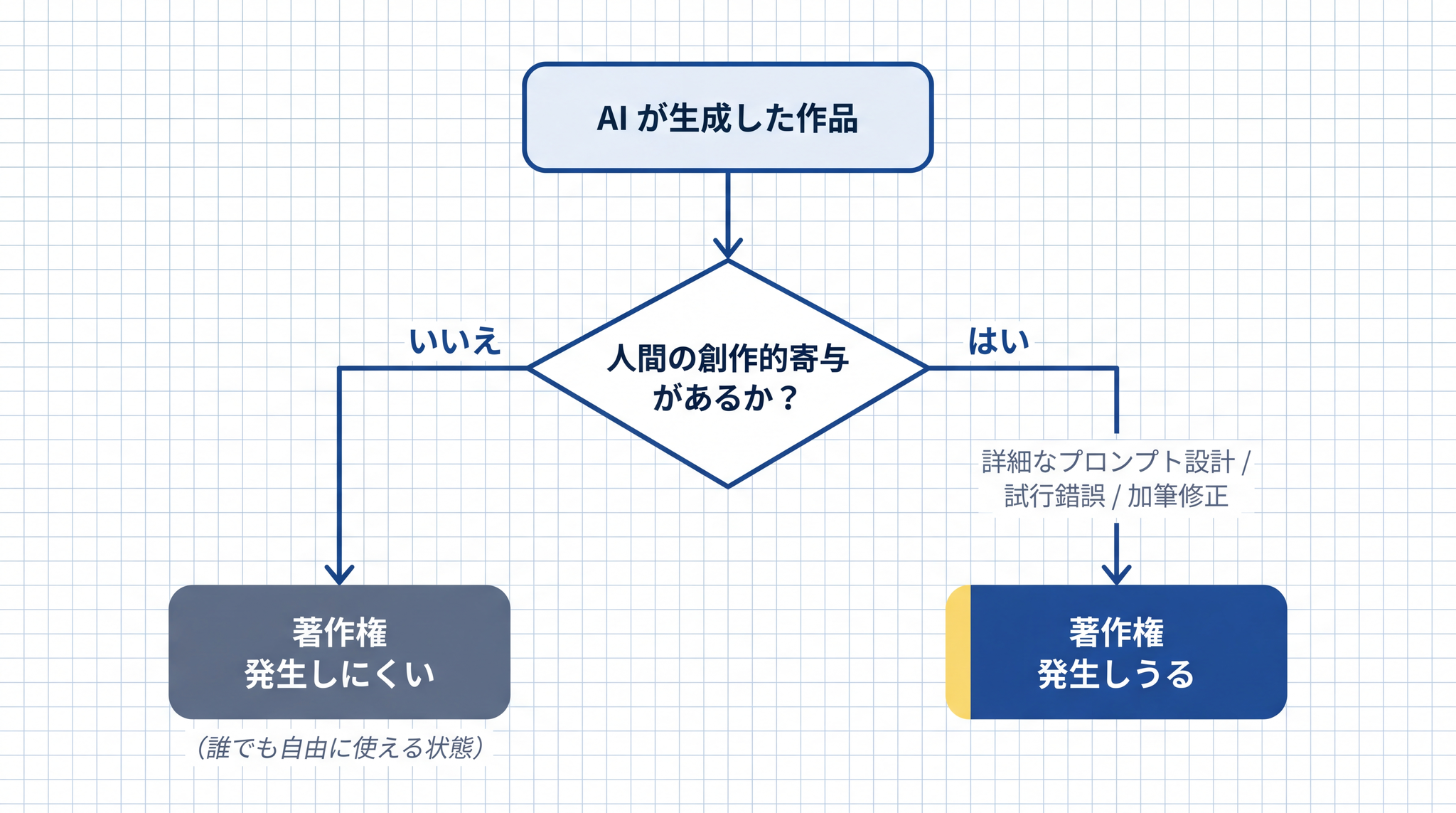
著作物性が認められにくい場合(現時点の主な解釈):
- 短い・単純なプロンプトで一発生成した場合
- 複数の生成候補から 1 つを選んだだけの場合
著作物性が認められやすい場合(現時点の主な解釈):
- 表現の内容を細かく指示した、工夫を含む詳しいプロンプトを設計した場合
- 試行錯誤を繰り返し、修正を加え続けた場合
- 生成物を素材として、人間が大幅な加筆修正・構成変更を加えた場合(「通常、著作物性が認められる」とされている)
ただし「どの程度の詳しさ・試行回数から著作権が生まれるか」の具体的な線引きは、現時点では法的に固まっておらず、判例の積み重ねが必要な領域です。
具体的なアクションは末尾のまとめ表(§5)に整理しています。
「著作権がない」という状態の実務上の意味
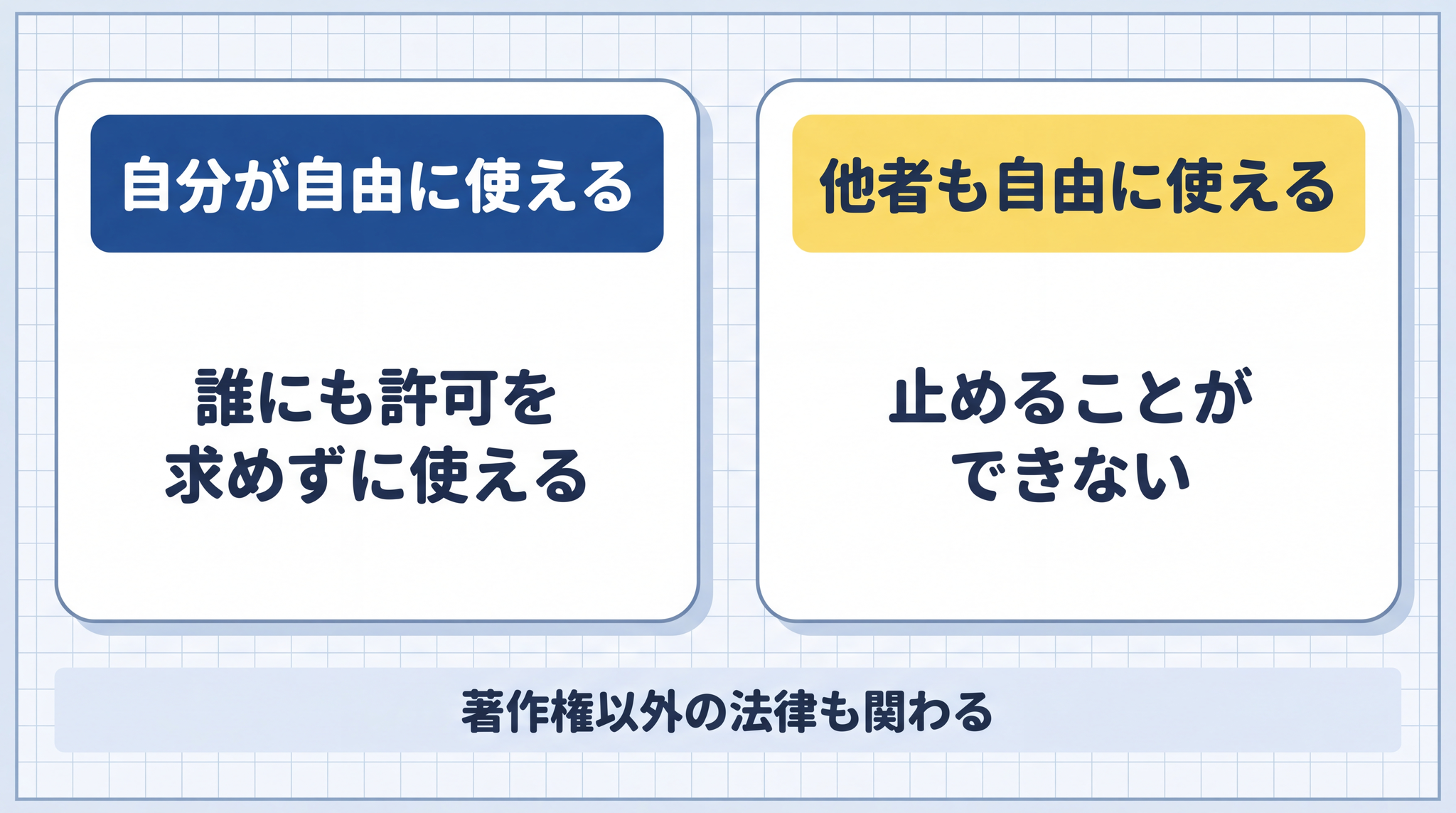
著作権が生まれない場合、自分が自由に使えると同時に、他の人も自由に使える状態になります。他の人が同じ生成物(または似たもの)を使っても、著作権では止められません。
また 「著作権が発生しない ≠ 何でもしていい」 という点も頭に入れておきたいところです。肖像権など、著作権とは別の法律が関わる問題は存在します(この記事の範囲外です)。
「規約でユーザーに権利を帰属させる」と「著作権法上の権利が発生しない」の整理
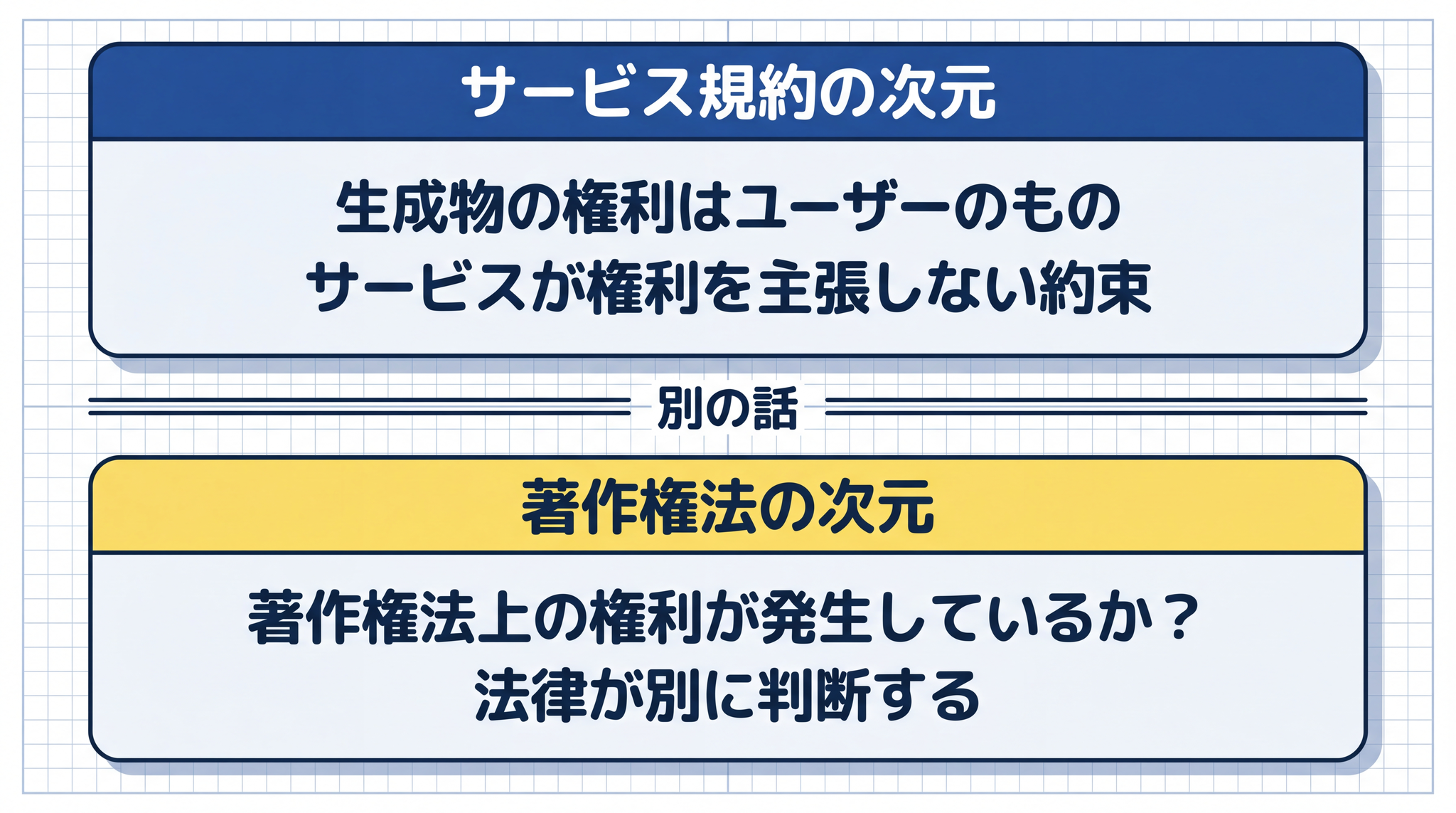
各 AI サービスは「生成物の権利をユーザーに帰属させる」と規定しています。これは「AI だけが生成したものには著作権が発生しない」という現行法の解釈と矛盾しているように見えます。
サービスが「あなたのものです」と規約で約束しても、著作権法上の権利がそもそも生まれていなければ、渡すものがない状態です。
5. 3 つの問いの答えを一覧で確認する
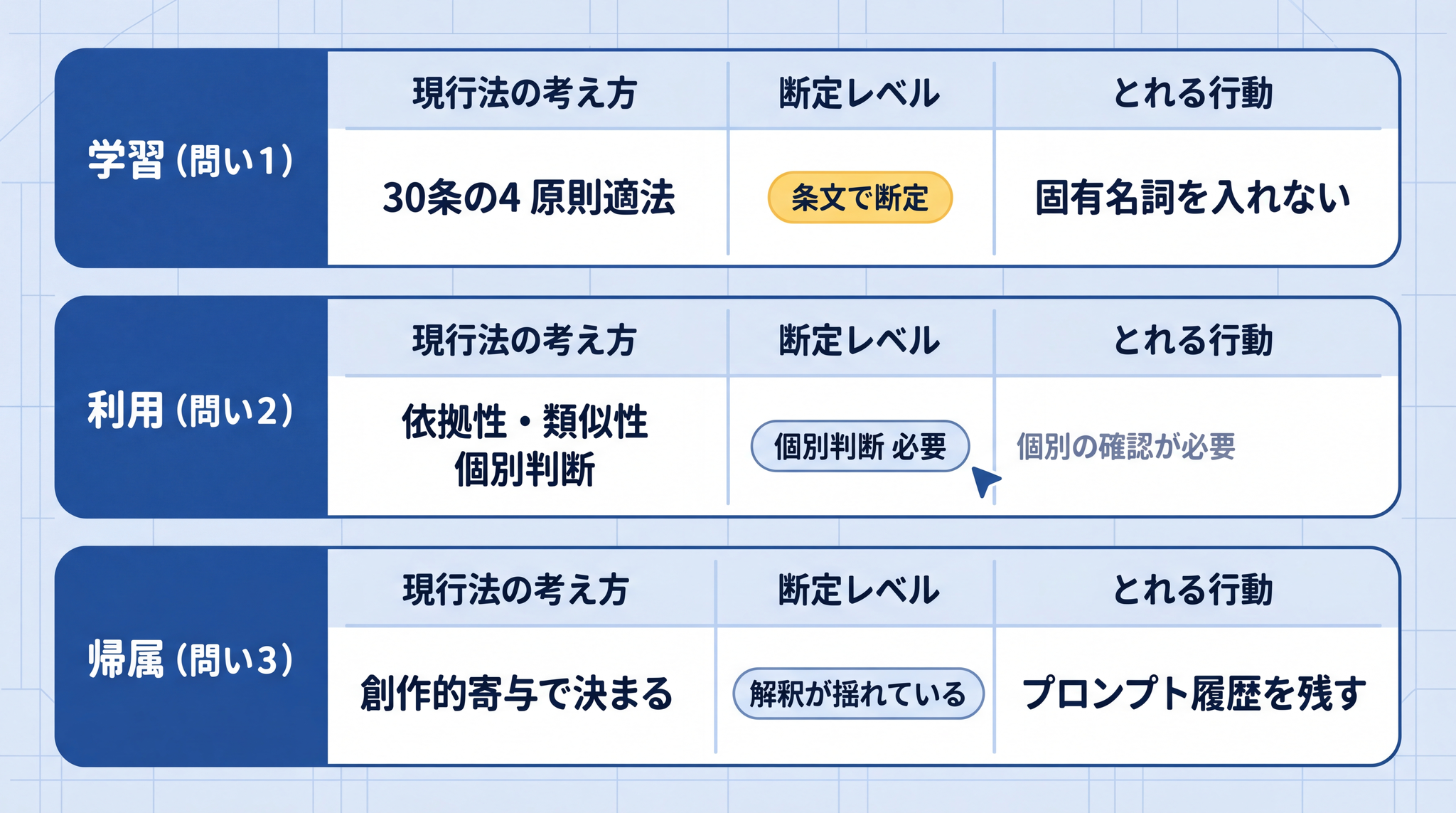
3 フレームの中身を、現行法の考え方・断定レベル・とれる行動の 4 列でまとめると次のようになります。
| 問い | 現行法の考え方(2026 年 5 月時点) | 断定レベル | あなたがとれる行動 |
|---|---|---|---|
| 学習(問い 1) | 著作権法 30 条の 4 により原則適法。ただし書(著作権者の利益を不当に害する場合)は例外 | 条文として断定できる | 有償データベースを無断学習しない。robots.txt の措置を尊重する |
| 利用(問い 2) | 依拠性 × 実質的類似性の 2 つがそろうと侵害リスク。各サービス利用規約の確認が必須 | 「要確認・要注意」のレベル。個別判断が必要 | 固有名詞・特定作品名をプロンプトに入れない。公開前に類似確認。プロンプト履歴を残す |
| 帰属(問い 3) | AI のみが生成したものには著作権が発生しにくい。人間の創作的寄与があれば発生しうる | 現時点の主な解釈。法的確定はこれから | 権利保護を期待したい場合は、詳細なプロンプト設計・試行錯誤・加筆修正の記録を残す |
著作権の問いは「全部 OK」でも「全部 NG」でもありません。問い 1 の 学習段階 は条文が整備されていて比較的クリアです。問い 2 の 利用段階 は場面によって判断が変わる。問い 3 の 帰属 は解釈がまだ揺れていて、判例の蓄積を待っている最中です。
今日まず一つやるなら、プロンプトに特定の人名・キャラクター名を入れないところから始めると、判断ミスを 1 つ減らせます。
この記事も法律の動向に合わせて更新します。「2026 年 5 月時点」という基準を頭に置きながら、ニュースや判例が出たときに「3 つの問いのどのフレームに当たるか」を確認する習慣が、判断を手放さないための一番の道具になります。
AI がいつ・何を学習しているかの仕組みは、別記事「AI はいつ学ぶのか ── 学習と推論のタイムライン」で整理しています。著作権の「学習段階」の理解がさらに深まります。AI でできること・できないことの全体像を地図として確認したい場合は、「AI でできること、できないこと ── 仕組みで整理する「地図」」が出発点になります。
出典・参考文献
-
著作権法(昭和 45 年法律第 48 号)| e-Gov 法令検索 条文上の「情報解析」の定義(第 30 条の 4):「大量の情報から、言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の統計的な解析を行うこと」 ↩ ↩2