
AI はいつ学ぶのか ── 「話せば覚える」が思い込みである、シンプルな理由
目次
ChatGPT に毎日のように話しかけているのに、昨日の話を覚えていてくれない。メモリ機能を試してみたら少し覚えてくれるようになったのに、別のチャットを開けば、また知らないふり。新しいニュースを伝えたら「私はその情報を持っていません」と返ってくる。
AI は、いったい いつ何を覚えているのでしょうか。
この違和感は、AI の性能が中途半端だから出てくるのではありません。AI の “覚え方” が、私たちの想像とまったく違うから起きています。AI の中には 2 種類の記憶 があって、私たちが普段触っているのは片方だけ。もう片方は、AI を作っているごく限られた時期にしか書き換わりません。これから、その境目を引いていきます。
1. ChatGPT に毎日話しているのに、昨日の話を覚えていないのはなぜか
多くの方が一度は引っかかる場面を 4 つ並べます。
- ChatGPT に「私の名前は田中です」と教えたのに、別のチャットを開いたら「お名前を伺ってもよろしいですか?」と聞かれる
- メモリ機能を ON にしたら、たまに名前を覚えてくれるようになった。けれど、覚えていない時もある
- 昨日のニュース(新しい AI が発表されたという話)を話しかけても、「その情報は持っていません」と返ってくる
- 取引先や家族の名前を AI に貼り付けるのは怖い。他の人の質問への答えとして出てきたら、と考えると手が止まる
4 つはバラバラの話に見えますが、全部同じ “AI の覚え方” の話です。1 行にまとめるなら、こうなります ── AI には、 書き換わらない記憶 と、 その場で渡される記憶 の 2 種類がある。
2. AI が “覚える” には、2 種類ある ── 重みと文脈
最初に、用語を 2 つだけ揃えます。
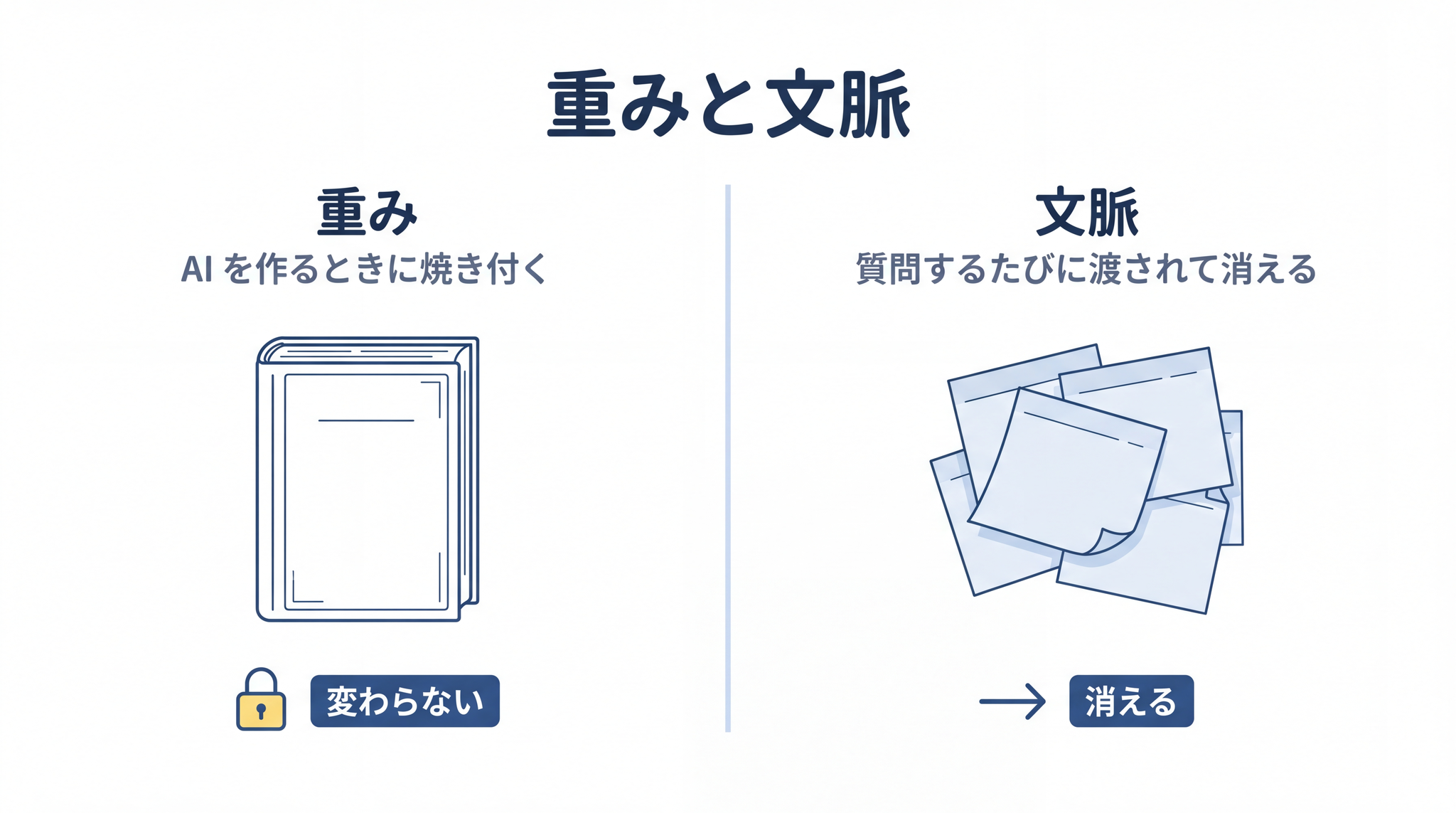
重み ── AI の頭の中で、答えを決めている数字の集まりです。料理人が長年の修行で体に染み込ませた “感覚” に近く、それを数字で表すと何千億〜何兆という量になります。「天気が」と言われたら「いい」を返しやすい、「ありがとう」と言われたら「ございます」を返しやすい ── そういうクセが焼き付いています。AI の頭の中身そのものだと思ってください。
文脈 ── あなたの質問、それまでのやりとり、添付したファイル、事前に渡しておく注意書き ── これらをまとめて、AI が答える直前に机の上に広げる “その場の文章” です。
身近なものに置き換えるなら、こうなります。
| 種類 | 比喩 | いつ書き込まれる | いつ消える |
|---|---|---|---|
| 重み | 焼き付いて固まった本 | AI を作っているとき(開発段階) | リリース後は基本的に変わらない |
| 文脈 | その場で渡される付箋の束 | あなたが質問するたび | 会話を閉じれば消える |
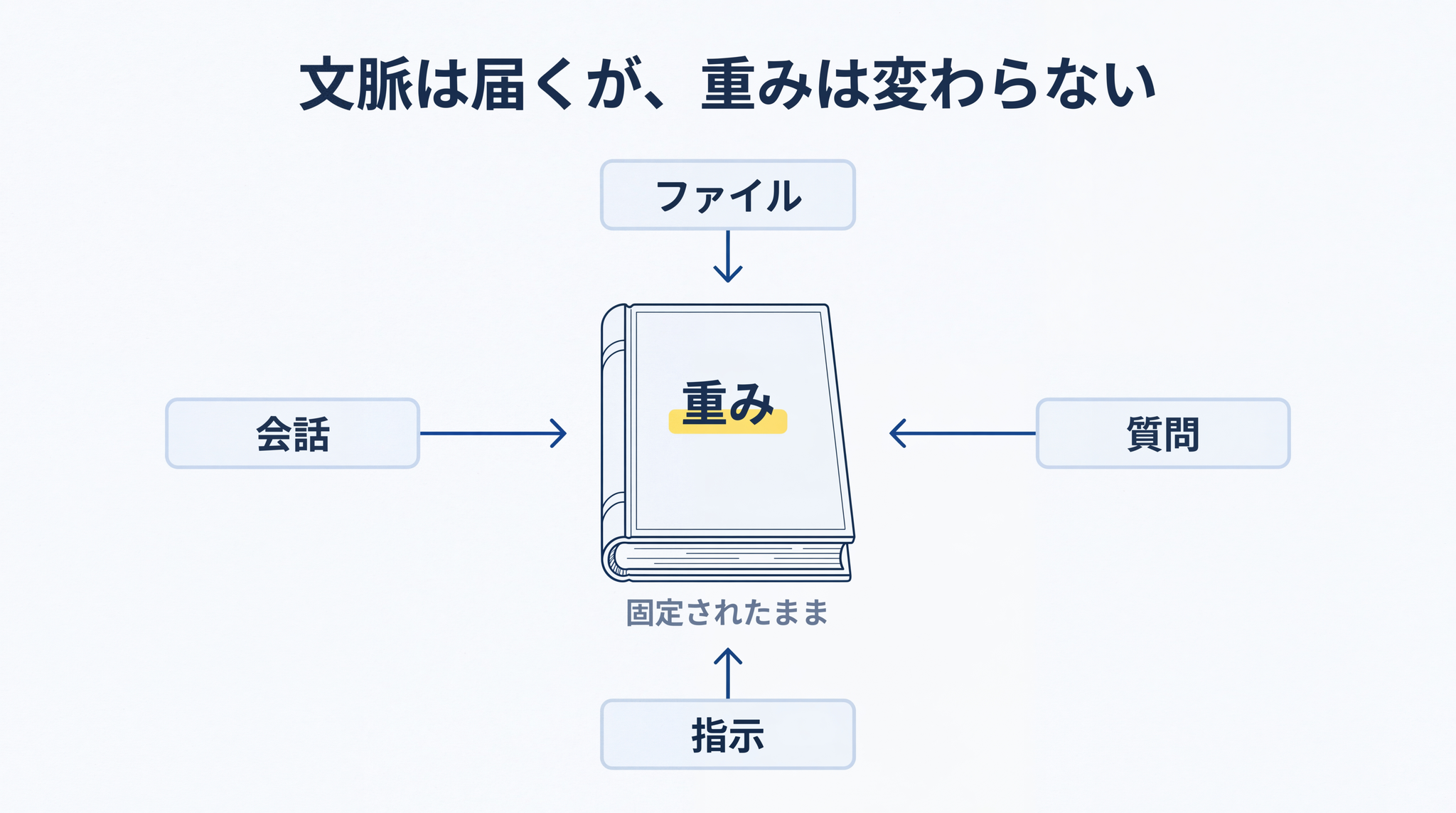
普段 AI と話して触っているのは、右側の文脈の世界だけです。あなたの質問は付箋として AI の机の上に置かれ、AI はそれを読んでから本(重み)を引いて答える。会話が終われば付箋は捨てられる。 本の中身(重み)は一字も変わらない。
なお、「書き込んだ内容が将来の AI 学習に使われるのか」というプライバシーの問いは、この重み・文脈の話とは別の軸です。確認すべきは設定画面の 3 点 ── 「学習に使う設定を外せるか」「どのプランを使っているか」「Gemini なら担当者の目が入るか」です。詳細は §6 で扱います。
「メモリ機能で AI が私のことを覚えてくれた」と感じる場面でも、起きていることは同じです。あなたの話した内容は重みに刻み込まれているのではなく、別の場所にメモとして保管されていて、次の会話のときに付箋として机の上に出されるだけ。OpenAI の公式 FAQ(よくある質問集)によると、保存されたメモリは「ChatGPT が答えを作るときに使う文脈の一部」と説明されています1。重みではなく、文脈。これがすべての章を貫く事実です。
3. AI が学ぶタイミングは、実は 3 回しかない
では、「焼き付いた本」── 重み ── は、いつ書き込まれるのでしょうか。
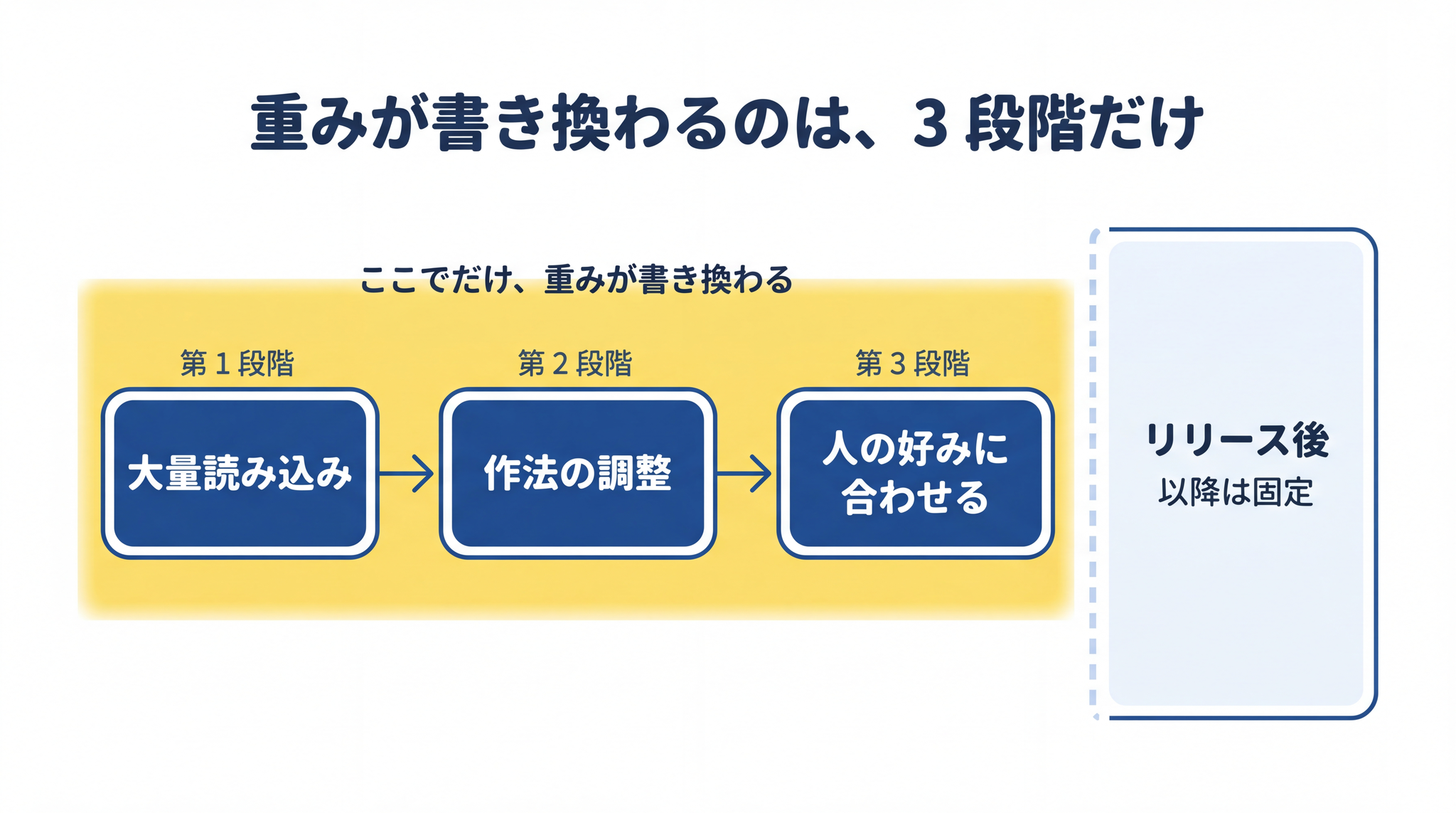
現代の主要な AI は、おおよそ 3 つの段階を経て作られています。
第 1 段階は「大量読み込み」── インターネット規模の文章を読ませて「言葉のクセ」を重みに焼き付ける、いちばん大きな学習です。
第 2 段階は「作法の調整」── 人間が用意した模範例を使って、丁寧に答える作法を整えます。
第 3 段階は「人の好みに合わせる」── 複数の答えを人間が比べて「こちらが良い」と評価し、その評価に沿うよう微調整します。
3 段階それぞれの中身は、別記事「LLM の仕組み」の §5 で扱いました。ここで覚えておきたいのは、 3 段階すべてが、AI がユーザーに公開される前に すべて終わっている という点だけです。
リリース後の AI は、あなたが何百回話しかけても、新しいニュースを伝えても、重みは一字も書き換わりません。新しい知識を持った AI が出てきたときは、開発企業が新しいモデルを作り直してリリースし直しています。
各モデルには、 学習データの締切日(英語では knowledge cutoff) があります。たとえば Anthropic は Claude Opus 4 / Sonnet 4 について、公式の Transparency Hub で「締切は 2025 年 3 月」と公表しています2。締切以降に起きたことは重みに入っていません。あなたがそのニュースを話しかけても、付箋として一時的に机の上に乗るだけです。
4. だから、あなたが話した内容は AI 本体には届いていない
冒頭で並べた 4 つの違和感のうち、3 つは、もう答えに辿り着いています。
「別のチャットでは名前を知らないふりをされた」── 別のチャットを開いた瞬間、文脈の付箋は新しい白紙に切り替わっています。重みには染み込んでいないので、白紙のチャットでは AI は何も知りません。
「昨日のニュースを話しかけても、AI が知らないと答えた」── 重みは締切以降のニュースを含んでいません。ニュースの中身を付箋として渡せば読み取って答えてはくれますが、別のチャットでは付箋がない以上「知らない」が返ってきます。
締切以降の情報を AI が “もっともらしく” 埋めようとした結果、堂々と事実と違うことを言ってしまう ── これがハルシネーション(AI が “もっともらしい嘘” をつく現象)と呼ばれるもので、別記事「ハルシネーション ── AI に『本当』の感覚が無い、という話」で扱いました。
「何度同じことを教えても、次の人にはまったく伝わらない」── 重みは書き換わっていないので、別の人が同じ ChatGPT を開いても、その人の机の上には別の白紙が広がっているだけです。
残る最後の違和感(「私の大事な情報が他の人の答えに出てくるのでは」)は、規約の話と絡みます。それが §6 のテーマです。
5. メモリ機能は “AI に教えている” のではない
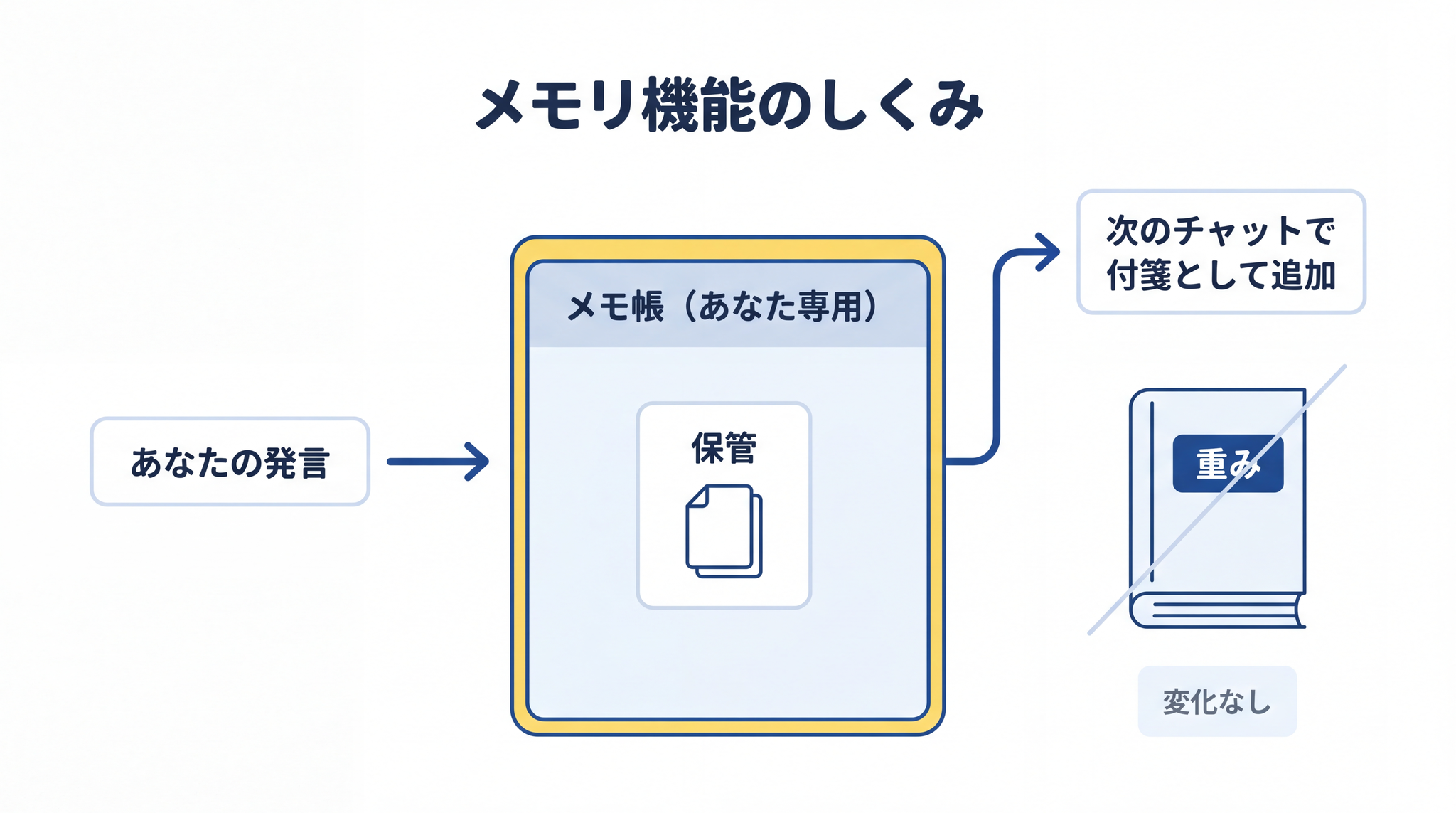
メモリ機能とは、会話の中であなたが渡した情報の一部を別の場所に保管しておき、次のチャットで付箋として机の上に出し直してくれる仕組みです。保管場所は重みの中ではなく、あなた専用の “メモ帳” のような場所です。新しいチャットを開くたびに AI がそれを読んでから答えを作ります。
OpenAI の公式 FAQ(よくある質問集)によると、保存されたメモリは「文脈の一部」です。重みの一部ではありません。AI 本体は、あなたが「私の名前は田中です」と教えたあとも、まったく賢くなっていません。次の会話で名前を呼んでくれるのは、“ユーザーの名前は田中” という付箋が、あなた専用に毎回そっと置かれているからです。
3 社のメモリ機能は、名前も画面もそれぞれ違いますが、仕組みはどれも文脈側です。
| 各社の名称 | 何を保管するか | 重みは触るか |
|---|---|---|
| ChatGPT のメモリ | 明示的に頼んだ事実、過去の会話からの推測 | 触らない |
| Claude のメモリ | 会話をまたいで自動で作られるまとめ(全プランで利用可) | 触らない |
| Gemini の “Saved info” | 明示的に保存させた情報、過去の会話履歴 | 触らない |
「メモリで AI が完全に私の専属になる」と思うと、実態とずれます。
過去のチャットから保存された内容は、ChatGPT が「より役に立つ」と判断した内容に応じて時間とともに入れ替わります。明示的に保存した「メモリ」は消すまで残りますが、過去の会話から自動で取り込まれた情報は変わることがある ── OpenAI の公式 FAQ がそのことを認めています3。メモリ機能を ON にしているのに別チャットで名前が抜け落ちるのも、この仕組みによるものです。
同じ発想をもっと積極的に拡張し、手元の文書を丸ごと文脈として読ませる仕組みが RAG(外部資料を引く仕組み)です。詳しくは別記事「AI に教科書を渡してから聞く ── 自分の文書を答えに使わせる方法」で扱います。
6. 「では、私が話した内容はどこへ行くのか」── プライバシーの境目
「自分が入力した情報は、AI の学習に使われているのですか?」── AI の研修で必ずと言っていいほど出てくる質問です。答えはサービスによって大きく異なります。
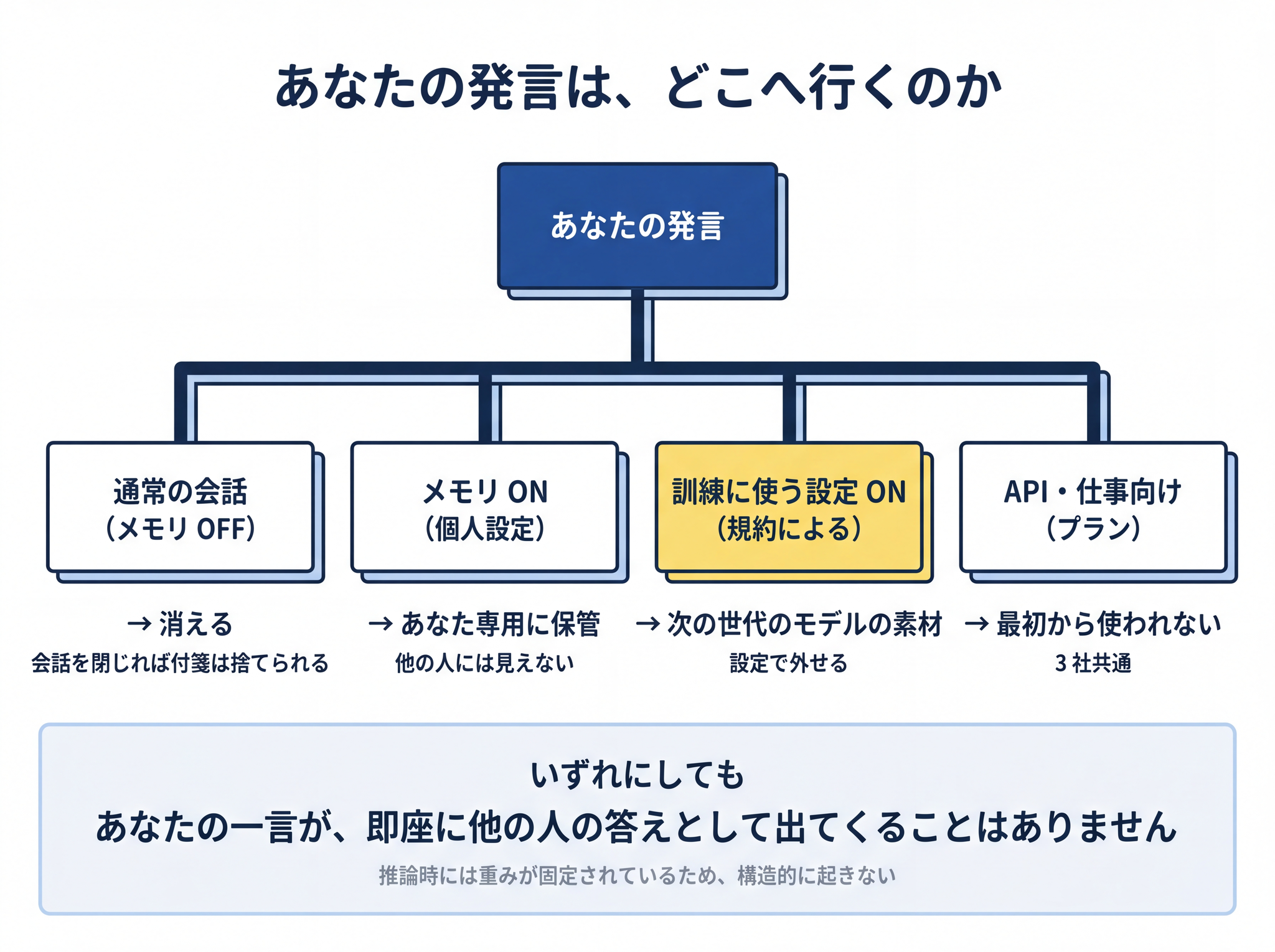
あなたが ChatGPT に取引先や家族の名前を貼り付けても、その瞬間に AI 本体(重み)に染み込むことはなく、他の人の答えとして即座に出てくることもありません。
問題は、もう一段先にあります。あなたの会話が、次の世代のモデルを作るときの素材として吸収される可能性です。ここからは規約の話になります。
3 社の現状(2026 年 5 月時点)をまとめます。 規約は半年単位で変わる ので、この記事を読まれた時点で最新の各社公式ページを確認してください。
表の「API・法人プラン」列は、企業や開発者向けの契約形態です。個人で無料・有料プランを使っている場合は「通常利用」列だけ見れば十分です。
| サービス | 通常利用(無料・個人)でデフォルト学習に使われるか | API・法人プラン(参考) | 学習を外す方法 |
|---|---|---|---|
| ChatGPT | 使われる | 使われない | 設定画面の Data Controls で外す |
| Claude | 原則は使われない(明示的に許可した場合だけ) | 使われない | プライバシー設定(変更履歴あり) |
| Gemini | 使われる(人間の担当者が読む可能性あり) | 使われない(API) | 設定画面の Keep Activity を OFF |
ChatGPT(OpenAI)── 個人利用は使われる、設定で外せる。無料・Plus・Pro では最初の状態だと会話が学習の対象に入ります。設定画面で「Improve the model for everyone」を OFF にすれば、それ以降の会話は対象外になります4。Team・Enterprise・API では最初から使われません。
Claude(Anthropic) ── 公式プライバシー FAQ によると、「個人データを学習に使うことを積極的に目指していない。あなたが許可した場合に限って使うことがある」とされています5。API や Claude for Work などの仕事向けプランでは、原則として学習には使われません。
Gemini(Google)── Google のプライバシーポリシーによると、Google およびサービス提供者の担当者が収集したデータの一部を確認することがあります6。 書いた内容を別の人が見うる という点は、大事な情報を扱う前に知っておきたい事実です。設定画面の Keep Activity を OFF にすると、以降の会話は学習に使われず、人の目も入らなくなります。Gemini API は最初から学習には使われません。
1 つだけ、誤解を解いておきます
「学習に使われる = 私の発言が、そのまま他のユーザーの画面に出てくる」── これは違います。学習に使われるとは、次の世代のモデルを作るときの大量のデータの一粒として混ざるという意味です。あなたが書いた文章が他人の答えにそのまま出てくることは、ふつうの利用では起きません。AI が答えを返すとき重みは固定されているため、そういう仕組みになっていないからです。
判断の基準はこう整理できます。
- 目の前の会話で AI が何かを覚えてくれる ── 文脈の話。会話を閉じれば消えるか、メモリ機能であなた専用に保管されるか
- あなたの発言が、未来の AI に影響しうる ── 規約の話。設定で外せる。半年単位で変わる
- あなたの一言が、即座に他人の答えに出てくる ── 起きません(AI が答えるときには重みが固定されているため)
大事な情報の扱いに迷ったら、「設定で外す」「仕事用プランや API を使う」「そもそも貼らない」の選択肢を取るのが堅い判断です。

場面ごとに何を先に確認するか
「重み・文脈・規約」の 3 軸が分かったところで、よくある場面に当てはめてみます。
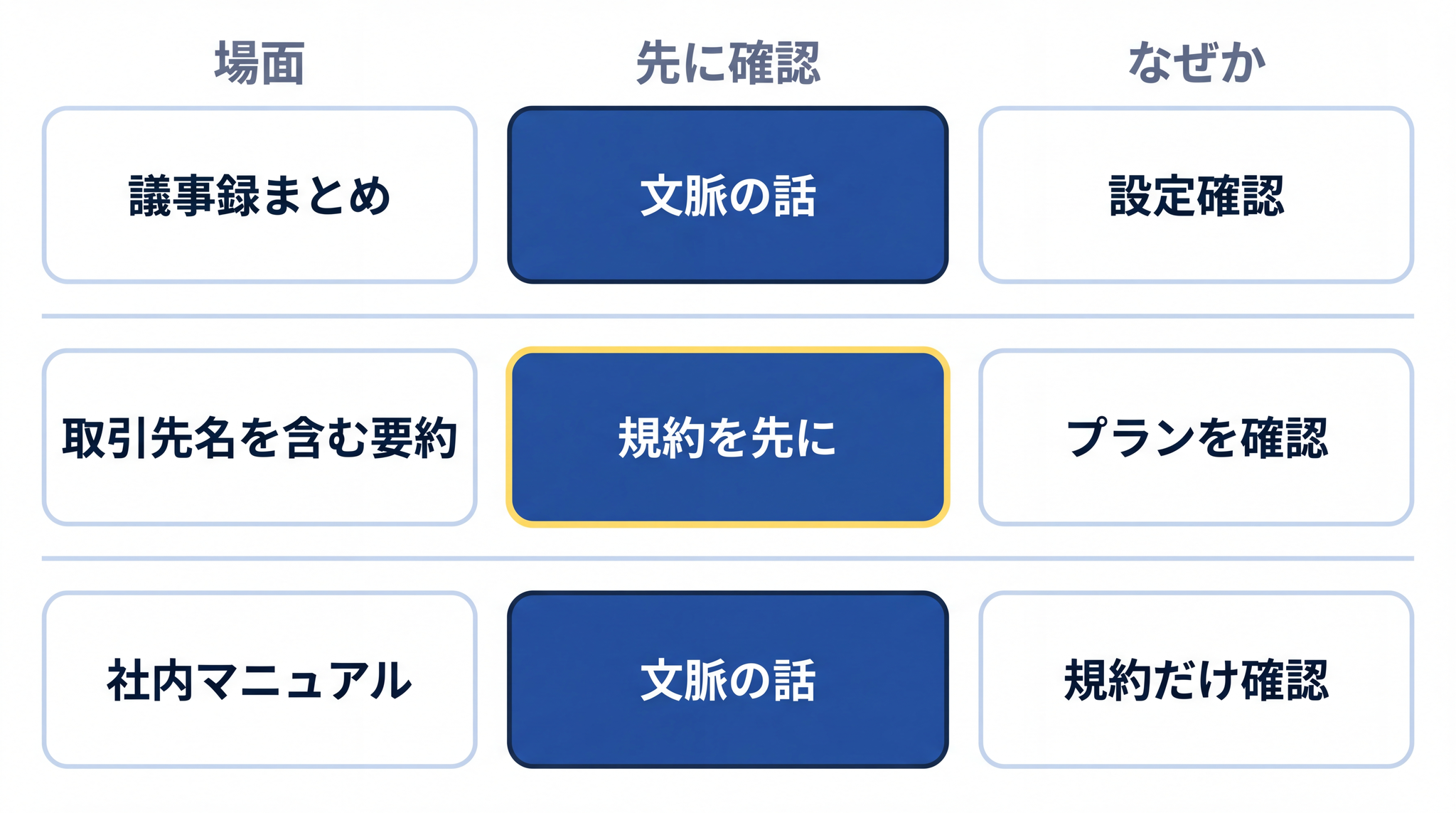
議事録をまとめさせる ── これは文脈の話です。会議の内容を貼り付けて要約させれば、AI はその場で読んで答えを返します。会話を閉じれば消えます。ただし、参加者名や案件名を貼ったまま学習設定が ON になっていると、将来のモデルの素材に混ざる可能性があります。先に設定画面の「チャット履歴をトレーニングに使う」を OFF にしてから使い始めると安心です。
取引先や顧客名を含む文を要約させる ── 規約を先に確認します。使っているプランが学習対象かどうか、Gemini であれば担当者の目が入るかどうか。個人の無料プランのまま使っている場合は、名前の部分を「A 社」「B 様」のように置き換えてから渡すのが現実的な折衷案です。まず設定画面で「チャット履歴をトレーニングに使う」を OFF にして、それから渡す順番で動くと安全です。
社内マニュアルや手引きを読ませて質問に答えさせる ── 文脈の使い方として理にかなっています。ファイルを貼り付けて「この内容に基づいて答えてください」と指示すると、AI は付箋として読みます。重みには入らないので、「マニュアルの中身が外部に漏れる」ことは起きません。注意するのは規約だけです。設定画面の学習 OFF を確認してから使い始めれば、内容が次世代モデルの素材に混ざるリスクも下げられます。
3 つに共通するのは、「重みには届かない」という事実を前提に、文脈の扱い方と規約の設定だけ確認すれば動き出せる、という点です。
7. 判断軸 ── これは “重みの話”? それとも “文脈の話”?
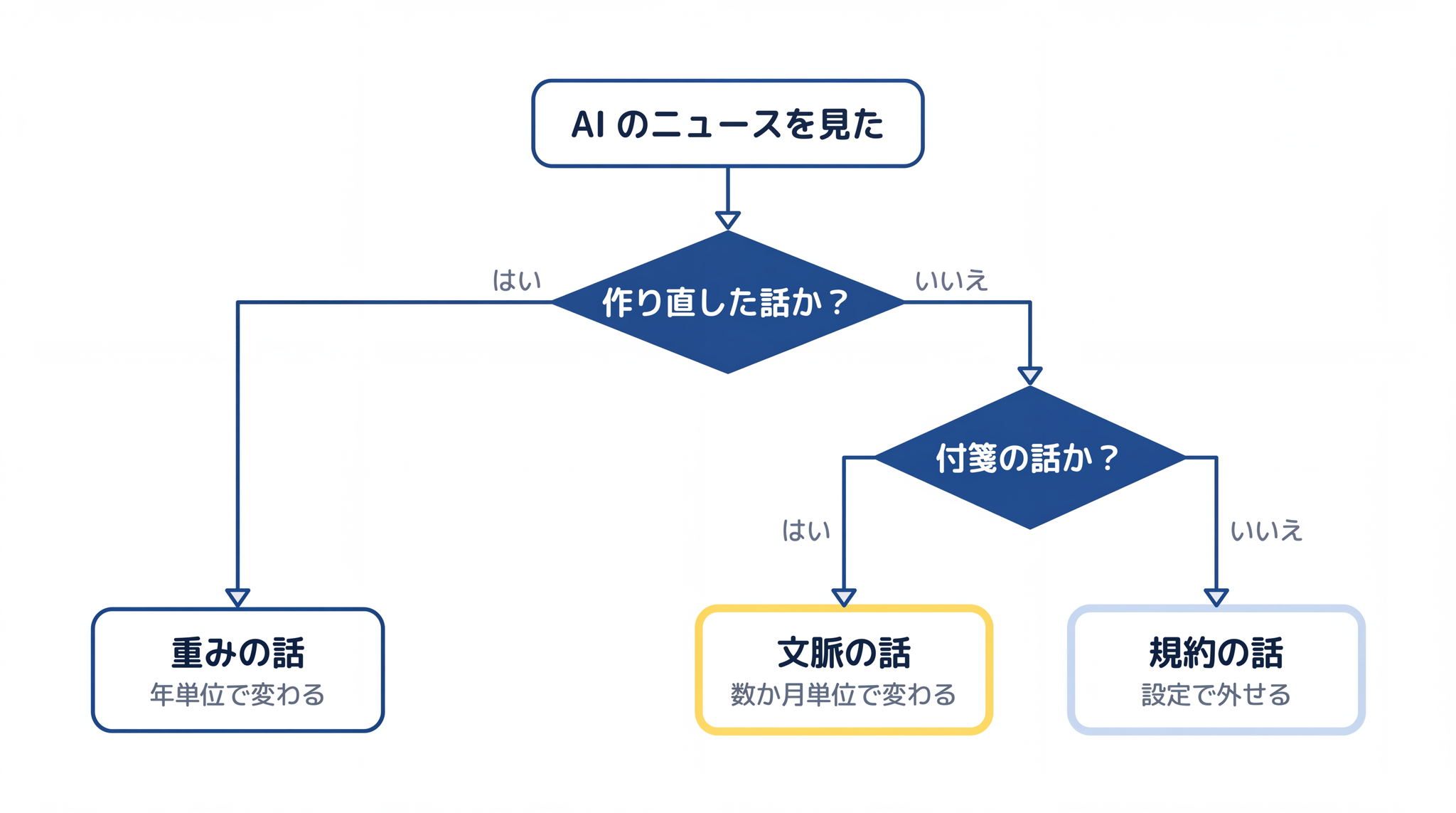
これから目にするニュースや機能の変化は、ほとんどすべて “重みの話” か “文脈の話” のどちらかに分類できます。迷ったとき、こう問い返せます。
「これは、AI を作り直したという話か? それとも、AI の机の上に置く付箋の話か?」
| よく見る話題 | 重みの話?文脈の話? |
|---|---|
| 「ChatGPT が新しい機能でメモリを覚えるようになった」 | 文脈(あなた専用の付箋) |
| 「Claude が新世代モデルをリリース」 | 重み(作り直し) |
| 「Gemini が手元のファイルを読んで答えるようになった」 | 文脈(その場の付箋) |
| 「OpenAI が新しい RAG 機能を発表」 | 文脈(外部情報を付箋に) |
| 「学習データの締切が 2025 年に伸びた」 | 重み(新世代モデルの話) |
| 「会話を学習に使う設定がデフォルトで OFF になった」 | 規約(次世代モデルの素材) |
重み側の話は年単位で変わります。新しいモデルが出るという形でしか変化しません。文脈側の話は数か月単位で次々と進化します。各社のメモリ機能、ファイル読み込み、検索接続、エージェント機能 ── これらはすべて文脈側の道具です。
冒頭の 4 つの違和感は、ぜんぶ同じ “覚え方の境目” の話でした。重みは固定、文脈は毎回リセット、プライバシーは設定で外せる ── この 3 点が頭に入れば、「AI が学習する」というニュースも重みの話か文脈の話かに振り分けられます。
境目さえ見えれば、AI は怖くなくなります。まず §6 の設定確認から始めると、すぐに動けます。
関連リンク
- 学習で AI の重みに何が焼き付くのか、もっと深く知りたい方へ:「LLM の仕組み ── 同じ問いに違う答えが返ってくる、その理由」
- 各社の “育て方” の違いが、なぜ性格の差になるのか:「ChatGPT・Claude・Gemini はなぜ違うのか ── コンビニ・職人・科学者でつかむ」
- 重みに無い情報を AI がもっともらしく埋めてしまう仕組み:「ハルシネーション ── AI に『本当』の感覚が無い、という話」
- 文脈側の道具を使って、手元の文書を AI に答えさせる方法:「AI に教科書を渡してから聞く ── 自分の文書を答えに使わせる方法」
- AI でできること、できないことの全体地図:「AI でできること、できないこと ── 仕組みで整理する『地図』」