LLM の仕組み ── 同じ問いに違う答えが返ってくる、その理由
目次
- 1. 「同じ質問なのに、答えが違う」── 一番気になる現象から
- 2. 「決まり通り動くソフト」と「確率で言葉を選ぶソフト」
- 2-1. 決まり通り動くソフト
- 2-2. 確率で言葉を選ぶソフト
- 2-3. どちらもプログラムで、違うのは動かし方
- 3. 「次に来る単語を予測する」だけで、なぜ会話できているように見えるのか
- 3-1. 確率分布 ── 候補に点数が付いている
- 3-2. これを文の終わりまで繰り返す
- 3-3. ただし「次に来る単語を予測する」が LLM の仕組みのすべてではない
- 4. AI は何を見て予測しているのか ── 文脈と「言葉の最小単位」
- 4-1. トークン ── 言葉の最小単位
- 4-2. コンテキストウィンドウ ── 会話を覚えていられる範囲
- 4-3. 注意機構 ── どの単語にしっかり目を向けるか
- 5. AI はどうやって「賢く」なったのか ── 学習の 3 段階
- 5-1. 第 1 段階:本を大量に読ませる(事前学習)
- 5-2. 第 2 段階:お手本を見せて真似させる
- 5-3. 第 3 段階:人間の好みで磨く
- 6. 「言葉だけ」じゃない ── 画像・音声も「予測」で扱える(マルチモーダル)
- 6-1. 画像を「見る」── 同じ予測の仕組みに合流する
- 6-2. 画像を「作る」── ここからは別の仕組み
- 7. 仕組みが見えると、AI に何を任せるべきかが分かる
- 7-1. なぜ毎回違う答えが返るのか
- 7-2. なぜ AI は「自信満々で嘘をつく」のか
- 7-3. 新しいモデルが出ても、判断軸は古びない
- 7-4. 任せてよいこと、要確認なこと
- 7-5. 仕組みが分かると、AI が怖くなくなる
- 出典・参考文献
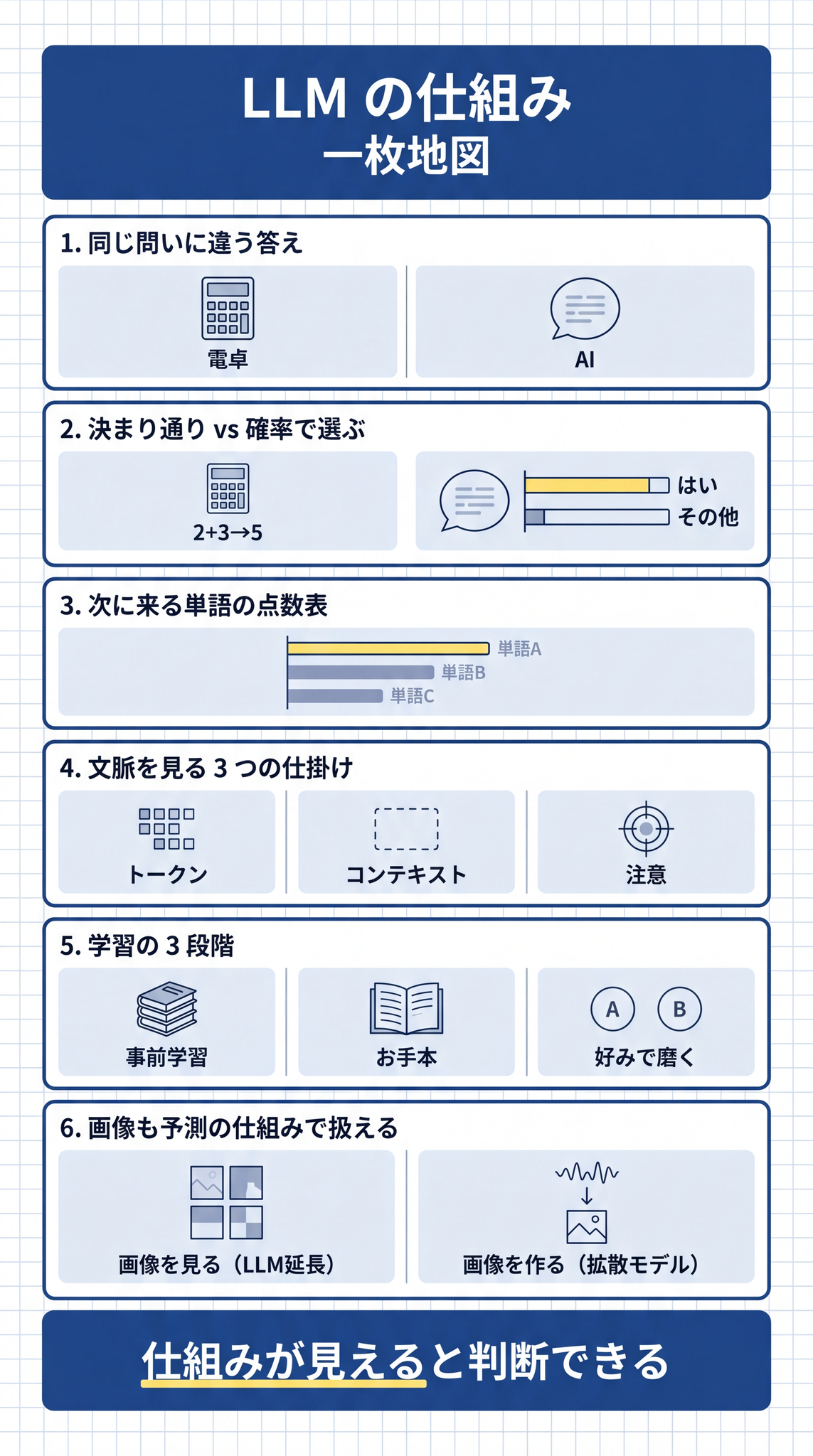
ChatGPT に 同じ質問を 2 回 すると、毎回少しずつ違う答えが返ってきます。実際に触ったことがある方なら、気づいているかもしれません。エクセルや電卓では絶対に起こらないことです。これは “バグ” ではなく、 AI の仕組みそのもの から自然に出てくる動作です。
「毎回違う」が どこから来ているのか を、AI の中で何が起きているかをたどりながら解きほぐします。仕組みが見えると、AI が嘘をつく理由も自分の言葉で説明できます。何を任せて何を任せないかも、自分で判断できるようになります。
1. 「同じ質問なのに、答えが違う」── 一番気になる現象から
ChatGPT を一度でも触ったことがある方なら、もしかしたらこんな経験があるかもしれません。
「昨日と同じ質問をしたのに、今日は違う答えが返ってきた」 「もう一度送り直してみたら、また少し違う文章になっていた」
これは、あなたの操作ミスでも、AI のバグでもありません。 仕組みがそうなっている からです。
エクセルのマクロ、電卓、自動販売機 ── これらは同じボタンを押せば、必ず同じ結果が返ってきます。100 円玉を入れて缶コーヒーのボタンを押せば、缶コーヒーが出る。これが多くの方が「コンピュータ」と聞いて思い浮かべるイメージだと思います。
ところが ChatGPT、Claude、Gemini のような AI は、そうではありません。毎回少しずつ違う答えを返します。
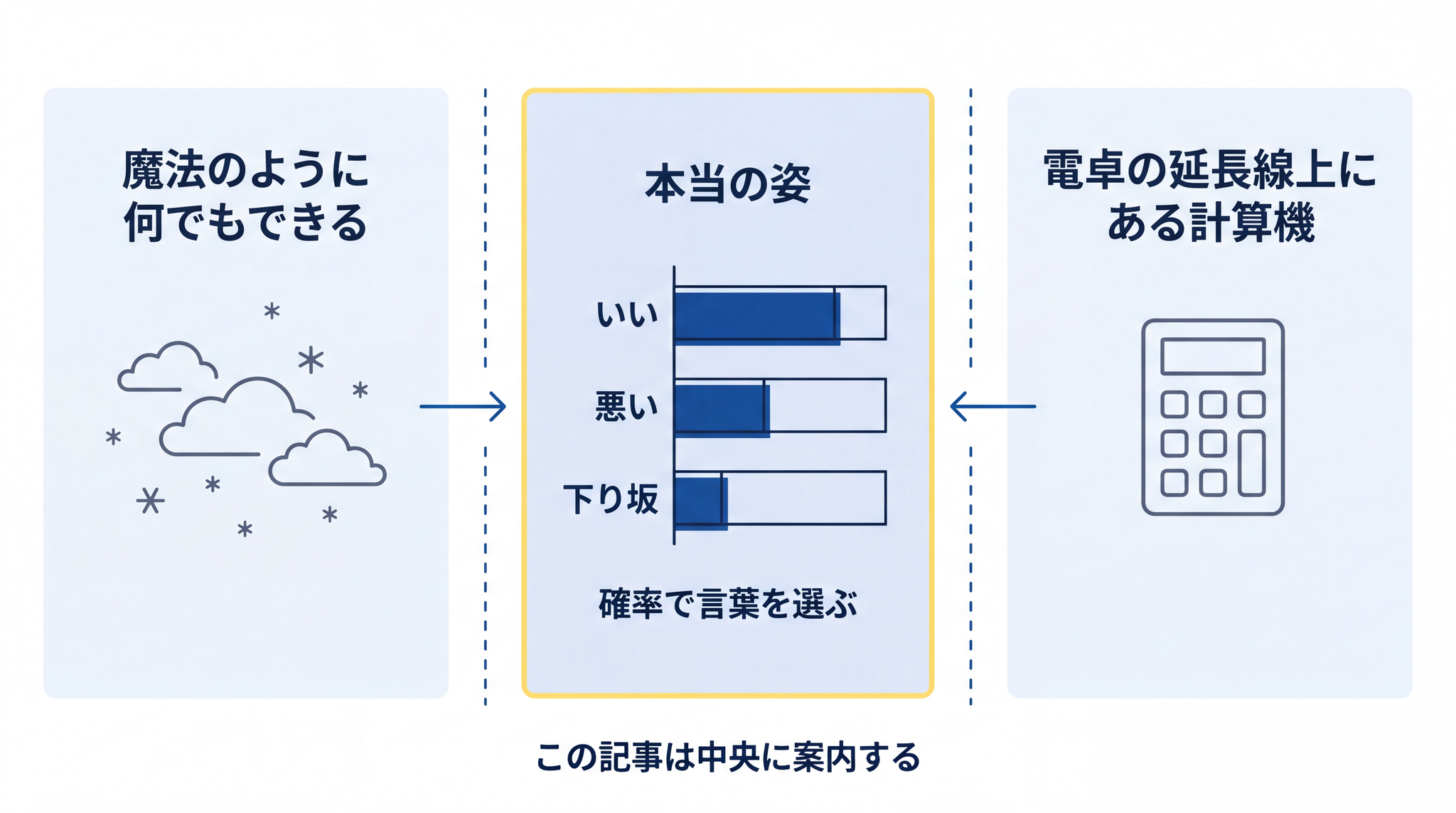
AI について教える場でよく感じることがあります。「AI は 確率で言葉を選んでいる」と最初から思っている方は、ほぼいません。多くの方は「魔法のように何でもできる」か「電卓の延長線上にある計算機」、そのどちらかのイメージで止まっています。その 2 つのイメージの間にある本当の姿が、この記事のテーマです。
仕組みが見えると、「AI に何ができて、何ができないか」も「自分の仕事や勉強にどう関わってくるか」も、自分の言葉で見極められるようになります。流れていくニュースに振り回されず、目の前の AI を冷静に扱える側に回るための地図 ── この記事をそんな道具として使ってもらえれば嬉しいです。
2. 「決まり通り動くソフト」と「確率で言葉を選ぶソフト」
まず一言だけ。この記事のタイトルにある「LLM」とは、ChatGPT・Claude・Gemini のような AI のことです。正式には 大規模言語モデル と呼ばれます。詳しい説明はこのあと順に出てきますが、いまは「言葉を使って何にでも答えてくれる AI」くらいに思ってもらえれば大丈夫です。
最初に押さえたいのは、エクセルや電卓のような昔ながらのソフトと、ChatGPT のような AI は、どちらもコンピュータの中で動く「ソフトウェア」だということです。広い意味では、どちらも プログラム と呼ばれます。
ただし、その内側の動作の仕方がまるで違います。
2-1. 決まり通り動くソフト
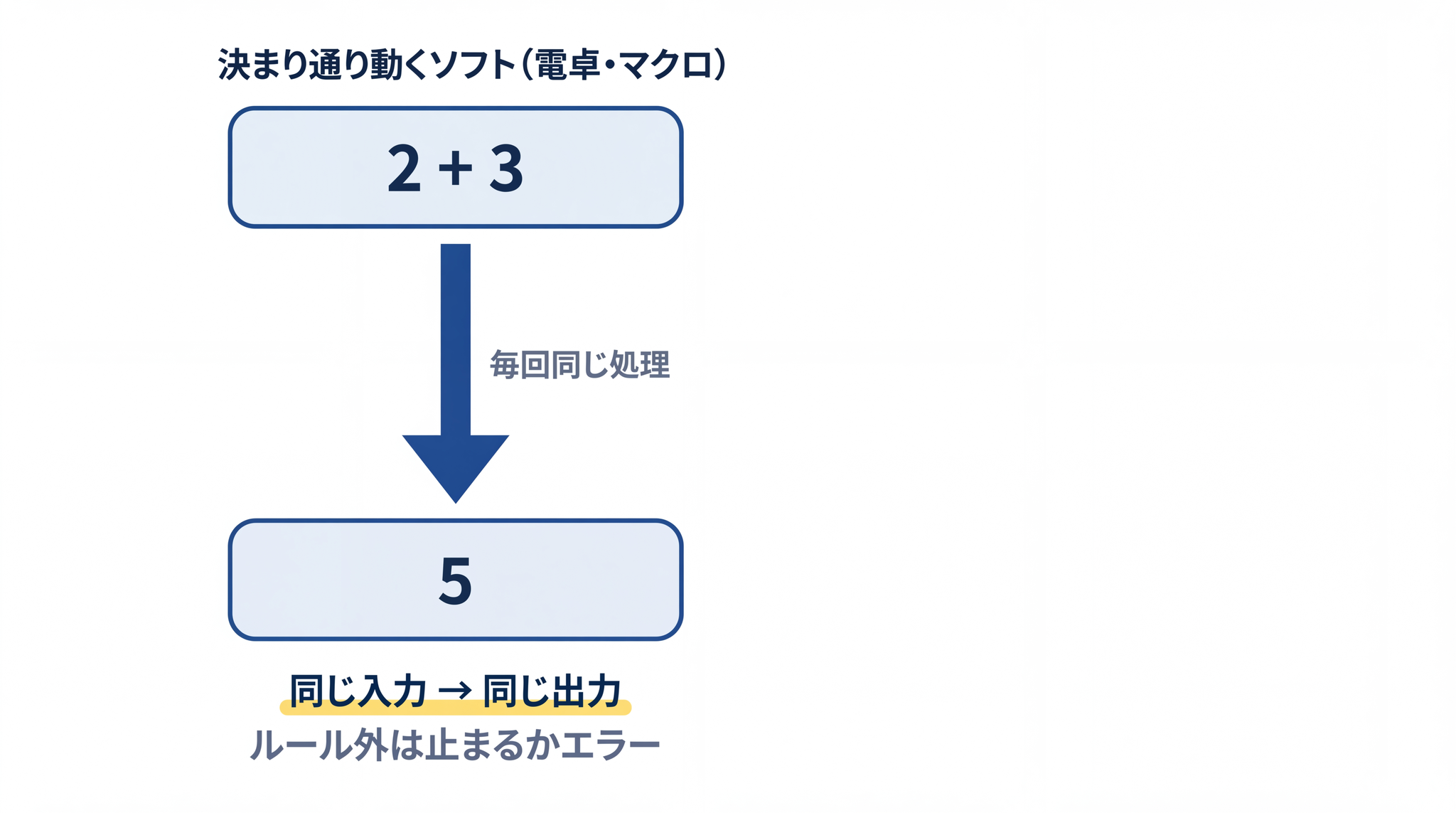
エクセルのマクロや電卓、自動販売機の制御 ── こうしたソフトは、人間があらかじめ「入力がこうなら出力はこう」というルールをすべて書き込んで動かしています。これは あらかじめ決まった手順通りに動かす方式 で、専門的には「ルールベース」と呼ばれます。
このタイプのソフトは、
- 同じ入力には、同じ出力。毎回必ず同じ結果になる
- ルールに書かれていない状況が来ると、止まるか、エラーを返す
という性質を持ちます。電卓に「2 + 3」と入れて、月曜日と火曜日で違う答えが返ってきたら、それは故障です。
2-2. 確率で言葉を選ぶソフト
LLM(大規模言語モデル。「文章を扱う AI の中身」と思ってください。ChatGPT・Claude・Gemini はこの仲間です)は、これとはまったく違う作りになっています。
LLM の動作の中心を、ざっくり 1 行で書くとこうです。
次に来る単語を、 確率の高い候補からある幅でランダムに 1 つ選ぶ。
この「単語を 1 つ選ぶ」を文の終わりまで繰り返して、答えの文章を組み立てる ── これが LLM の振る舞いです。
ここで効いてくるのが「確率」と「ランダム」という 2 つの言葉です。LLM の中では、毎回 偏ったサイコロ が振られています。サイコロといっても、6 つの目すべてが同じ確率で出るわけではありません。よく出る目と、たまにしか出ない目がある。たいていは出やすい目(つまり、いかにも続きそうな単語)が選ばれます。でも、出にくい目が選ばれることも、ときどきある。
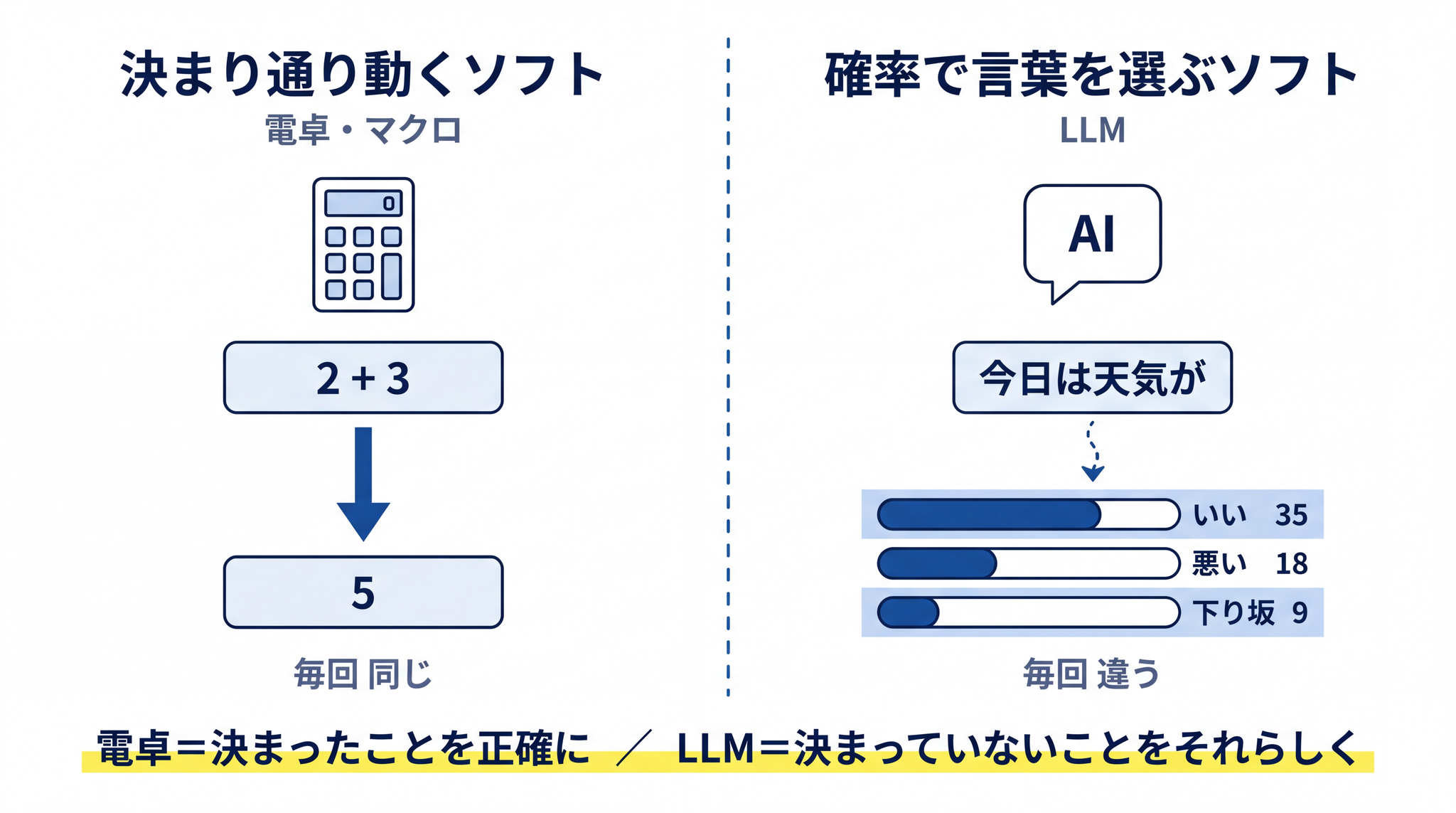
だから、同じ質問でも毎回少しだけ違う文章になります。
※ 細かい設定をいじれば、「サイコロを振らずに、毎回必ず一番確率の高い候補を選ぶ」ように指示することもできます。ただし ChatGPT や Claude を普段の画面から使う場合は、サイコロを振る側が標準 です。だから「毎回違う」が起こります。

2-3. どちらもプログラムで、違うのは動かし方
ここが大切なところです。「AI はプログラムじゃない」のではありません。AI もコンピュータの上で動くソフトウェアで、広い意味では立派にプログラムです。
違うのは、その動かし方のほうです。
- 決まり通り動くプログラム ── 入力と出力の関係を、人間がルールとして書き込む
- 確率で言葉を選ぶプログラム(LLM)── 入力と出力の関係を、大量の例から学習して身につけたうえで、最後は確率的に答えを組み立てる
この違いを一文で言うと、
電卓は「 決まったことを正確に 」やる道具、AI は「 決まっていないことを、それらしく 」やる道具
ということになります。
3. 「次に来る単語を予測する」だけで、なぜ会話できているように見えるのか
ここで、素朴な疑問が湧くかもしれません。
「単語を 1 つずつ確率で選んでいるだけ」── そんな単純な仕組みで、どうしてあれほど自然な会話ができているように見えるのでしょうか。質問に答えたり、メールを書いたり、ちょっとしたコードを書いたりまで、できているのに。
その答えがここにあります。
3-1. 確率分布 ── 候補に点数が付いている
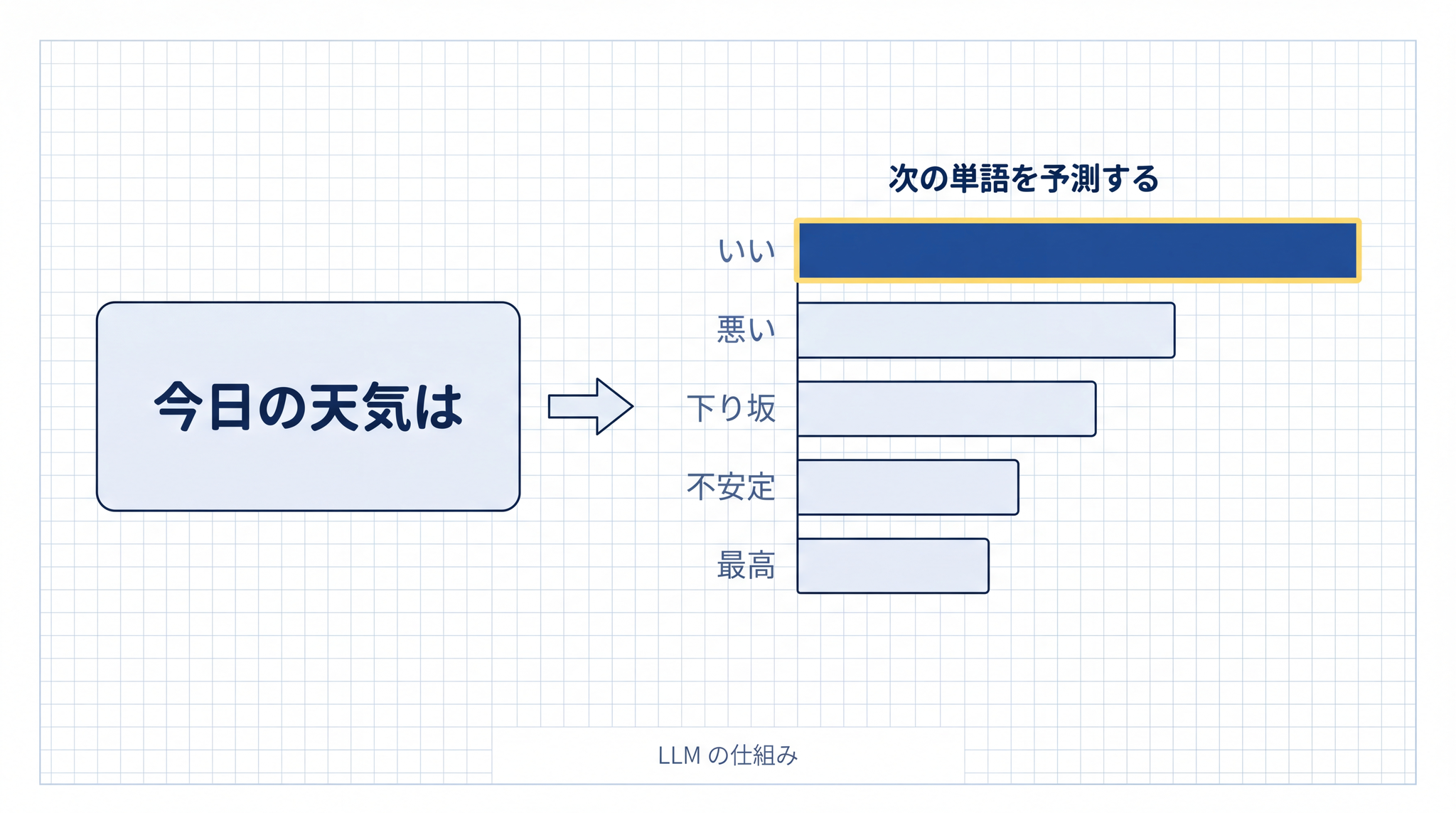
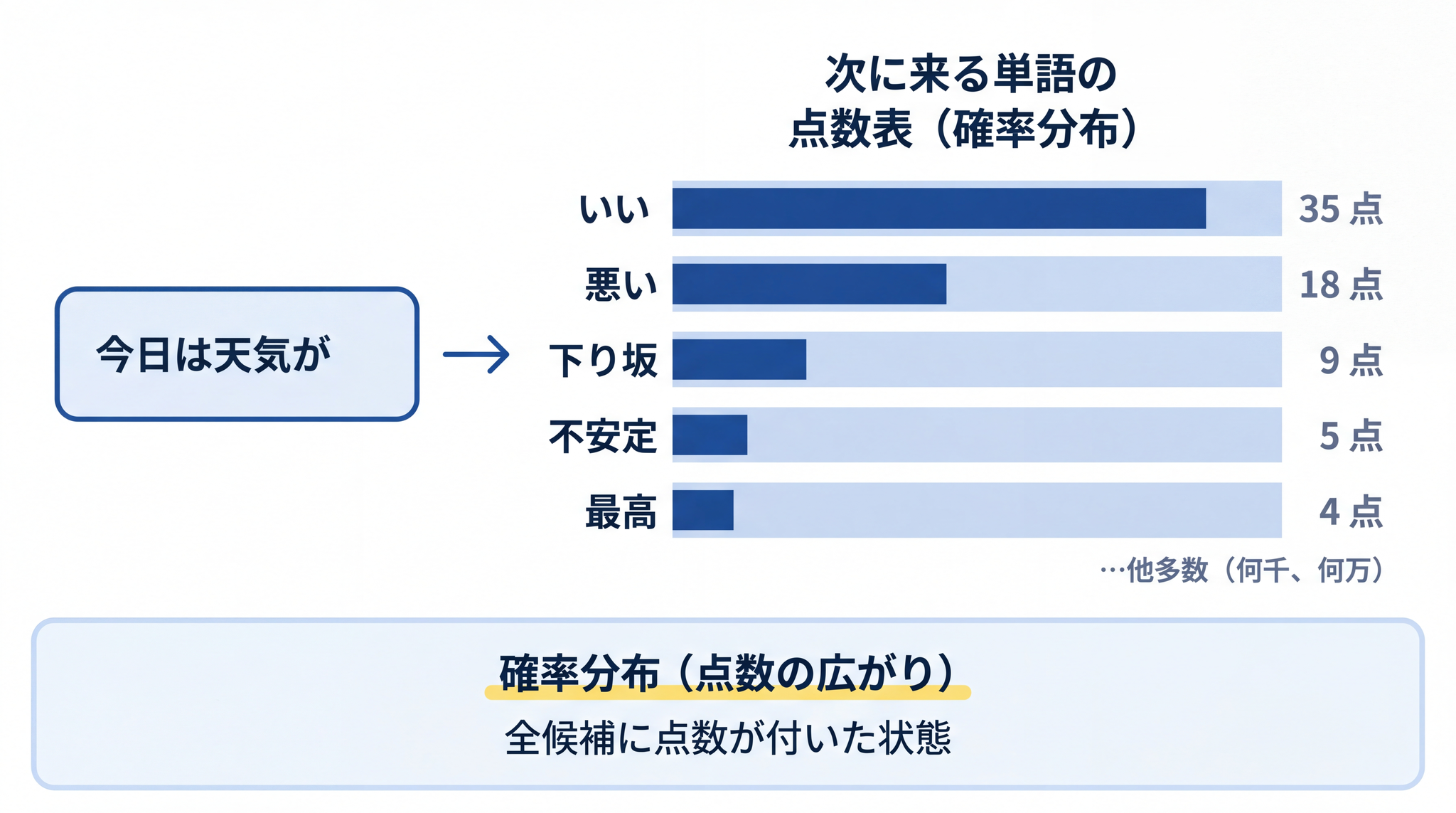
たとえばあなたが LLM に「今日は天気が」と入力したとします。LLM の中では、その続きとして来そうな単語の候補リストが一瞬で作られ、それぞれに確率の点数が付けられます。イメージとしては、こんな具合です。
- 「いい」… 35 点
- 「悪い」… 18 点
- 「下り坂」… 9 点
- 「不安定」… 5 点
- 「最高」… 4 点
- …(さらに何千、何万という候補に小さな点数が広がっている)
この「全候補に点数が付いている状態」を 確率分布(点数の広がり)と呼びます。「文章の続きとして、どの単語がどれくらい出やすいか」のリストだと思ってください。
LLM はここから、ある幅でランダムに 1 つ選びます。たいていは点数の高い「いい」あたりが選ばれます。でもときどき、「下り坂」のような少し外れた候補も選ばれる。これが 「毎回違う答え」の正体 です。
※ 注意:「もっとも点数の高い候補を必ず選ぶ」わけではありません。点数の高い候補のかたまりから、ランダムに 1 つを引き当てる ── という動作です。
3-2. これを文の終わりまで繰り返す
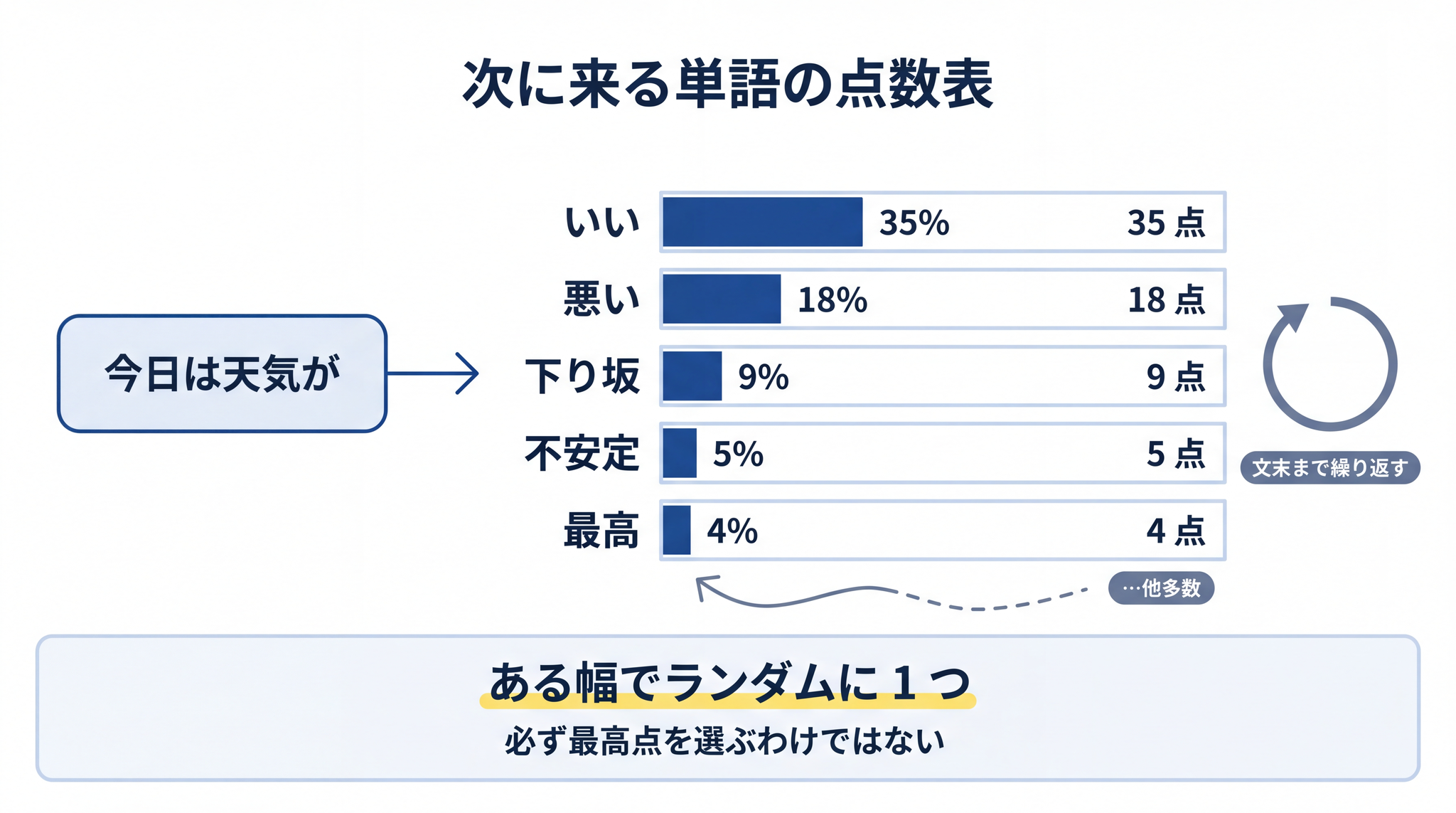
単語を 1 つ選んだら、それを文章のうしろにつなげて、また続きの候補を計算します。
- 「今日は天気が」→(選ぶ)→「いい」
- 「今日は天気がいい」→(選ぶ)→「ので」
- 「今日は天気がいいので」→(選ぶ)→「散歩」
- 「今日は天気がいいので散歩」→(選ぶ)→「に」
- …
これを文の終わりまで延々と続けます。短い 1 文の中だけでも、選ぶ動作が何十回。長い文章なら、何百〜何千回と繰り返されています。
この「次に来る単語を、確率の点数表から選ぶ」を繰り返すだけで、文章の作成、要約、翻訳 ── ニュースで紹介される文章まわりの機能のかなりの部分が動いています。
3-3. ただし「次に来る単語を予測する」が LLM の仕組みのすべてではない
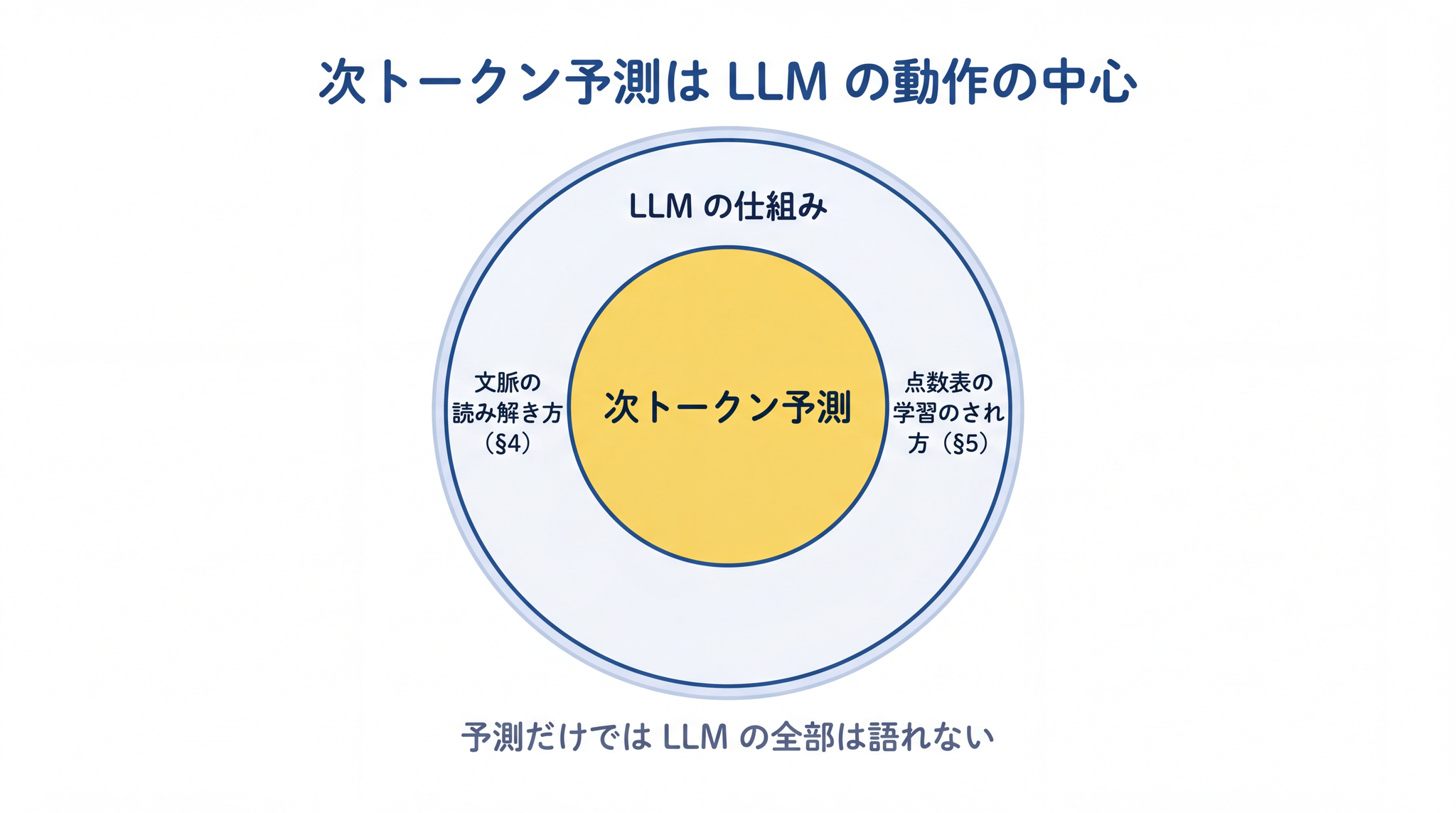
ここで一つ、誤解を生まないように少し補足します。「次に来る単語を予測する」は、LLM の 動作の中心 ではありますが、LLM の仕組みのすべてを言い切る言葉ではありません。
このあとで見ていくように、LLM が「賢く」見えるのは、
- 単語を選ぶ前に、文脈をどう読み解いているか(§4)
- そもそも、その点数表をどう学習で身につけたか(§5)
といった、もう一段奥の仕組みがあるからです。「次に来る単語を予測する」だけでは、こうした仕組みのすべては説明できません。
4. AI は何を見て予測しているのか ── 文脈と「言葉の最小単位」
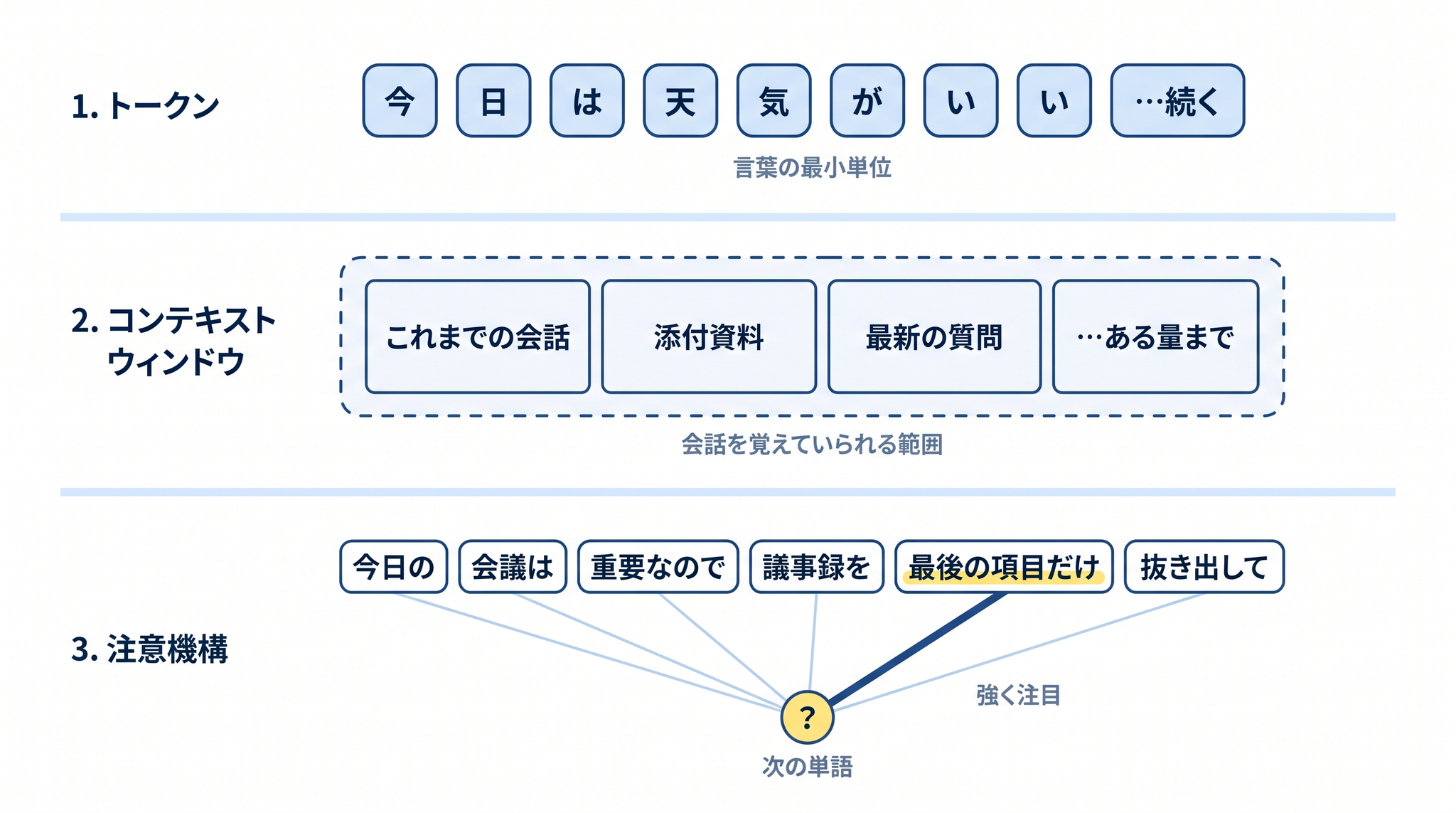
LLM が「次に来る単語の点数表」を作るとき、何を見てその点数を決めているのでしょうか。3 つの言葉を順に紹介します。
4-1. トークン ── 言葉の最小単位
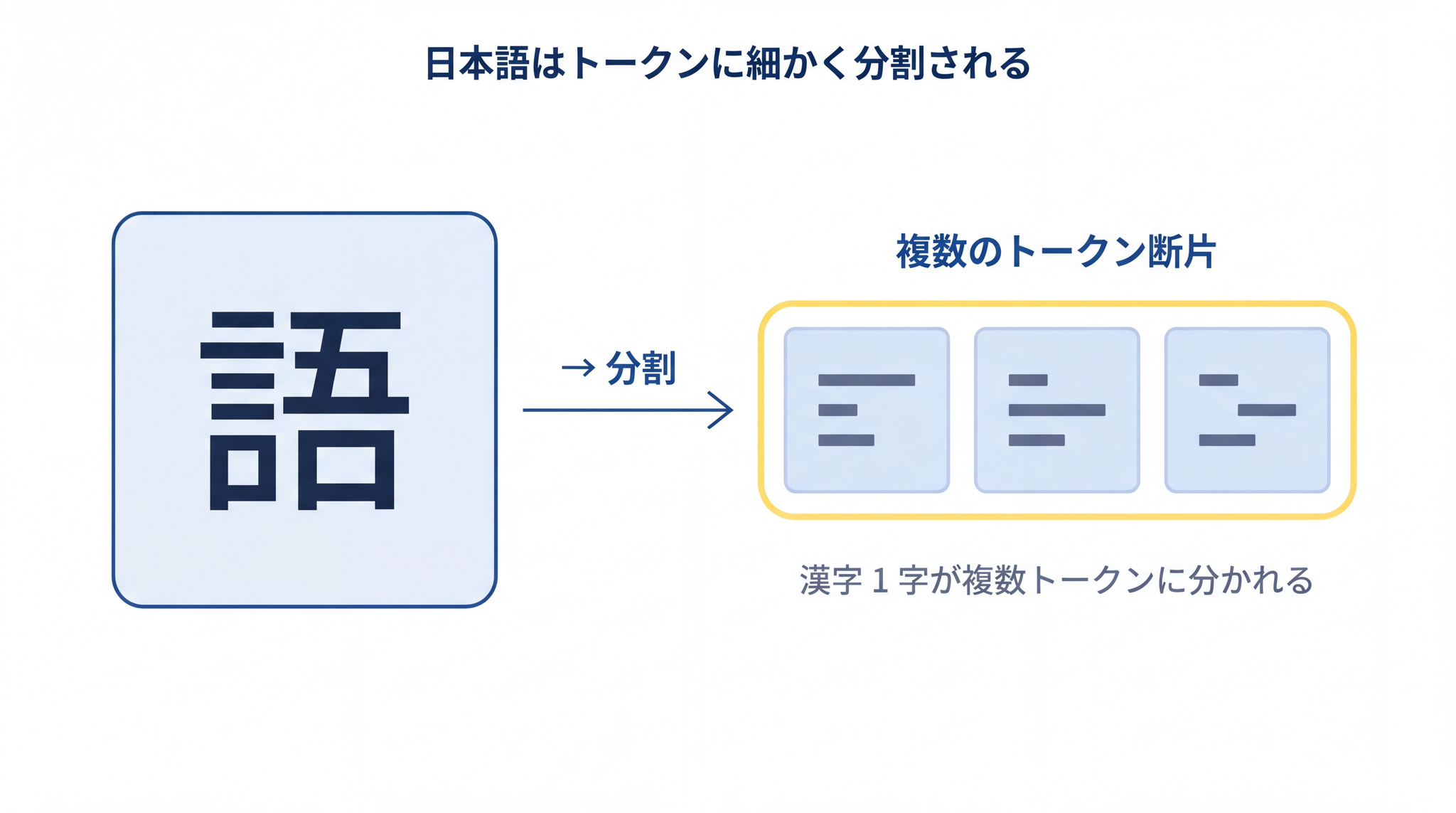
LLM は、文章をそのまま読んでいるわけではありません。まず、文章を トークン という小さなかたまりに切り分けます。
トークンは「言葉の最小単位」で、英語ならだいたい単語 1 つ。日本語の場合はもっと細かく、漢字や仮名の 1 文字が 1〜2 個のトークンに分かれるのが普通です。たとえば「今日は天気がいい」のような 8 文字の短い文でも、AI の中では 10 個前後のトークンに分解されています(具体的な切り方は使う AI によって違います)。
LLM は、この単語よりも細かいトークンを単位にして「次に来そうな候補」を計算しています。
※ 「単語」と「トークン」は厳密にはずれますが、本記事ではその細かい違いには立ち入りません。「単語のようなもの」と読み替えていただいて大丈夫です。
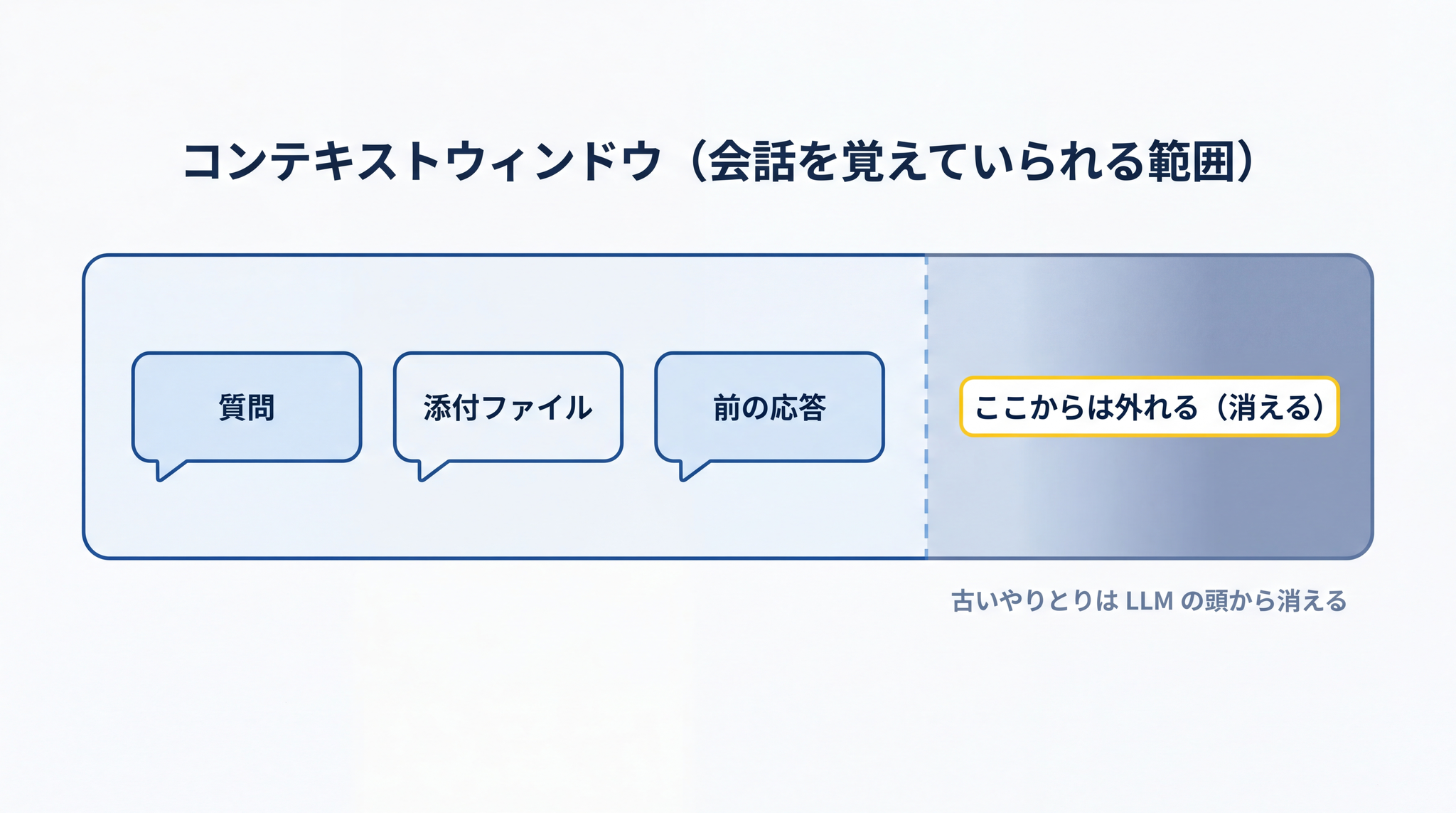
4-2. コンテキストウィンドウ ── 会話を覚えていられる範囲
LLM は、あなたが今までに送ったやりとり(質問・添付した文章・自分が前に出した答え)をまとめて見ることで、次のトークンの点数を決めています。
ただし、無限に覚えていられるわけではありません。ある決まった量の文章までが、いま LLM の目の前に広げられている範囲です。これを コンテキストウィンドウ と呼びます。「会話を覚えていられる範囲」と思ってください。
コンテキストウィンドウの大きさはモデルによりますが、最近の AI では数十万〜数百万単語規模 ── 文庫本 1,000 冊分くらい ── の文章を一度に読めるくらいになっています(具体的な数字はモデルごとに違いますし、半年単位で更新されていくので、規模感だけ示します)。
コンテキストウィンドウから外れた古いやりとりは、 LLM の頭からは消えます。 長い会話の途中で、最初のほうに伝えた条件が忘れられているように感じることがあるのは、このためです。
4-3. 注意機構 ── どの単語にしっかり目を向けるか
重要な単語に蛍光ペンを引く仕組みがある、とイメージしてください。コンテキストウィンドウの中にある全部のトークンを、LLM は同じ重さで見ているわけではありません。次のトークンを予測するたびに「どの単語が今一番効くか」を計算して、その単語に集中する ── これが 注意機構 と呼ばれる仕組みです。
たとえば「今日の会議は重要なので、議事録を最後の項目だけ抜き出してください」という指示なら、LLM は「最後の項目だけ」に蛍光ペンを引いて、「今日」や「会議」よりもその語を優先して見ます。均等に読むのではなく、効きそうな単語を選んでしっかり見ている。それだけ押さえれば十分です。コンテキストウィンドウの仕組みをもっと詳しく知りたい方は「コンテキストウィンドウとは何か」も参考にしてください。
トークン → コンテキストウィンドウ → 注意機構。この 3 つを通って、LLM は「次に来る単語の点数表」を決めています。
5. AI はどうやって「賢く」なったのか ── 学習の 3 段階
では、そもそも、どうしてその点数表が「だいたい正しい」答えに向かうのでしょうか。それは、AI を作るときの学習で身についたものです。
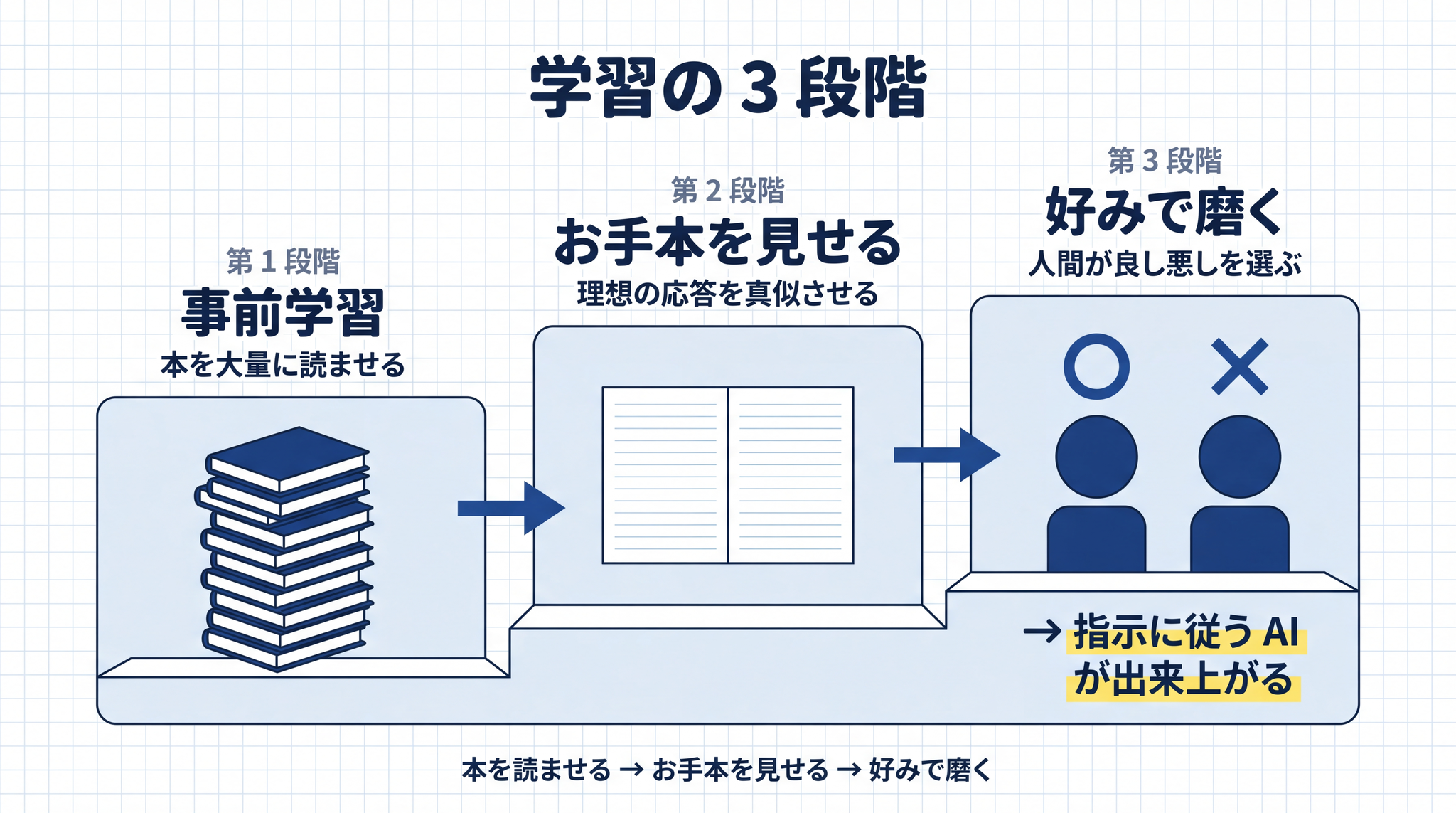
現代の主要な LLM は、おおむね 3 段階の学習で訓練されています。
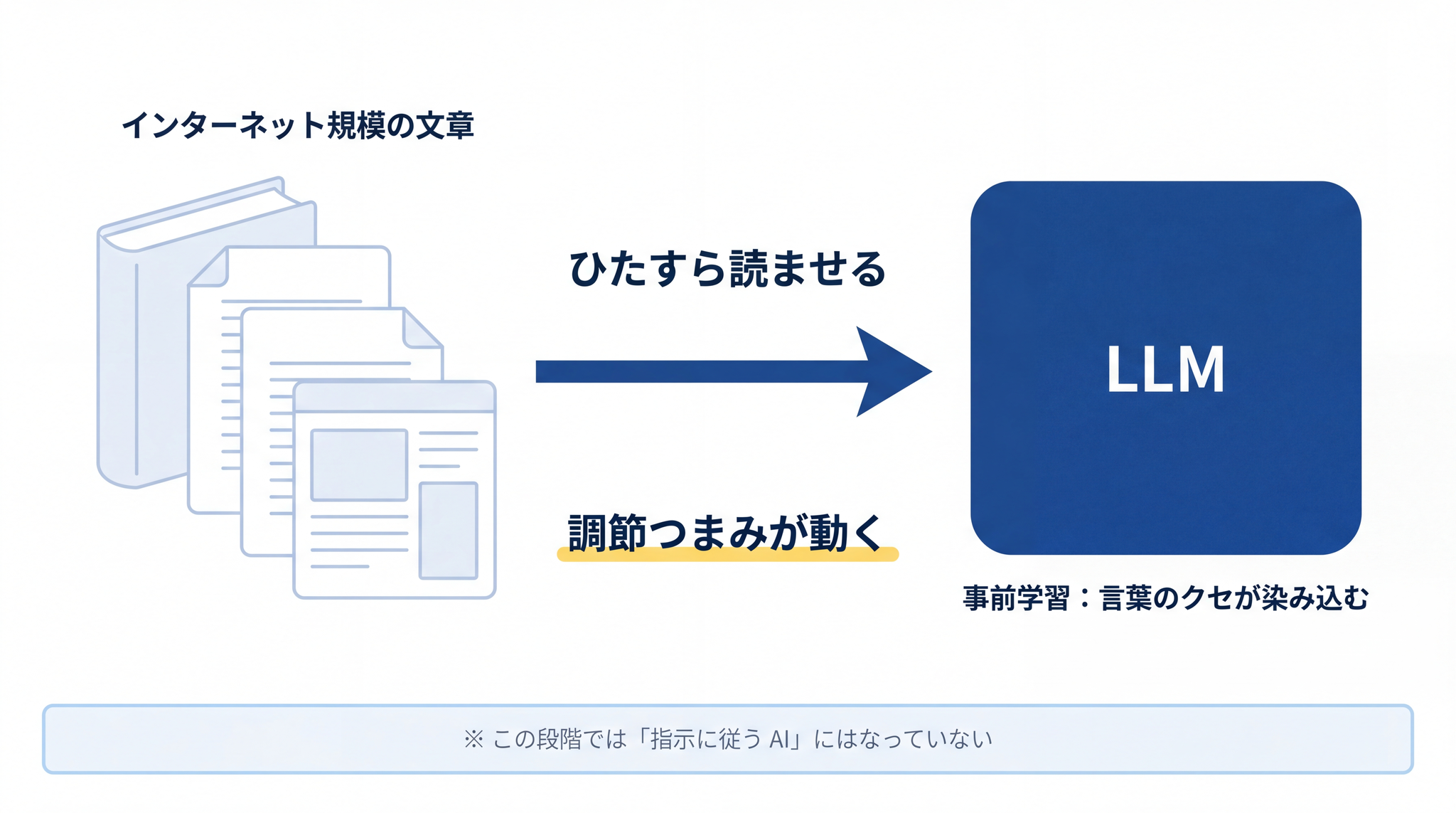
5-1. 第 1 段階:本を大量に読ませる(事前学習)
最初は、インターネット規模の膨大な文章を読ませます。本、論文、ウェブページ、ニュース、Wikipedia、コード ── インターネット上に出回っている文章の、ものすごく広い範囲を、ひたすら読ませる。
このとき、LLM がやらされる課題はとても単純です。
「文章の途中までを見せるから、続きの単語を当ててごらん」
正解の単語を高い確率で当てるたびに、LLM の中の 調節つまみ(数千億〜数兆個もある、内部の数値)が、少しずつ動かされていきます。これを膨大な回数繰り返すうちに、「言葉のクセ」「世界の常識」「文章の作法」が、点数表の形として LLM の中に染み込んでいきます。
これが 事前学習 です。この段階で LLM は、それなりに自然な文章を作れるようになります。
ただし、この段階の LLM は、まだ「指示に従う AI」にはなっていません。「タイトルを 3 つ提案してください」と頼んでも、提案ではなくその文の続きを出してくることがあります。本を読みすぎただけの状態です。
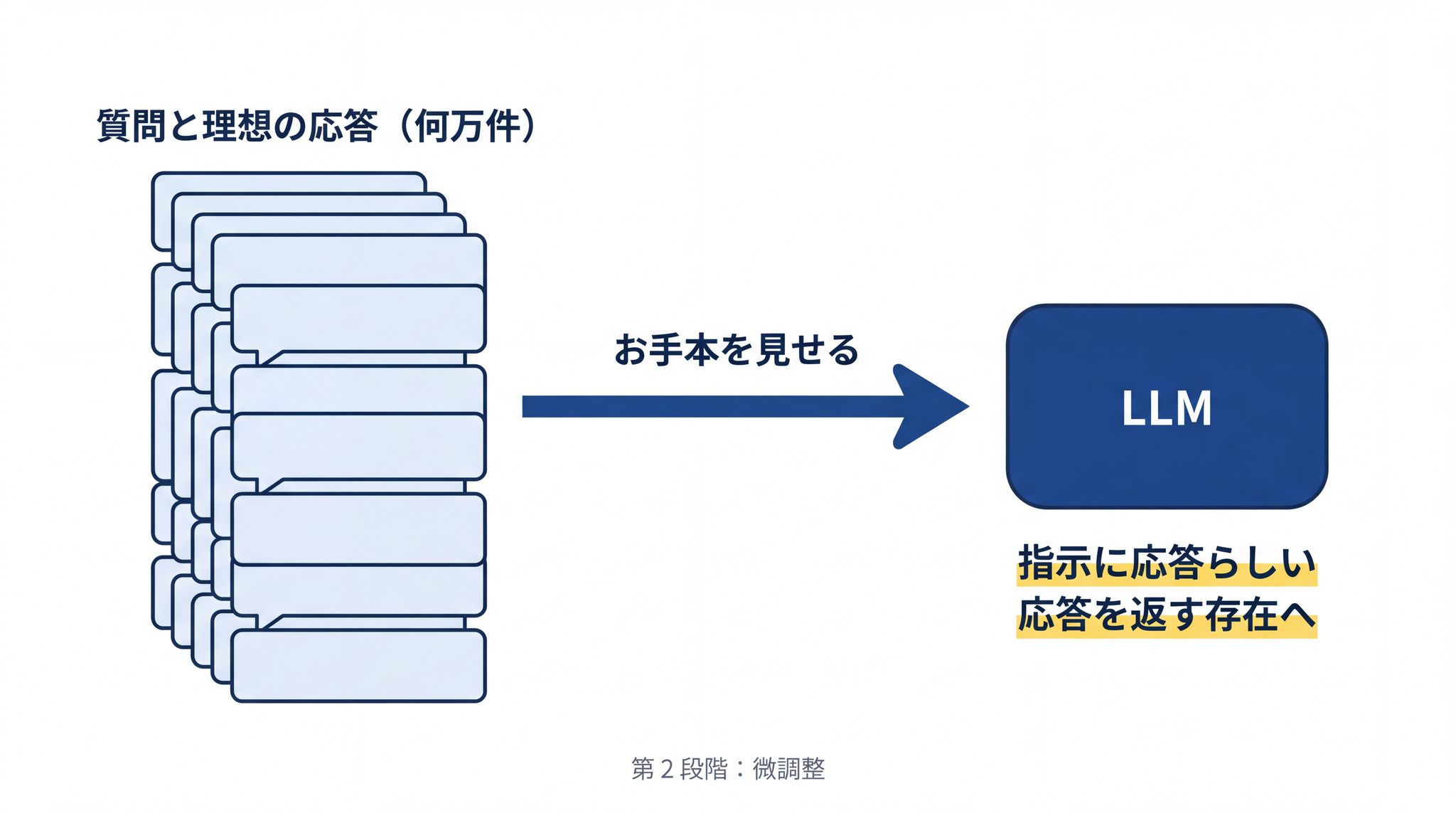
5-2. 第 2 段階:お手本を見せて真似させる
そこで、人間が理想の応答例を作って見せます。
「こんな質問が来たら、こう答えるのが正しい応答です」というお手本を、何万件も用意して LLM に学習させる。LLM は、ただ続きの文章を作る存在から、「指示に対して、応答らしい応答を返す」存在へと変わっていきます。
これは お手本を使った微調整 の工程です。1
5-3. 第 3 段階:人間の好みで磨く
それでも、まだ完璧ではありません。同じ質問への答えにも、「丁寧で正確」「ぶっきらぼうだが正しい」「正確だが冗長」など、いろいろな応答候補があり得ます。どれが「人間に好まれる」かは、お手本を見せるだけでは伝えきれません。
そこで第 3 段階では、LLM に同じ質問への複数の応答を作らせ、人間(または訓練された別の AI)に「どっちがマシか」を選ばせます。この「人間の好み」のデータを大量に集め、それをご褒美として LLM の調節つまみをさらに動かす。
これが 人間の好みで磨く工程 です(専門的には「人間のフィードバックからの強化学習」と呼ばれます)。ここで初めて LLM は、「役に立ち、無害で、正直」という、人間にとって扱いやすい応答スタイルを身につけます。
「お手本」「人間の好み」で磨かれているという事実は、AI への指示の出し方にも直結します。お手本となるサンプルを 1〜2 つ添えると応答が安定するのは、この磨き方の延長線上にある自然な反応です。
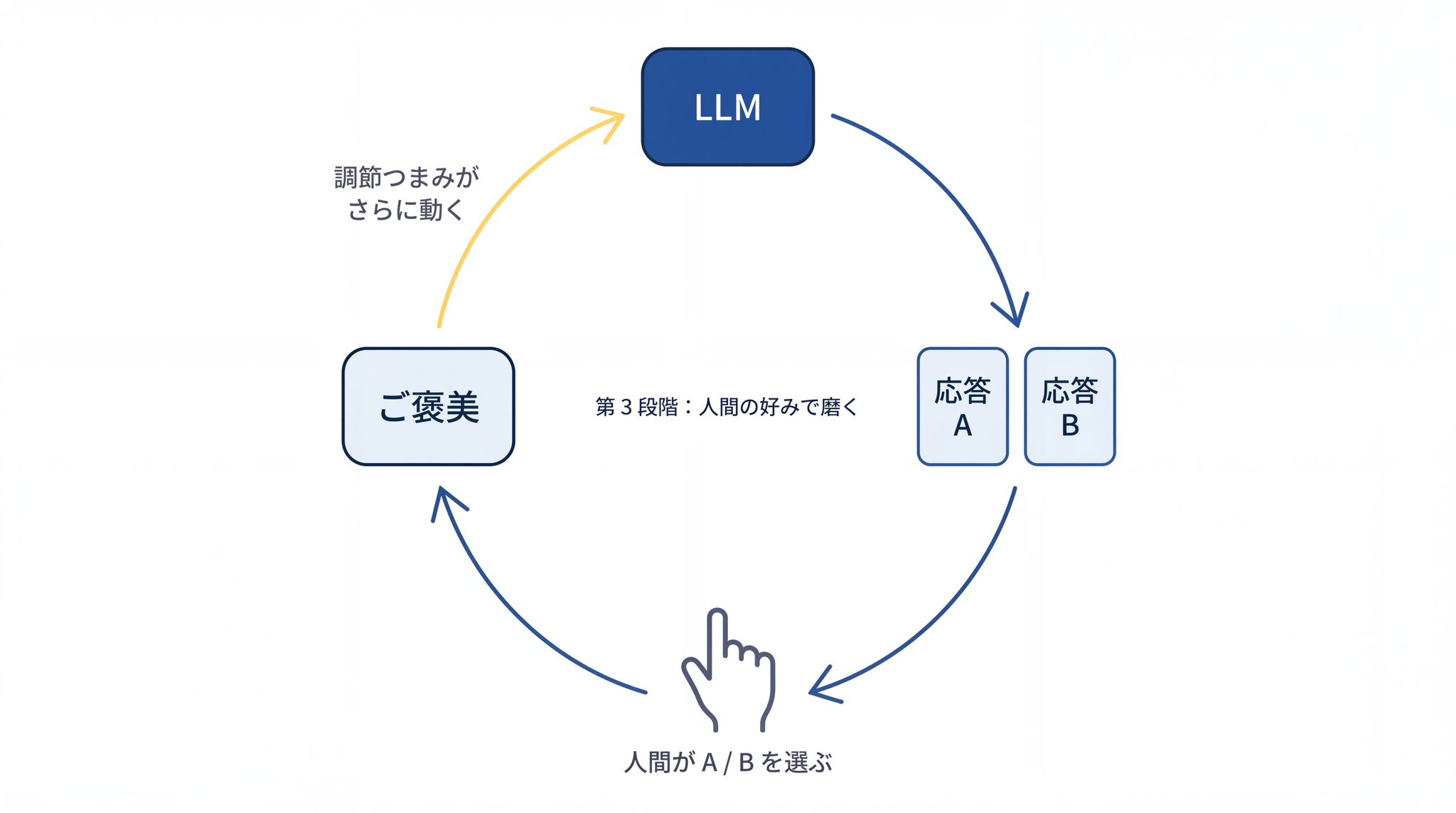
※ Anthropic の Claude は、第 3 段階で人間の代わりに AI 自身に応答の良し悪しを評価させる派生型を採用しています。手段はいくつかありますが、「好みのデータで磨く」という発想はどれも同じです。
なお、最近は答える前に長い思考プロセスを内部で展開するタイプの AI(推論モデル)も登場しています。詳しい仕組みは別記事で扱う予定です。
6. 「言葉だけ」じゃない ── 画像・音声も「予測」で扱える(マルチモーダル)
LLM は文章を扱う仕組みとして紹介してきましたが、最近の AI は画像を見てくれたり、声で話しかけられたり、写真の中の文字を読んでくれたりもします。これは マルチモーダル(複数の形のデータ ── 文字・画像・音声 ── をまとめて扱える性質)と呼ばれるものです。
6-1. 画像を「見る」── 同じ予測の仕組みに合流する
画像を入力に取れる AI(ChatGPT・Claude・Gemini など)は、内部で次のような処理をしています。
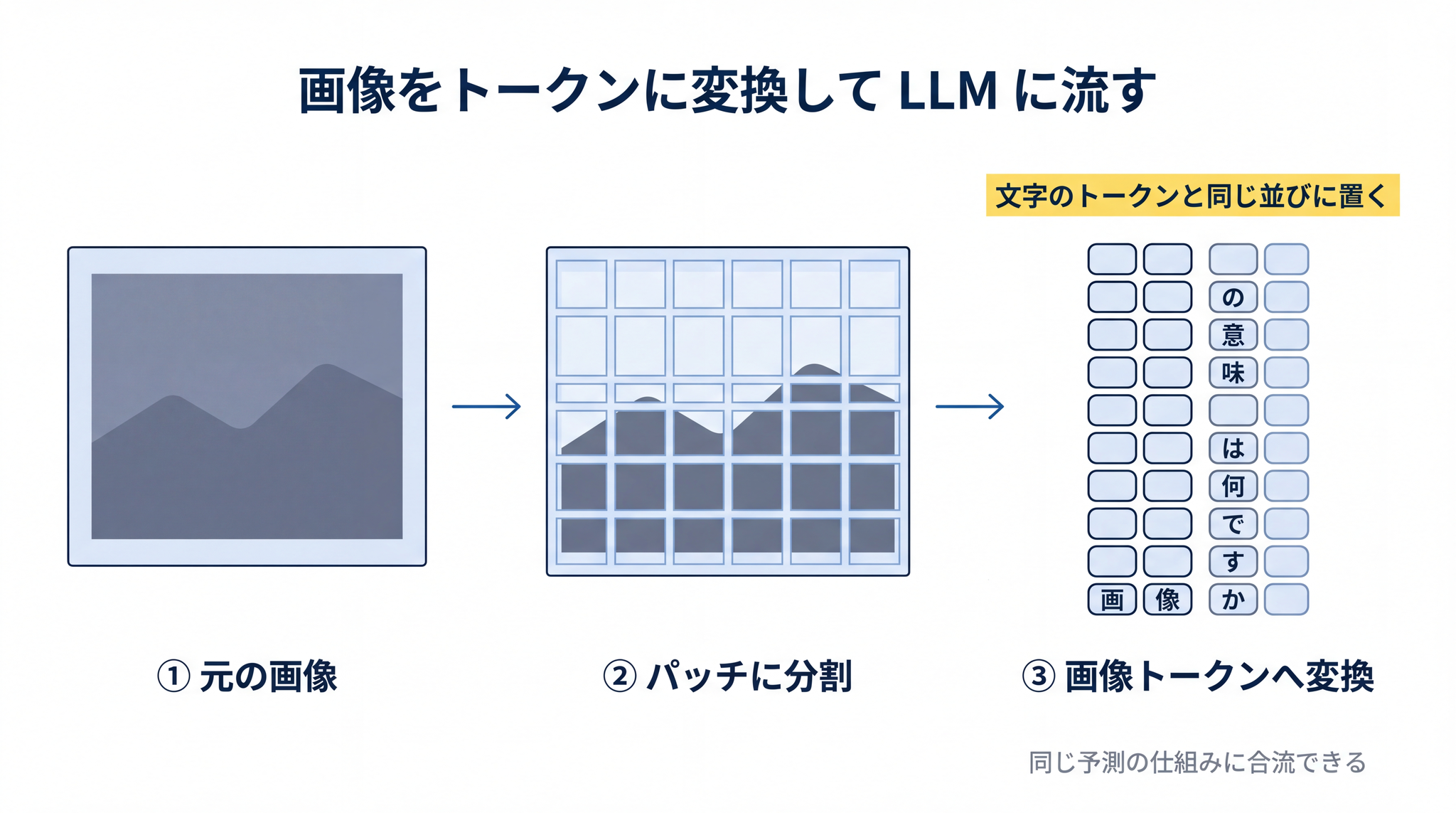
画像をモザイクのように小さなマス目に切り分けて、それぞれを言葉と同じ「トークン」に変換するイメージです。具体的には、3 つの手順を踏みます。
まず画像を細かいブロック(パッチ)に分割します。ちょうど方眼紙を 1 マスずつ切り取るようなイメージで、1 マスが画像の一部を担当します。次に、それぞれのパッチを画像用のトークンに変換する。そして最後に、そのトークンを文字のトークンと同じ並びに置いて、LLM に流し込む。
不思議に思えるかもしれませんが、画像もトークンの並びとして扱えてしまえば、LLM はそれをいつもどおり処理できます。「次に来る単語を、点数表から選ぶ」という仕組みが、画像つきの会話にもそのまま使える ── これが現代のマルチモーダル LLM の発想です。
6-2. 画像を「作る」── ここからは別の仕組み
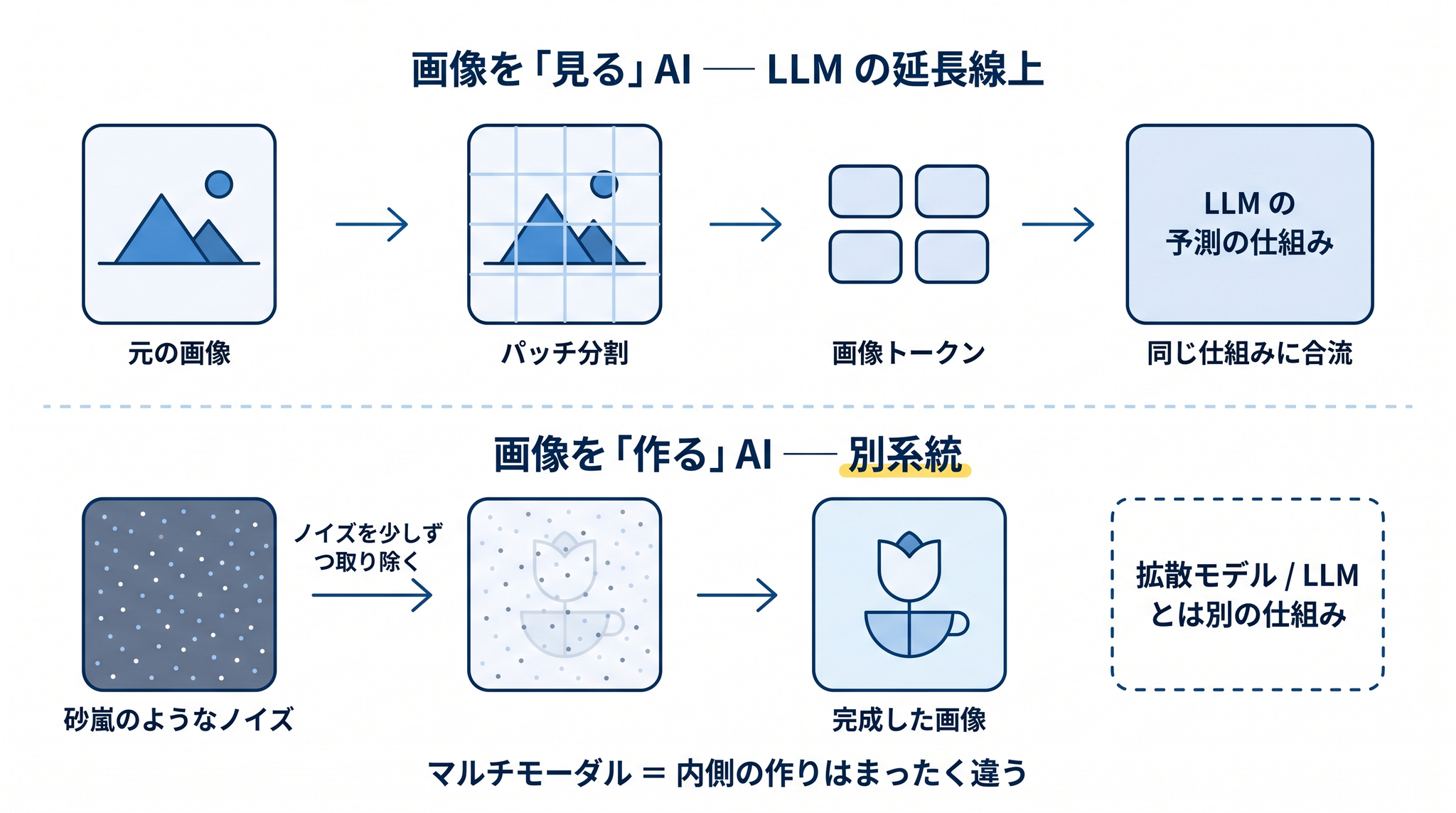
ところで、ChatGPT で画像を作ってくれと頼むと、写真風の画像が出てきます。これも LLM がやっているのか、と思うかもしれませんが、画像生成は LLM とは別の仕組みで動いています。
画像を作る側は、拡散モデルと呼ばれる別系統の技術が中心です。ざっくり言うと、
砂嵐のようなノイズだらけの画像から始めて、少しずつノイズを取り除いていって、最後にきれいな画像を仕上げる
という、まったく別の動作のしかたです。
ここで覚えておいてほしいのは、
- 画像を「見る」AI は、LLM の延長線上にいる(トークン化して同じ仕組みに流す)
- 画像を「作る」AI は、LLM とは別の系統(拡散モデルなど)で動いている
という区別です。「マルチモーダル」と一口に言っても、内側の作りはまったく違います。
業務で使うときは、写真や図表を読み込ませる作業(「見る」側)と、画像を新しく作らせる作業(「作る」側)で、向き不向きや限界が違うことを覚えておくと、使い分けやすくなります。
7. 仕組みが見えると、AI に何を任せるべきかが分かる
最後に、この理解が現実の判断にどうつながるかを、3 つだけ書いておきます。
7-1. なぜ毎回違う答えが返るのか
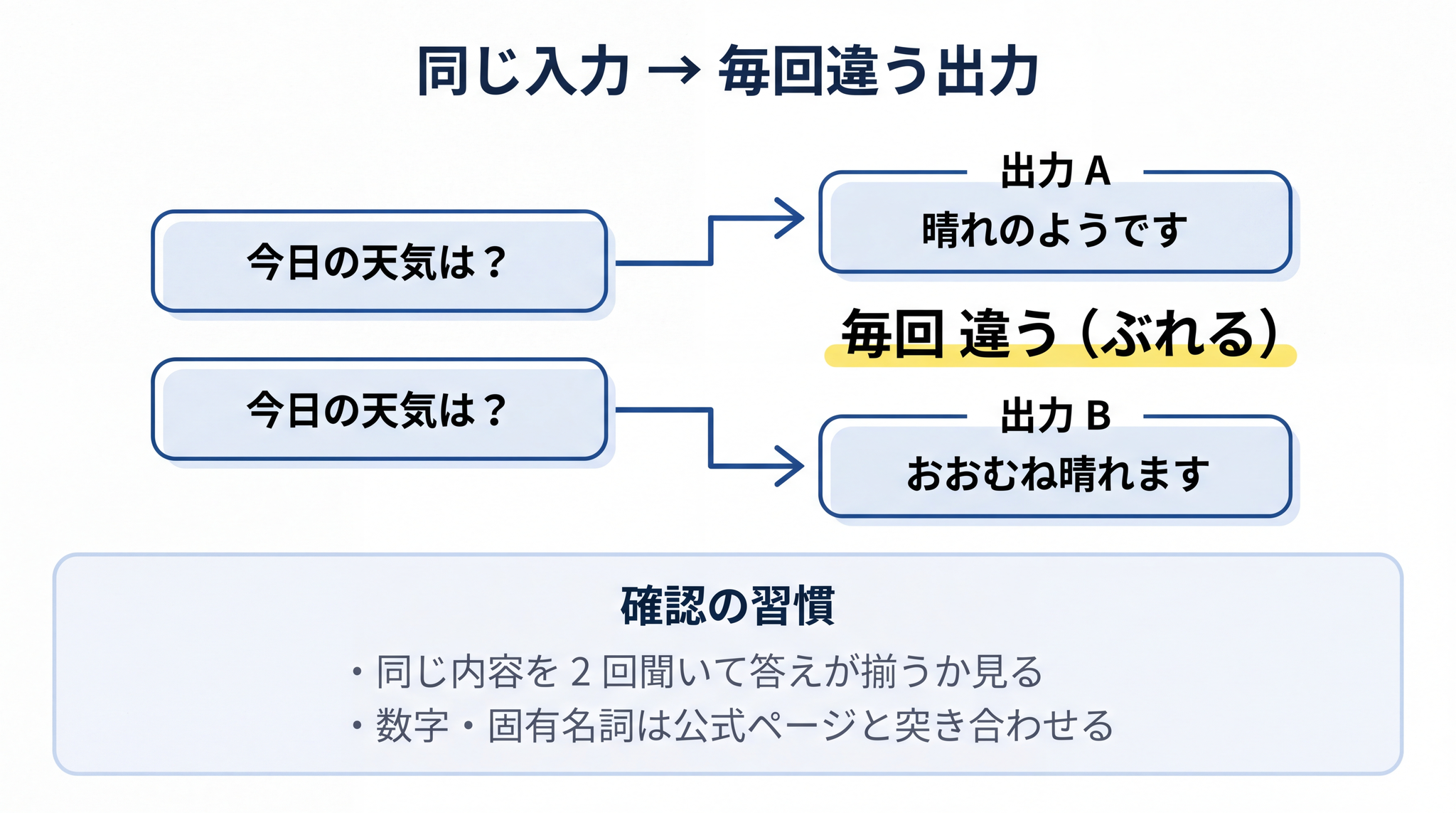
冒頭の疑問への答えは、もう明らかです。LLM は確率の点数表からランダムに単語を選んでいるから、同じ入力でも毎回違う出力になります。これは故障ではなく、仕組みそのものから出てくる動作です。
逆に言うと、LLM の答えは 「ぶれる」のが標準 です。仕事や手続きのような大事な場面で使うときは、出力をそのまま信じるのではなく、人間が一度受け止めて確かめる手順を挟むのが基本になります。たとえば「同じ内容を別の聞き方で 2 回尋ねて、答えが揃うか見る」「数字や固有名詞が出てきたら、公式ページや手元の資料と突き合わせる」といった習慣が、AI を安全に使うための出発点です。
7-2. なぜ AI は「自信満々で嘘をつく」のか
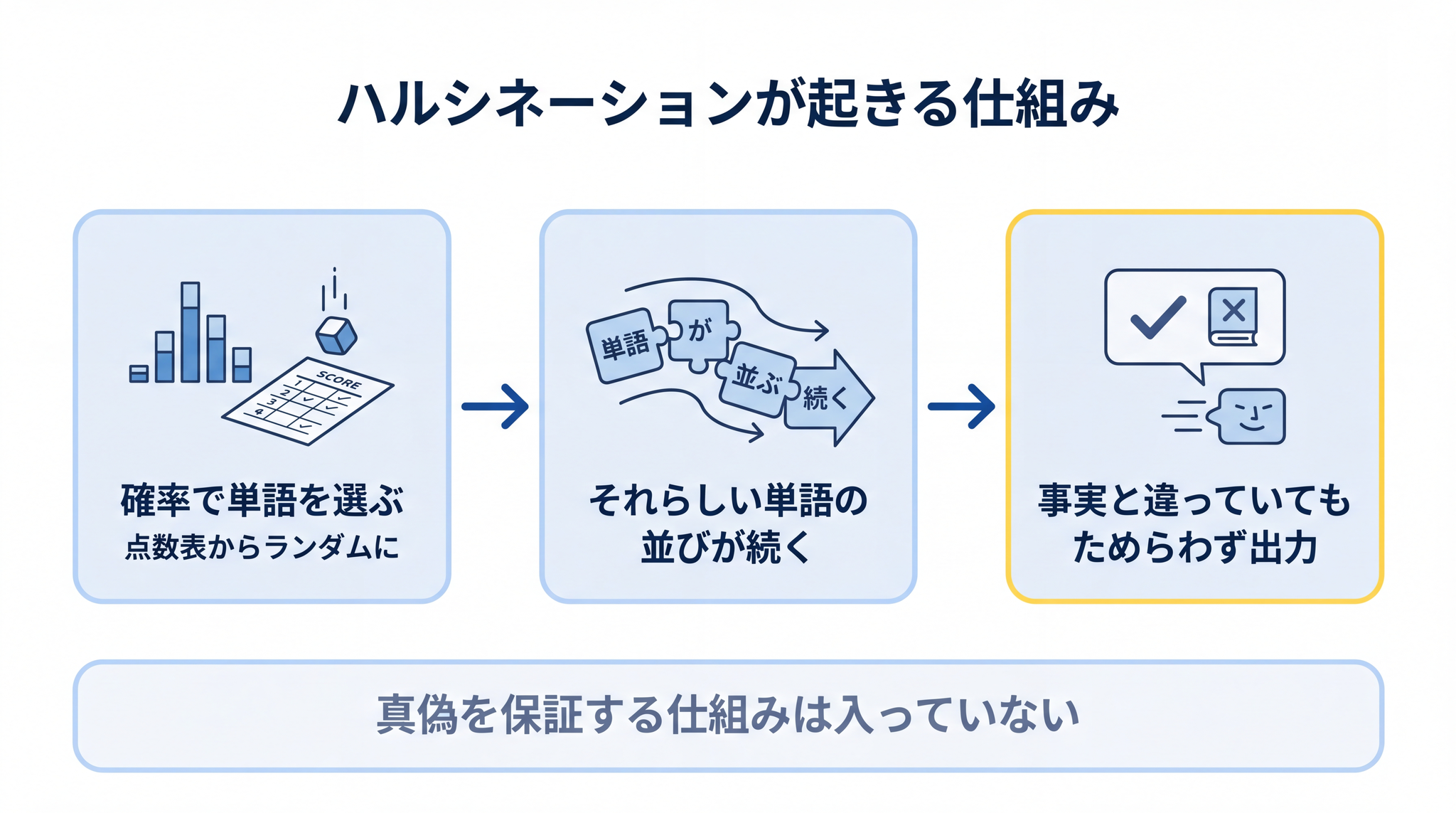
LLM が事実と違うことを、もっともらしく言い切ってしまう現象を ハルシネーション(hallucination)と呼びます。「AI が自信満々で嘘をつく」と表現される現象です。
この原因は、§2〜§3 で見た仕組みからほとんど自動的に説明できます。LLM がやっているのは、「次に来る単語の点数表から、ある幅でランダムに 1 つ選ぶ」だけ。 真偽を保証する仕組みは、そこには入っていません。
それらしい単語の並びが続けば、たとえ事実と違っていても、LLM はためらわずに出力してしまう。これは、確率で動く仕組みの 必然の副作用 です。OpenAI 自身も、公式に「精度は 100% には届かない」と認めています。2
詳しい話は別記事「ハルシネーション ── AI に「本当」の感覚が無い、という話」に譲りますが、本記事の仕組みが分かっていれば、
- ハルシネーションは 仕組みから出てくる癖 であって、ちょっとした手直しで完全に消える種類のものではない
- 事実が大事な場面では、外の根拠(公式ホームページ、自分の記憶、別の人の確認など)と突き合わせる必要がある
という判断が、自然に立ちます。
7-3. 新しいモデルが出ても、判断軸は古びない
毎月のように、新しいモデルが出ます。GPT、Claude、Gemini ── 名前もバージョン番号も、どんどん入れ替わっていきます。
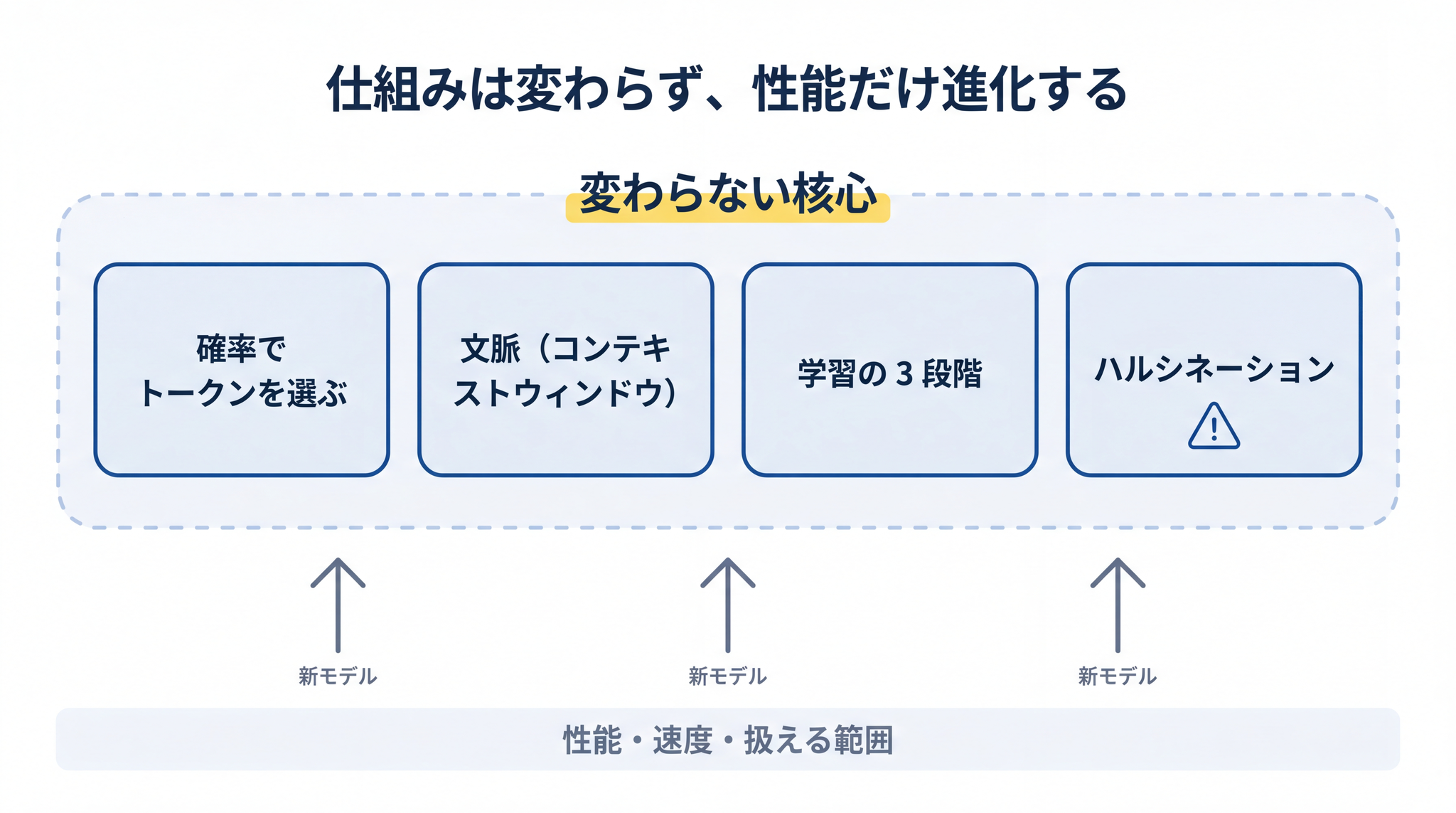
それでも、§2〜§6 で見てきた仕組みは、当面の間 大筋では変わりません。 §5 で見たように、事前学習→お手本→人間の好みで磨く、という 3 段階の枠組み自体は 2017 年ごろから変わっていないからです。
- 確率の点数表からトークンを選ぶ
- コンテキストウィンドウの中の文章にしっかり目を向ける
- 大量の本を読み、お手本を見せられ、人間の好みで磨かれている
- ハルシネーションは仕組みから出てくる癖
新モデルが出ても、これらは前提のまま、性能や速度や扱える範囲が広がっていく ── という形で進化します。仕組みが分かっていれば、新モデルの紹介記事を読んでも振り回されません。何が変わって、何が変わっていないかを、自分で見分けられるからです。
7-4. 任せてよいこと、要確認なこと
仕組みが見えると、何に任せて何に任せないかが具体的に決められるようになります。最小限ですが、出発点になる目安を書いておきます。
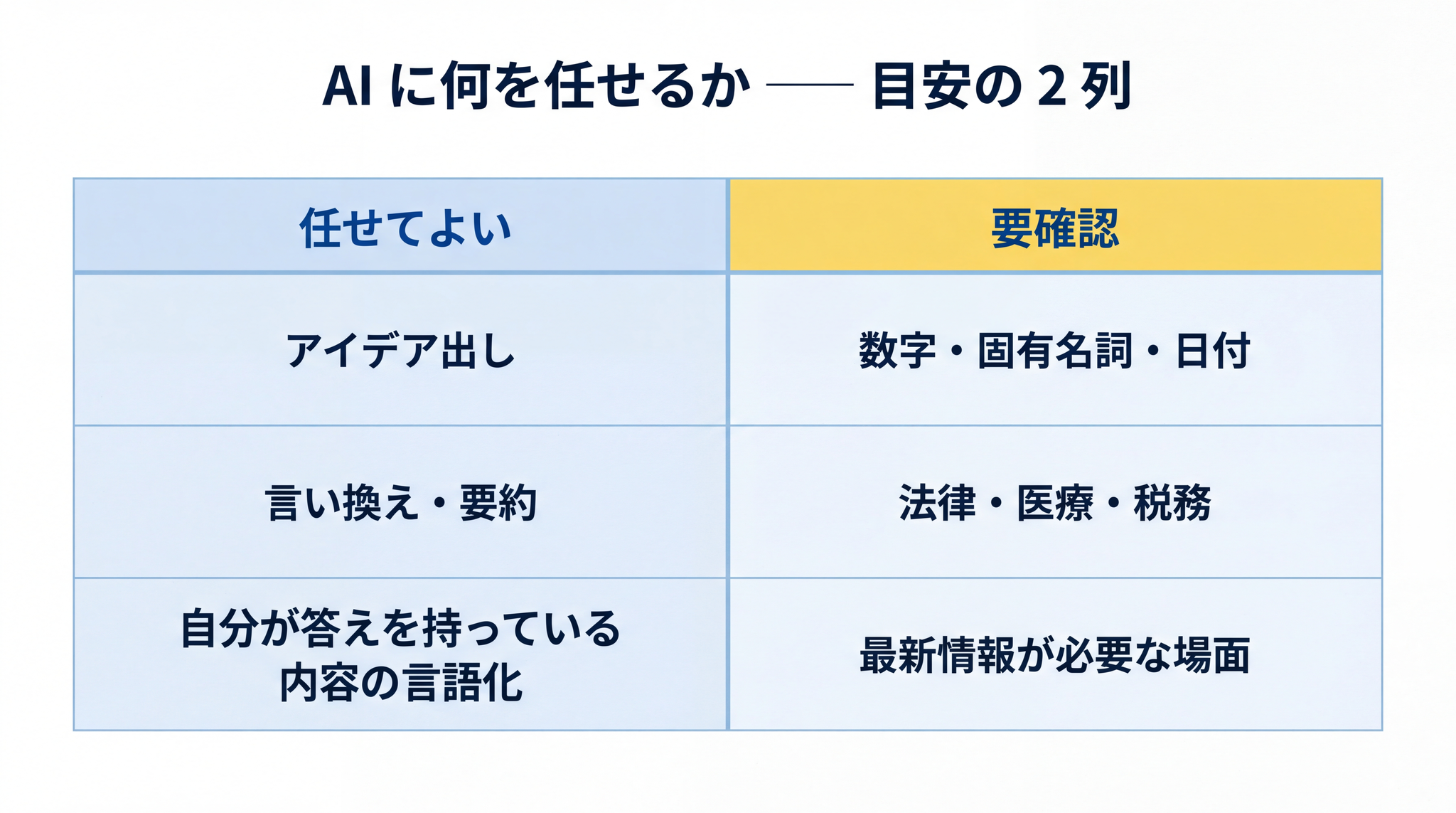
任せてよい:
- アイデア出し・たたき台作り(毎回違う出力がむしろ役立つ場面)/議事録の下書きや箇条書き整理
- 文章の言い換え・要約(多少ぶれても本筋が伝われば OK)/メール返信のたたき台
- 自分が答えを持っている内容の言語化サポート(最終判断は自分)
要確認:
- 数字・固有名詞・日付など、事実が大事な情報(ハルシネーションの温床)
- 法律・医療・税務など、間違いの代償が大きい領域
- 「最新情報」が必要な場面(学習データは時点が古い可能性)
7-5. 仕組みが分かると、AI が怖くなくなる
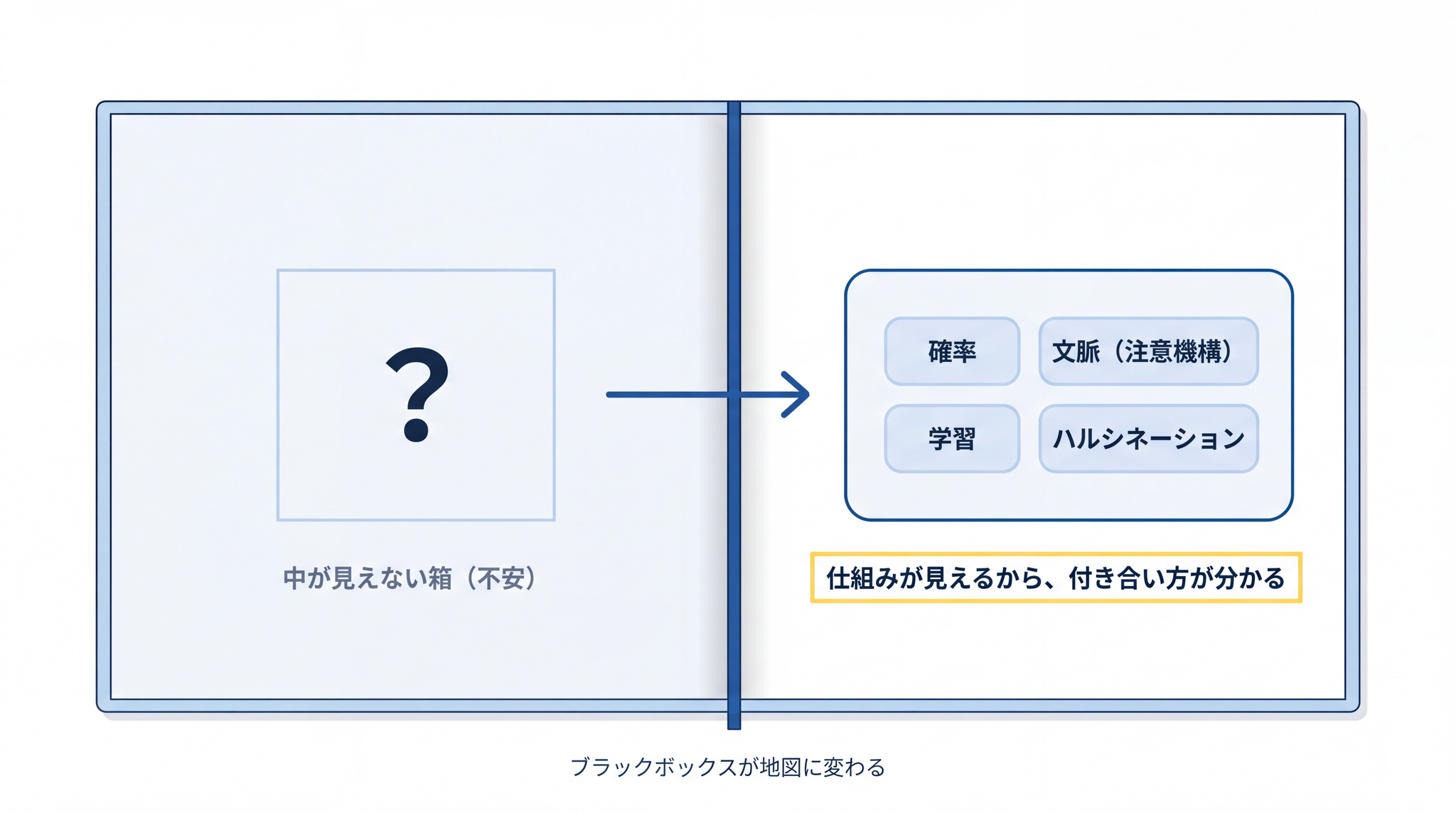
AI は怖いもの、得体の知れないもの、と感じる方は少なくないと思います。「中身がブラックボックス(中が見えない箱)」という言葉が、その不安をよく表しています。
AI の中で起きていることのおおまかな地図が、いま手元にあります。
- 同じ質問に違う答えが返るのは、確率で単語を選んでいるから
- 文脈を読めるのは、注意機構で大事な単語にしっかり目を向けているから
- 自然な会話ができるのは、3 段階の学習で人間の好みに合わせて磨かれているから
- ハルシネーションが起きるのは、真偽を保証する仕組みが入っていないから
「中身が見えない」から不安だったものが、「 仕組みが見えるから、付き合い方が分かる 」に変われば、AI はずいぶん扱いやすい道具になります。
この理解をもとに、次に読むなら「ハルシネーション ── AI に「本当」の感覚が無い、という話」がつながりやすいです。「AI が自信満々で嘘をつく理由」を、本記事で見た仕組みと直接結びつけて読めます。
あわせて読んでみてください:
- 「AI でできること、できないこと ── 仕組みで整理する『地図』」── 何に任せて、何に任せないかの全体像
- 「コンビニ・職人・科学者 ── ChatGPT・Claude・Gemini はなぜ違うのか」── 各社の違いを「目指している場所」から整理
- 「『欲しい答え』が返ってくる聞き方 ── プロンプト 5 つの型」── AI への指示を上手にするコツ
- 仕事で AI を活用するための体系立てたノウハウも、別記事として近日公開予定です。
出典・参考文献
-
専門的には「教師ありファインチューニング(Supervised Fine-Tuning / SFT)」と呼ばれます。 ↩
-
Kalai, A., Nachum, O., Vempala, S., & Zhang, G. (2025). “Why Language Models Hallucinate.” arXiv:2509.04664. https://arxiv.org/abs/2509.04664 ↩