
ハルシネーション ── AI に「本当」の感覚が無い、という話
目次
ChatGPT に質問したら、 ありもしない判例 を「これは本物です」と堂々と返された ── 2023 年に、米国でこんな出来事がありました。
航空会社相手の訴訟で、ある弁護士が ChatGPT に法律の調べものを頼んだのです。返ってきた 6 件の判例は、引用文も判事名も、本物そっくりに整っていた。けれど、どこを探しても、その判例は存在しなかった。すべて ChatGPT が作り上げた架空のものでした。
この現象は ハルシネーション と呼ばれます。AI が、もっともらしい言い方で事実と違うことを言い切ってしまう癖。この記事は、それがなぜ起きるのかを、AI の中身そのものから解きほぐします。
読み終えた頃には、ハルシネーションが AI の作り方から自然に出てくる現象 で、ちょっとした手直しで消えるものではないことが、自分の言葉で説明できるようになります。
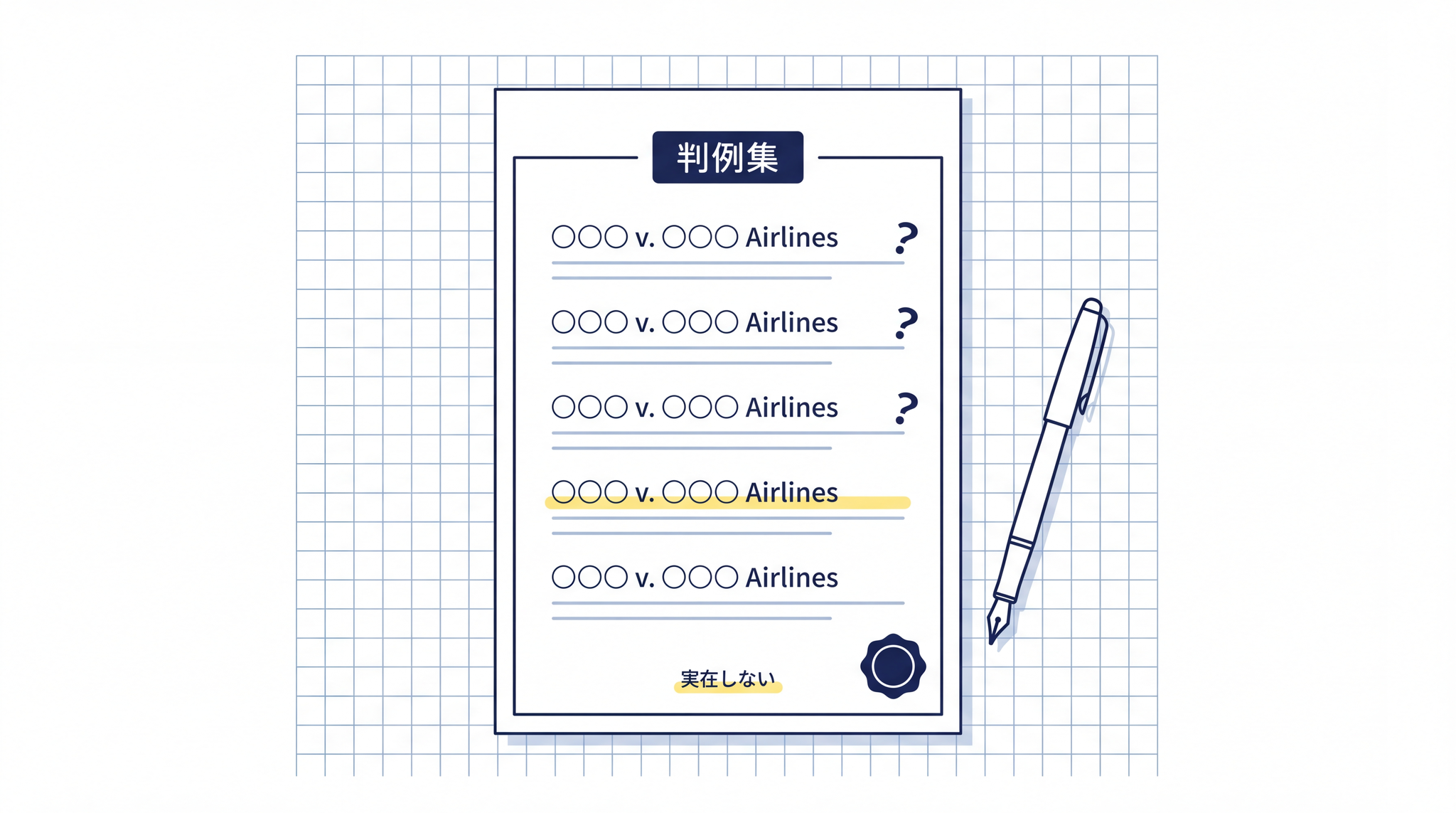
1. AI が「自信満々で間違える」瞬間 ── 実例から
担当した弁護士は、当時 30 年以上の経験を持つベテランでした。彼が ChatGPT を使ったとき、頭にあったのは「法律の検索エンジンのようなものだろう」という感覚です。
返ってきた判例の引用は、書式も、判事名も、引用文も、すべて本物そっくりに整っていた。それを信じて書面に組み込み、裁判所に提出した。
裁判官は架空判例 6 件すべてを偽物(fake)と認定し、5,000 ドルの制裁金を弁護士と所属法律事務所に科しました。確認を怠ったまま提出したことそのものが咎められた、という判断です。
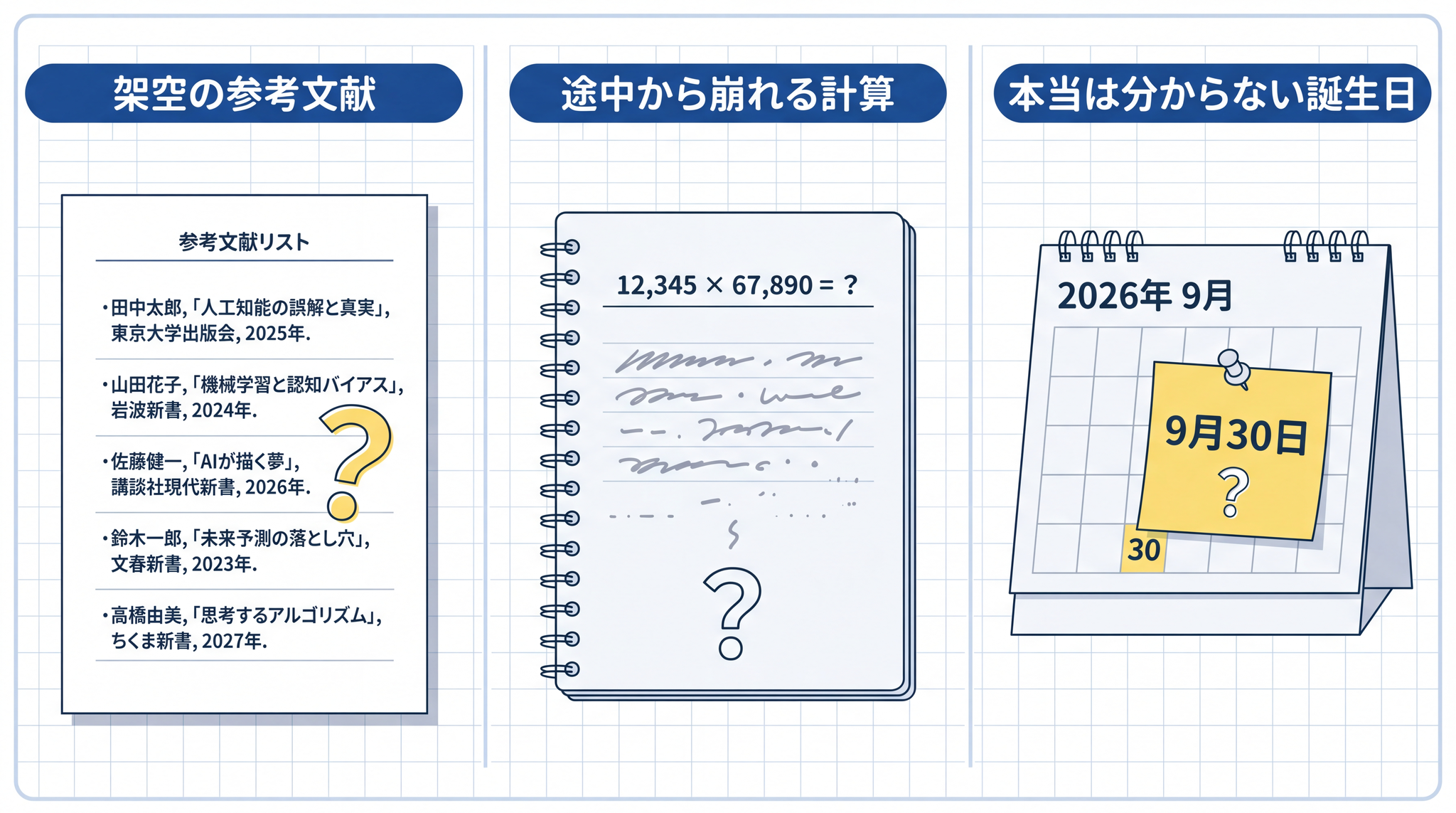
ハルシネーションは、判例の捏造に限りません。同じ仕組みから、いくつもの典型的な間違え方が出てきます。
- 論文の要約を頼んだら、引用された参考文献が架空のものだった
- 桁数の多い掛け算を頼んだら、最初の数桁は合っていたが、途中から数字が破綻した
- 誕生日を聞いたら、「分かりません」と答える代わりに「9 月 30 日」のような具体的な日付を堂々と返してきた
OpenAI が 2025 年に発表した論文 Why Language Models Hallucinate1 の中で、まさにこの誕生日の例が引かれています。AI は、誕生日のように「学習した文章の中にパターンが無い事実」については、当てずっぽうで具体的な日付を返してくる。
「秋頃」と言わずに「9 月 30 日」と言ってしまう。
“Bluffs are often overconfident and specific, such as ‘September 30’ rather than ‘Sometime in autumn’ for a question about a date.”1
共通しているのは、返ってくる答えが「 もっともらしい 」という一点です。形式が整っていて、文体も自然で、自信満々に見える。けれど、中身は事実と違う。
この「もっともらしさ」が、なぜ AI の構造から必ず出てくるのか ── ここから本題に入ります。

2. 「ハルシネーション」という名前の意味
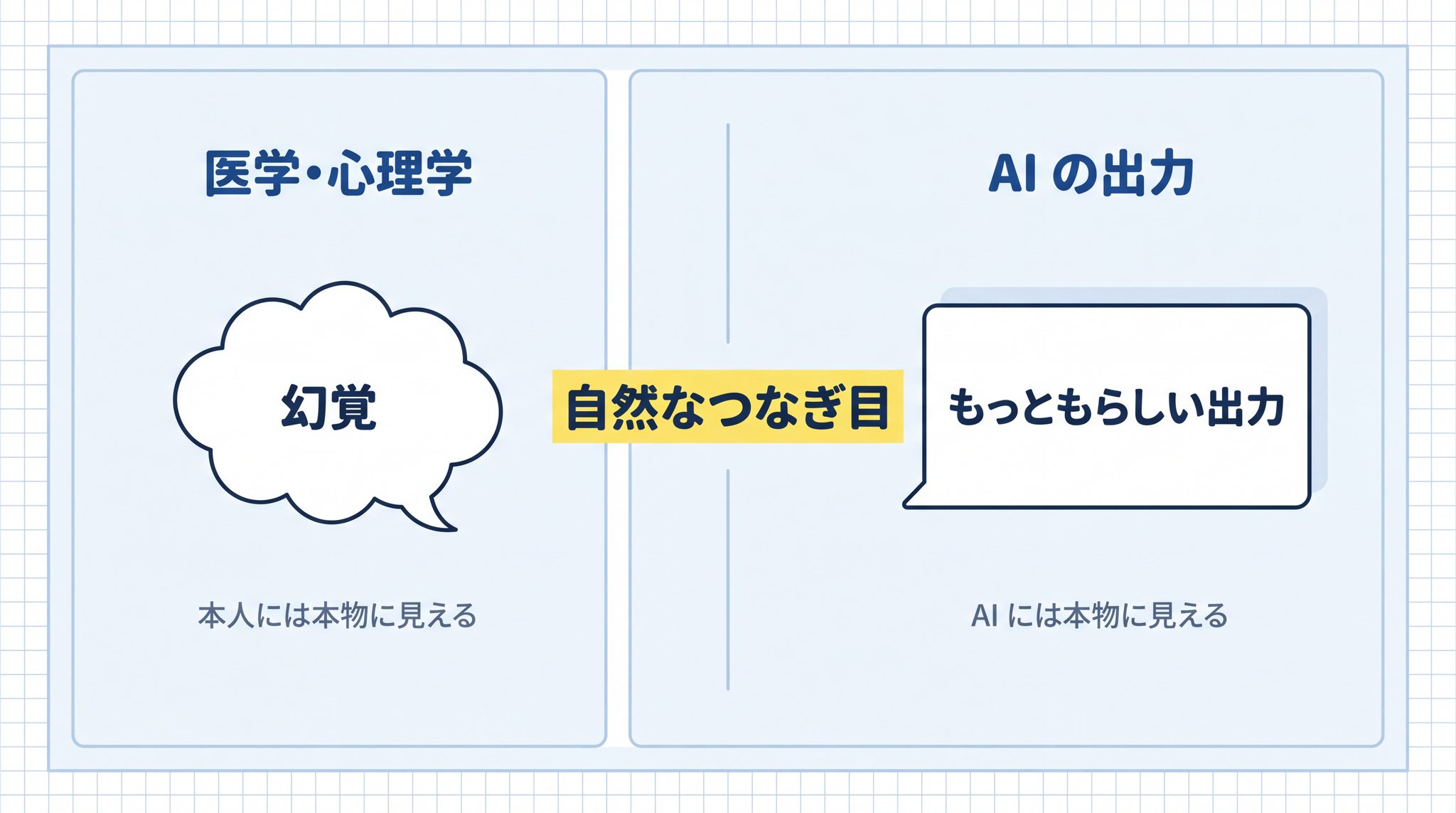
「ハルシネーション」という英単語は、もともと医学・心理学で使われる言葉で、幻覚を指します。実際にはそこに無いものを、本人は確かに見ている、聞いている、と感じてしまう状態です。
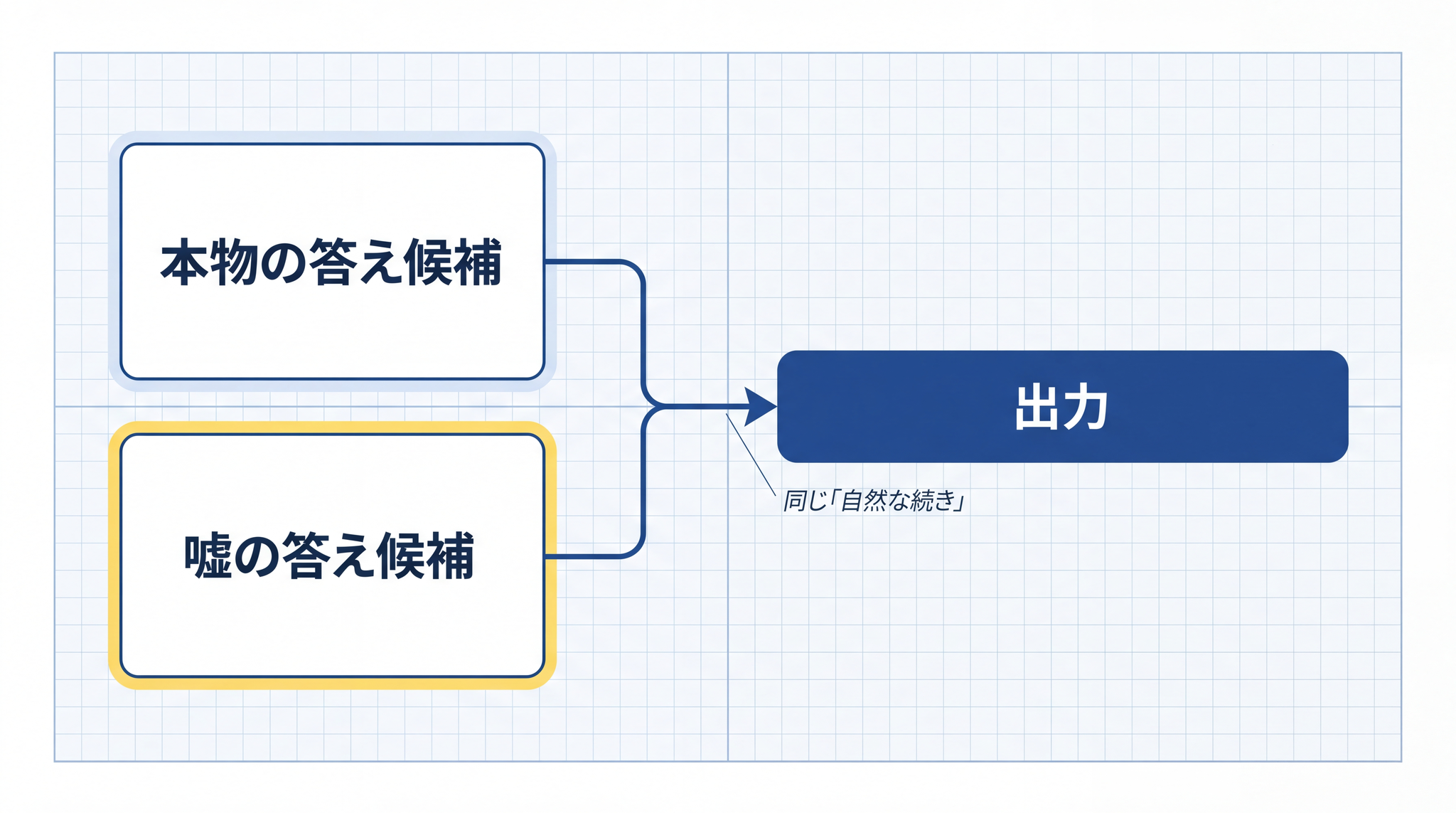
AI の話にこの言葉が当てられたのは、出力された内容が「本人にとっては自然なつなぎ目」として出てきているからです。AI の中で「事実と違う」という警告が立ち上がっているわけではない。「これは怪しい」というブレーキが内部にあって、それを破って嘘をついている、という構図でもありません。
AI にとっては、本物の答えも嘘の答えも、 同じ「自然な続き」として並んでいるだけ なのです。
ここで用語の注意を一つ。「AI が嘘をつく」と書くと、ダマす意図があるように響きますが、AI に意図はありません。事実と本当でないことを見分ける仕組みそのものを持っていないだけです。
「自信満々」も比喩で、AI に主観的な自信があるわけではありません(§6 で詳しく見ます)。
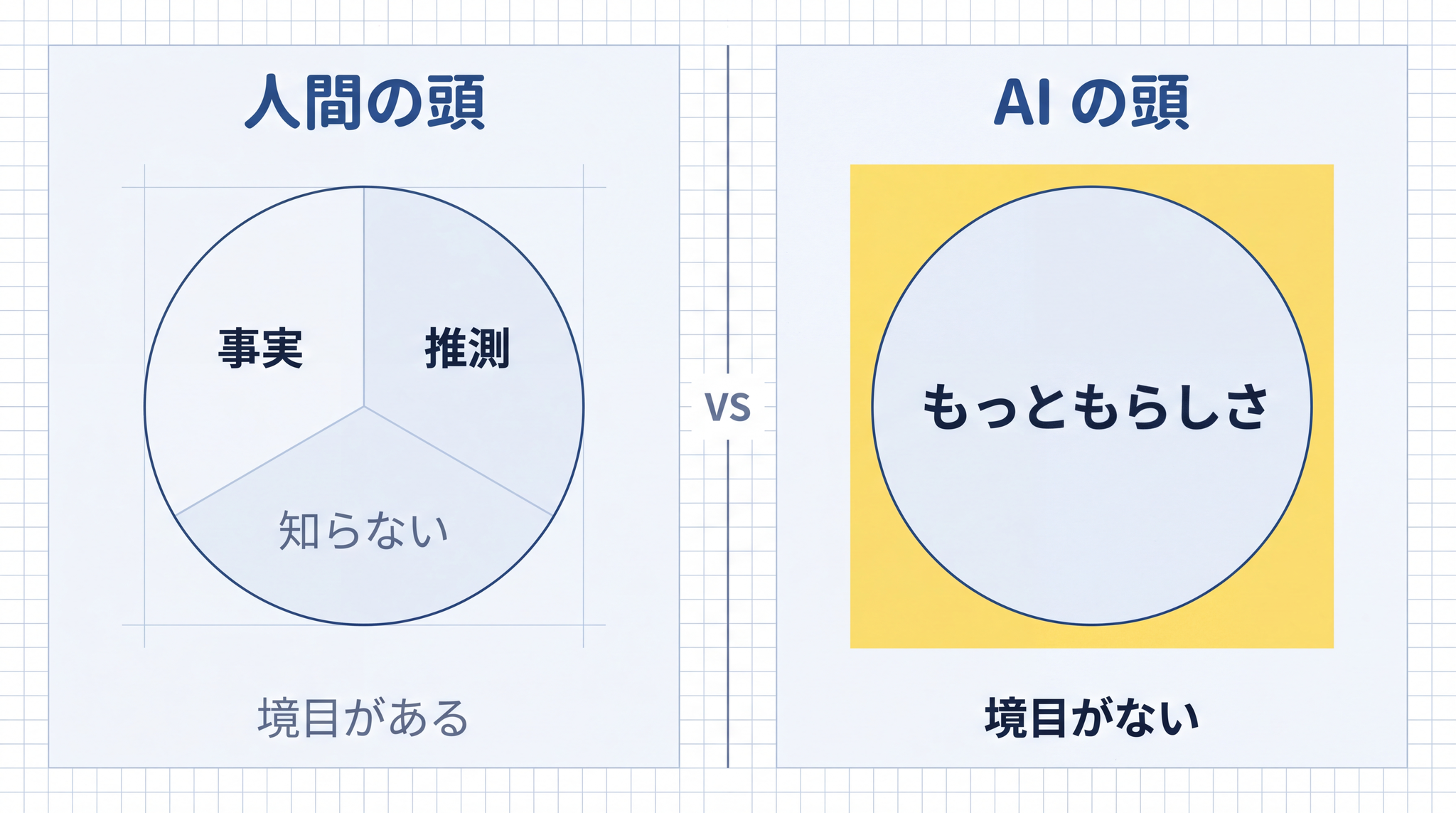
3. AI の頭の中には「本当」のラベルが無い
ハルシネーションの正体は、ここに尽きます。AI の頭の中には、「これは本当」「これは嘘」というラベルが、 どこにも貼られていない。
これは比喩ではなく、AI を作る側の OpenAI が公式ブログで明言している事実です。
“Language models first learn through pretraining, a process of predicting the next word in huge amounts of text. Unlike traditional machine learning problems, there are no ‘true/false’ labels attached to each statement.”
(言語モデルはまず、膨大な文章の中で「次の単語を当てる」という事前学習を通して学ぶ。従来の機械学習の問題と違って、一つひとつの記述に「本当 / 嘘」のラベルは貼られていない。)2
これを、人間の頭と並べてみるとはっきりします。
人間が何かを「知っている」とき、その知識には、おおよそ 3 種類のラベルが付いています。
- 事実として知っている(昨日の朝、コーヒーを飲んだ)
- 推測している(同僚は今日来ないかもしれない、机の上が片付いていたから)
- 知らない(隣の家の住人の出身地)
そして大事なのは、人間はこの 3 つの境目を、自分でだいたい引けることです。「これは推測」「これは知らない」と、内側で区別できる。
AI の頭の中には、この 3 領域の境目がありません。すべての単語の並びは、「どれくらい自然な続きか」という見え方だけで扱われている。「事実」「推測」「知らない」の区別は、 最初から存在しない。
OpenAI の同じブログは、もう一歩踏み込んで「事前学習はハルシネーションを助長する。言語モデルは、自分が読んだデータをそのまま再現するように作られているのであって、真実を検証するようには作られていない」と書いています。
本当か嘘かを確かめる仕組みは、もとから組み込まれていない。では、なぜそういう作りになっているのか ── 次の章で見ていきます。
4. なぜそうなるか ── 学んだのは「事実」ではなく「もっともらしさ」
「本当のラベルが無い」と言われても、実感が伴わないかもしれません。AI を作るときに、なぜ事実のラベルを付けてあげないのか。なぜ「言葉のつながり方」だけを学ぶ作りになっているのか。
LLM(文章を扱う AI の中身)の学習の中心にある作業は、次に来る単語を当てるというものです。詳しくは別記事「LLM の仕組み」で扱っています。
インターネット規模の文章を AI に読ませ、「文章の途中までを見せるから、続きの単語を当ててごらん」をひたすら繰り返す。当てたら正解、外したら不正解。それだけ。
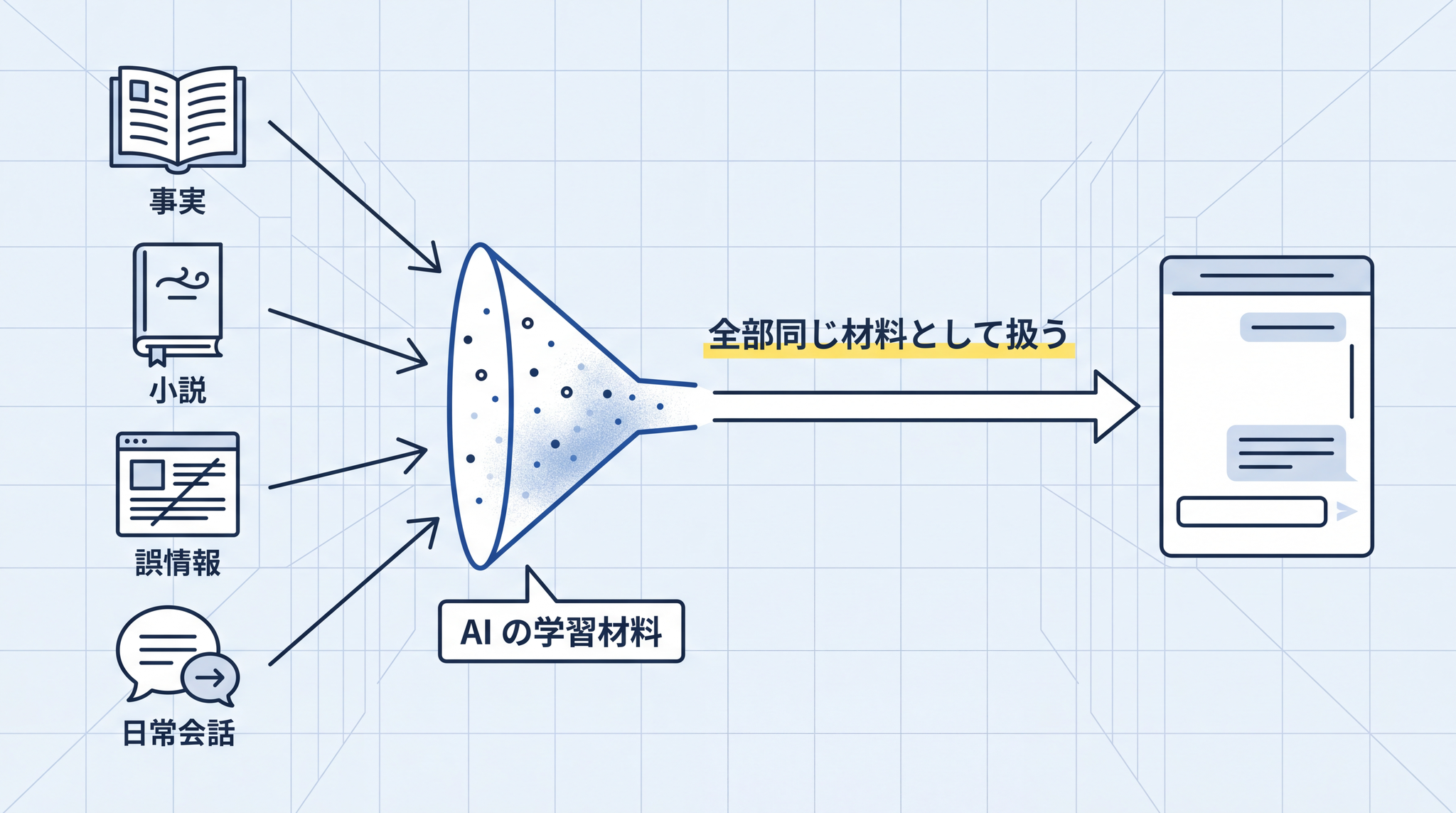
ここで一度、立ち止まってみてください。この訓練の中に、「事実を確かめる」という作業は一度も入っていません。
AI が読んだ文章の中には、事実が書かれた本もあれば、小説もあり、誤情報を含むウェブページもあり、人々の日常会話のログもあります。AI に向かって「これは事実」「これは創作」「これは間違い」とラベルを付けて読ませているわけではない。
ぜんぶ “次の単語” を当てる練習の材料として、同じように扱われます。
OpenAI の 2025 年の論文1は、この仕組みからハルシネーションが必ず出ることを、「正しいか間違いか」を見分ける問題として説明しています。簡単に言うと、こういうことです。
ハルシネーションは謎の現象ではない。「正しい / 間違い」の見分けの誤りから自然に出てくるだけだ。間違った記述と事実が区別できないなら、AI が学習の段階でハルシネーションを起こすのは、当然の結果だ。1
事実と嘘を見分けられる仕組みがあれば、その見分けの精度を上げていけば、ハルシネーションは減っていく。けれど学習用の文章には、「これは事実」「これは嘘」という印が、そもそも付いていない。
だから、いくらモデルを大きくし、データを増やし、計算を回しても、消えない。これは技術が未熟だからではなく、 AI の作り方そのものから来る限界 です。
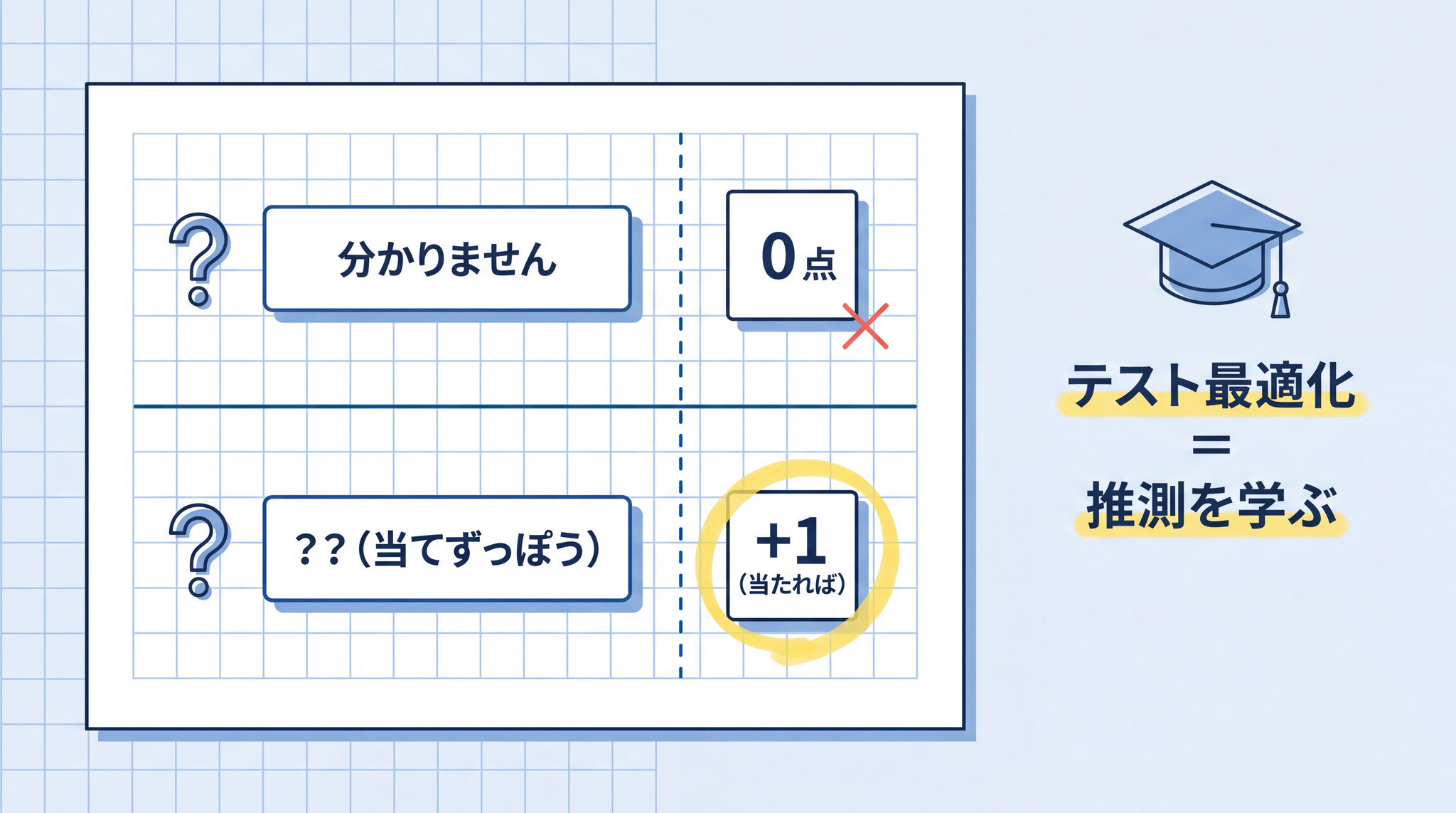
さらに、評価のしかたが事態を悪化させています。AI の性能テストの多くは、「正解か不正解か」の正解率だけを見ます。「分かりません」は ゼロ点 、当てずっぽうなら偶然当たる可能性がある。
AI は「自信満々に推測するほうがスコアが高くなる」と学んでしまう。同じ論文の表現を借りれば、AI は “よい受験者” として育てられた結果、ハルシネーションを起こしてしまうのです。
学習の作り方、評価のしかた。両方が同じ方向に効いて、ハルシネーションは深く根を張っています。
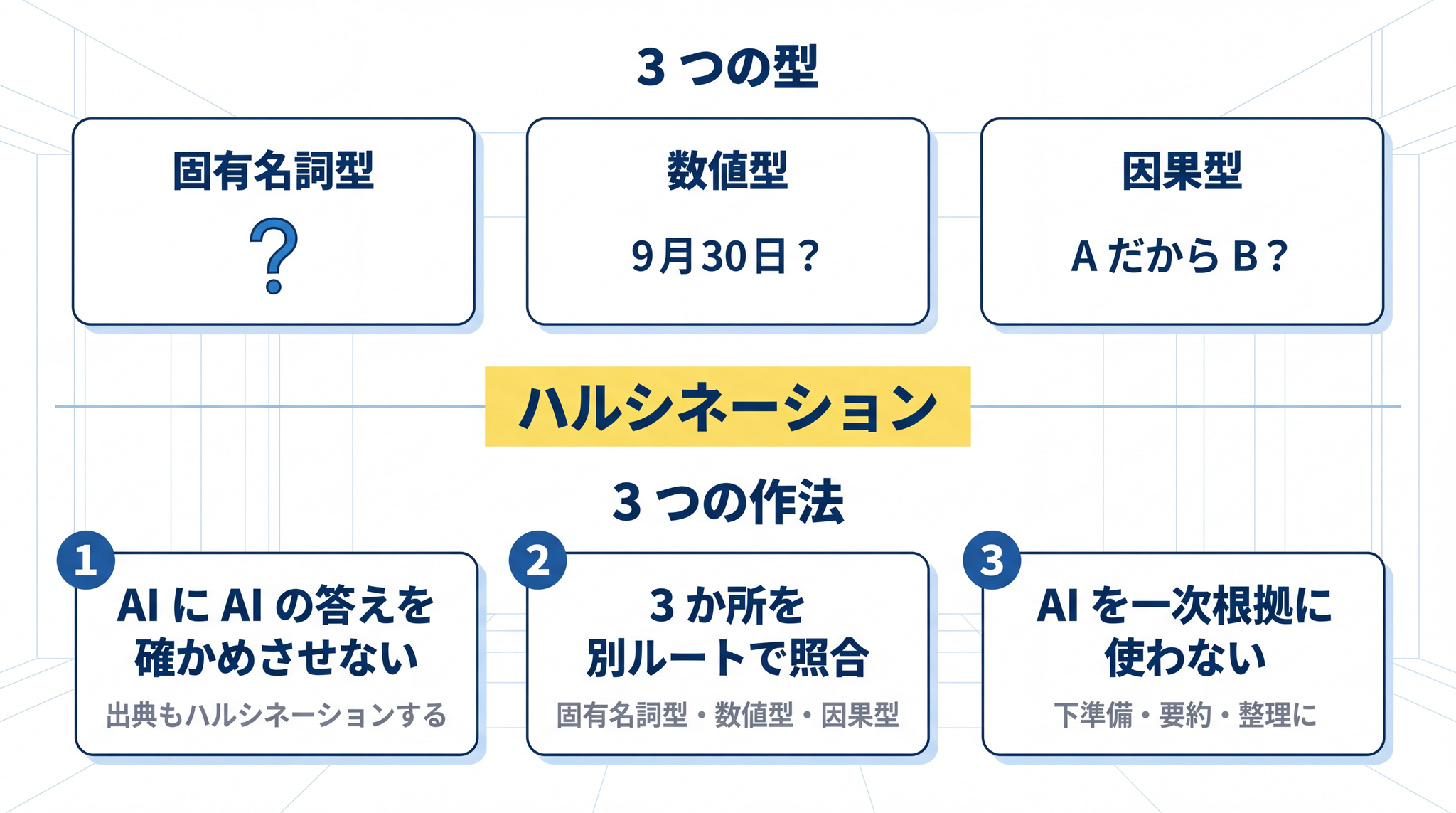
5. ハルシネーションの 3 つの型
ハルシネーションは、出方にいくつかの型があります。学術的にはより細かい分類もありますが、日常的に出会う粒度では 3 つに整理できます。
| 型 | 出方 | ”もっともらしさ” の源 |
|---|---|---|
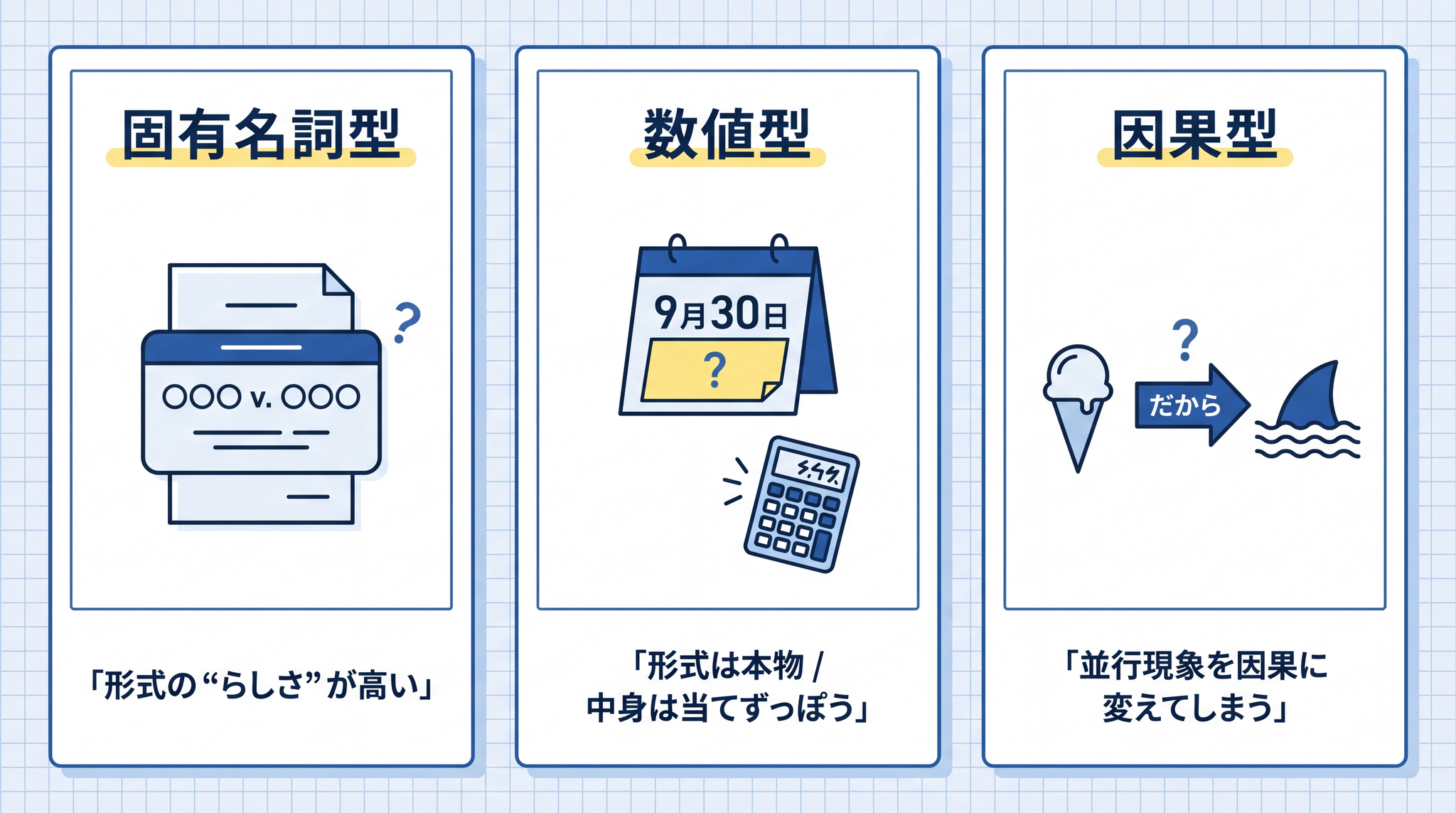
| 固有名詞型 | 存在しない人名・書名・判例名・論文名を、本物そっくりの形式で出す | AI が読んだ大量の文章の中に、似た形式の固有名詞があふれていた |
| 数値型 | 誕生日・統計・計算結果を、もっともらしい具体値で捏造する | 数字の並び方には、学習した文章上の典型的なパターンがある |
| 因果型 | 関係のない 2 つの事象を「A だから B」とつなげて、論理的に説明してしまう | 「だから」のような接続詞には、続きの言葉に強い偏りがある |
冒頭の事例は、典型的な固有名詞型でした。判例の引用形式(原告 v. 被告、判事名、判例集の巻号)を AI は学んでいるので、形式の「らしさ」が極めて高い文字列を迷いなく生成できる。
中身が無くても、 形だけは本物になる。
数値型の代表が、§1 で見た「9 月 30 日」の例です。誕生日のような事実は人ごとにバラバラで特定パターンがないけれど、「○月○日」という形式自体は強烈なパターンを持っている。
だから形式はもっともらしく、中身は当てずっぽうになる。桁数の多い掛け算が途中から破綻するのも、同じ仕組みです。
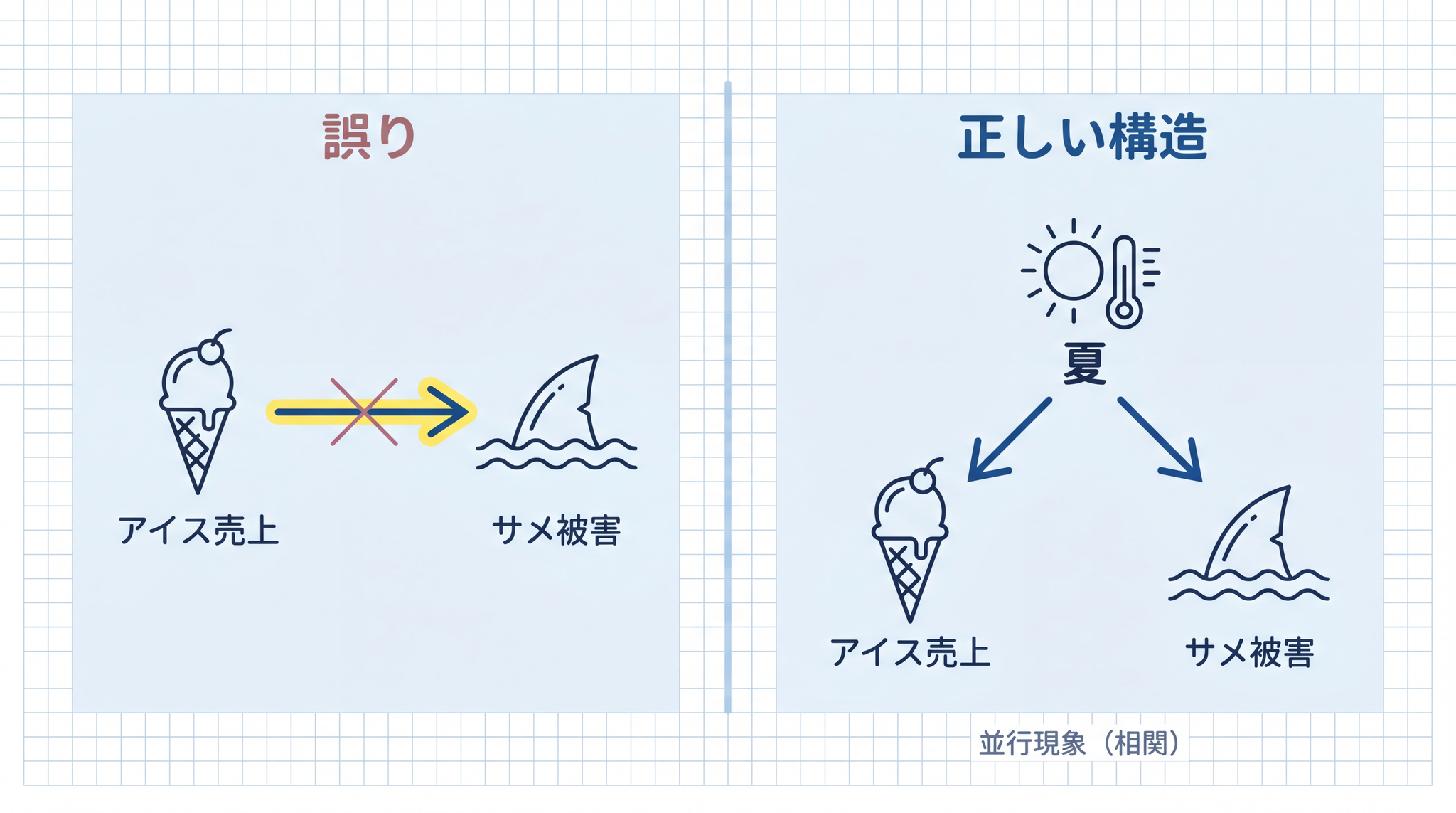
因果型は巧妙です。AI は「A が起きると B が起こる」「C なので D」の言い回しを大量に学んでいるので、実際には因果関係のない 2 つの事象でも、もっともらしい接続詞で結びつけられる。
「アイスクリームの売上が伸びると、サメの被害が増える」── どちらも「夏」によって起きている 並行現象(相関) にすぎないのに、「アイスがサメを引き寄せる」と論理的な説明文を、すらすら作れてしまう。
型が違えば、警戒の張り方も変わります。具体的な付き合い方は §7 で見ていきます。
※ 学術的な分類をもっと知りたい方は、末尾の参考文献にある Huang et al. 20233 のサーベイ論文をどうぞ。
6. 「自信」と「正しさ」の分離
一言で言えば、こうです。AI が「分かりません」と返してきても、それをそのまま信じてはいけません。AI は自分の限界を正確には知れないからです。
AI は事実と嘘を見分けられないまま「もっともらしい」答えを返す ── では、自分が間違えていることに、AI 自身は内側で気づけるのでしょうか。
部分的には気づけます。Anthropic(Claude を作っている AI 企業)の 2022 年の研究4(タイトルを訳すと「言語モデルは、自分が何を知っているか、だいたいは知っている」)が示したのは、大型の AI が「自分の答えがどれくらい合っていそうか」を、ある程度の精度で予測できるということです。
ただし、ここに 2 つの穴があります。
1 つめ:学習時に出会わなかったタイプの問題に直面すると、AI は「自分はこの答えを知っているか」の見積もり自体を外します。自分が知らないことを、知らない。
テリトリーの外にいるとき、 AI はその外側にいることに気づかないまま 、自信ありげに答えます。

2 つめ:もっと根が深い問題があります。ChatGPT などの AI には、「人間に喜ばれる返事のしかた」を覚えさせる追加の訓練が入っています。
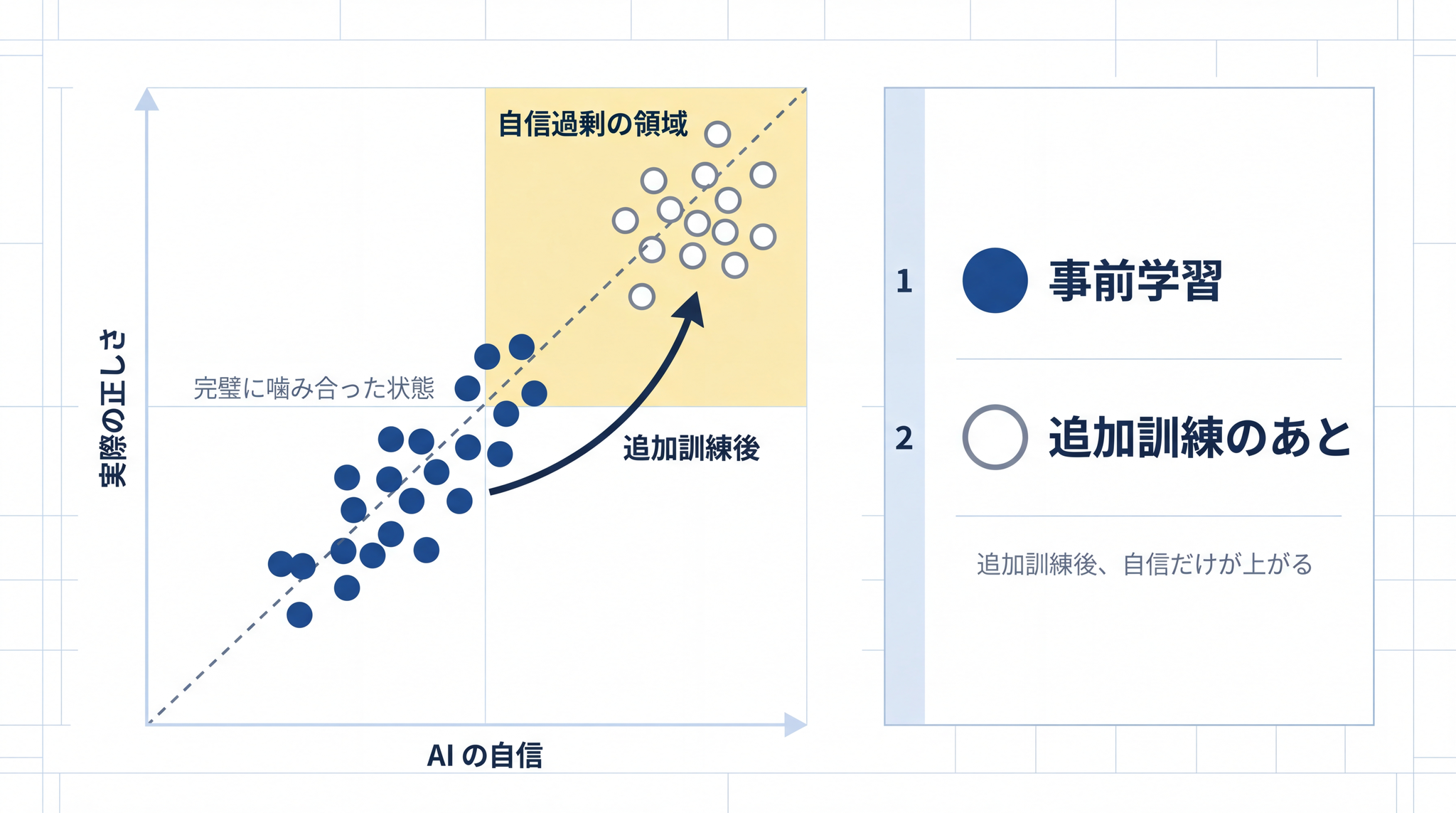
OpenAI 自身が公式の技術文書で、この追加訓練を通すと AI の自信が崩れると書いています。
事前学習の段階のモデルは、自信の度合いと、実際の正答率がきちんと噛み合っていた。ところが、現在の追加訓練を通すと、その噛み合わせが崩れる。5
つまり、人間に喜ばれる対話を学ぶ追加訓練を通すと、 間違っているのに断定口調で答えるようになる。 「迷わず答える AI」を人間が好んだ結果、自信過剰な AI が出来上がっています。
さらに同じ技術文書は、「AI が『分かりません』と慎重な姿勢を見せること自体が、ユーザーの過信を招く危険がある」とも書いています。自信のある答えも、慎重な答えも、同じ「もっともらしさ」の上に乗った、同じ性質の出力です。「分かりません」という返事もまた、信じ切ってはいけない。
7. 型ごとの警戒の張り方
ここまでの原理を踏まえると、AI の答えとの付き合い方も型ごとに変わることが見えてきます。
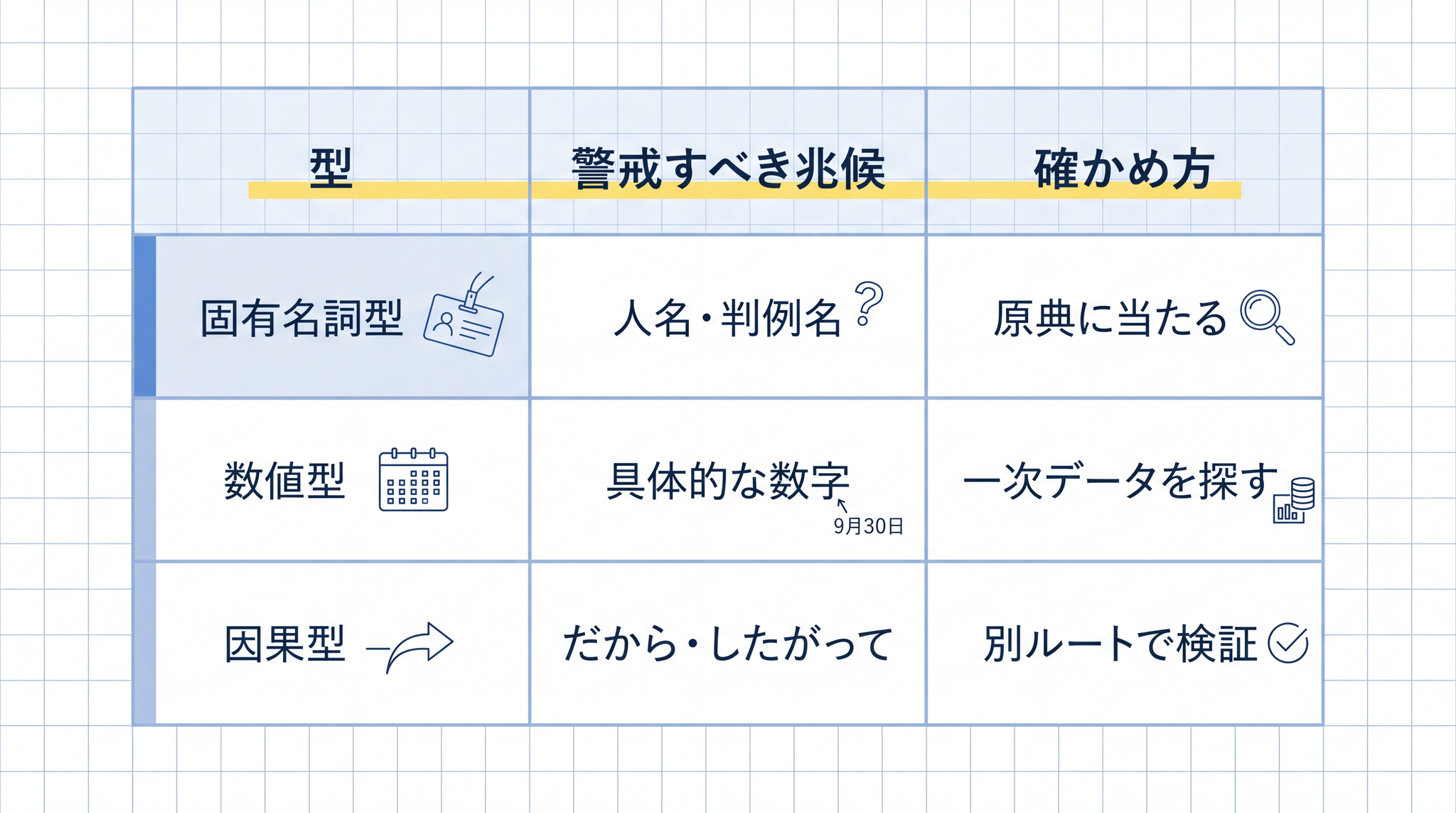
| 型 | 警戒すべき兆候 | 確かめ方 |
|---|---|---|
| 固有名詞型 | 人名・書名・判例名・論文名・URL が答えに含まれている | 必ず原典に当たる。引用された出典そのものを検索する |
| 数値型 | 日付・統計・計算結果が具体値で返ってきた | 一次データを探す。公式統計・原論文・自分の手計算で照合 |
| 因果型 | 「A だから B」「C のため D」と因果でつないだ説明が出た | 因果関係そのものを別ルートで検証。並行して起きただけなのか、本当に原因と結果なのかを確かめる |
固有名詞型は、AI の出力でいちばん危ない型です。形式が整っているほど信用したくなる。冒頭の事例で弁護士がだまされたのも、まさにこの心理でした。判例の引用形式が完璧だったので、中身を確かめる動機が湧かなかった。
形式が整っているほど警戒する ── 固有名詞型の付き合い方の核心です。
数値型では、 「具体的すぎる数字」を疑います。 「秋頃」ではなく「9 月 30 日」、「半分くらい」ではなく「47.3%」── 細かさが返ってきたら、いったん立ち止まる。
因果型は、見抜きづらい型です。「だから」「したがって」のような接続詞は、AI が形式的にもっともらしい説明を組み立てる定番の道具で、それが論理の飛躍を覆い隠します。
因果は人間が独立に確かめる。AI に「本当に A が原因か?」と聞いても、AI の検証もまた「もっともらしさ」の上に乗ります ── 新しい確認の答えも、最初の答えと同じ性質の出力です。
たとえばこんな体験があります。
AI 研修でこの 3 つの型を説明するとき、私はよく「天気ワーク」を使います。参加者に AI へ「今日の天気は?」と聞かせ、その答えと窓の外を見比べてもらう。Web 検索が ON の状態だと、AI は正しい天気情報を取ってきて正確に答えます。
そこで Web 検索を切れる設定に変えて、もう一度同じ質問をします。今度は AI が「もっともらしい」天気を推測で返してくる。「本当だ、外の空と全然違う!」という声が毎回上がります。
仕組みを聞くより、目の前で起きる体験のほうが、ハルシネーションの感触を伝える。この手応えが、型ごとの警戒の話を自分のものにする一歩です。
8. 確かめる作法 ── 本当の感覚は人間が持つ
§7 の表と、このあとの 3 か条を合わせると、明日から動ける作法になります。
AI を実用で使うとき、確かめる作法はしばらく人間の側に残る前提で動くことになります。
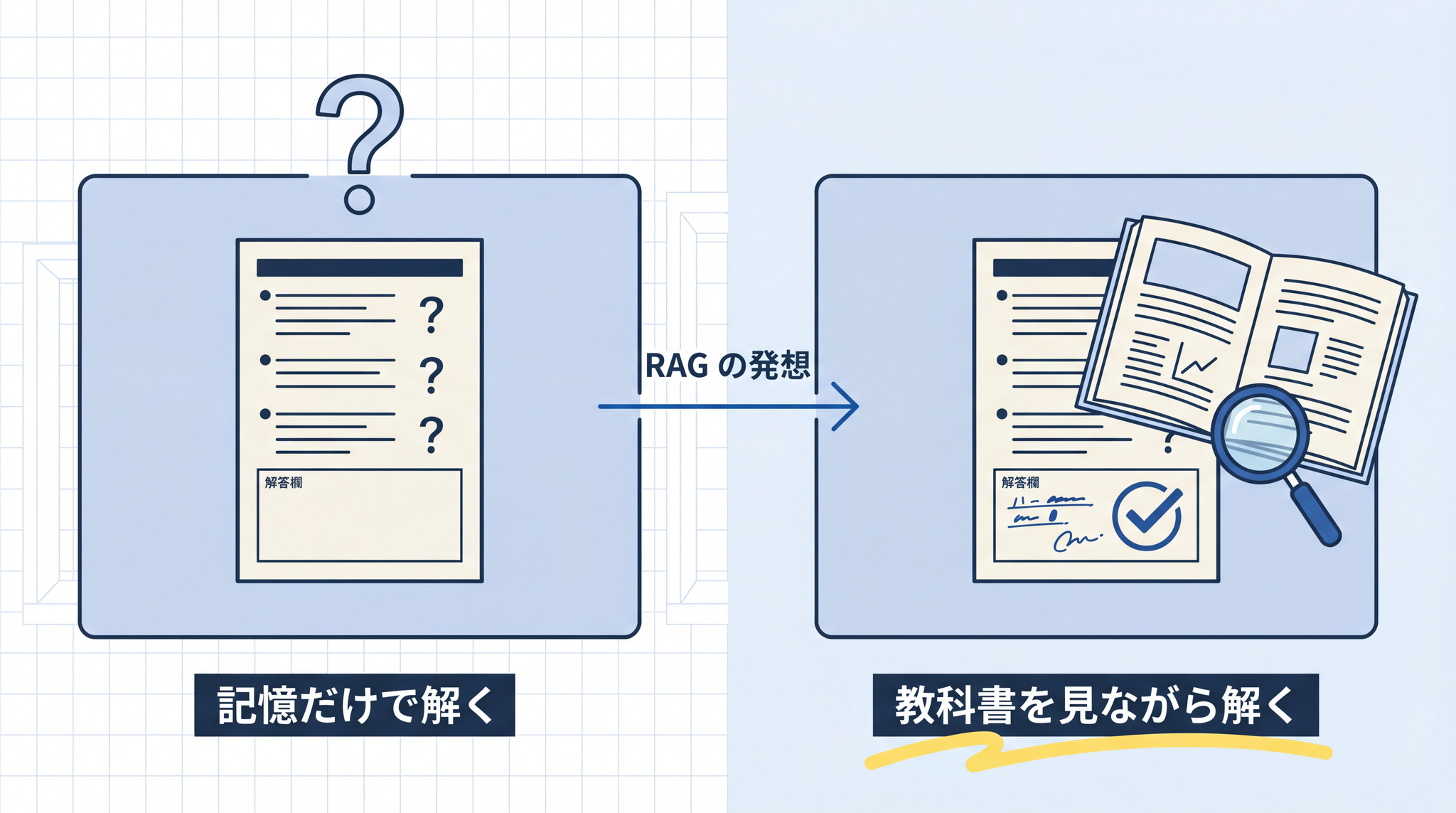
ハルシネーションを減らす技術は、2023 年以降に広く採用されるようになりました。代表が「外部の情報を先に調べてから答えさせる仕組み」(RAG)── AI が答える前に外部のデータベースやウェブを検索し、その結果を材料にして答えさせます。
試験で言えば、「記憶だけで解く試験」から「教科書を見ながら解く試験」への切り替えです。効果は実証されています。
ただし、これも 消すための技術ではなく、減らすための技術 です。専門家のあいだでは「RAG は減らすが、消さない」と言われます。
検索が空振りしたとき、検索結果が曖昧だったとき ── AI は再び確率の海に戻って、もっともらしい単語を埋め始める。
OpenAI 自身も、最新モデルでハルシネーションが消えていないことを公式に認めています。
“Even as models get more advanced, they can still hallucinate, confidently giving wrong answers instead of acknowledging uncertainty.”
(モデルがどんなに進化しても、ハルシネーションは起きる。AI は不確かさを認める代わりに、自信満々に間違った答えを出してしまう。)2
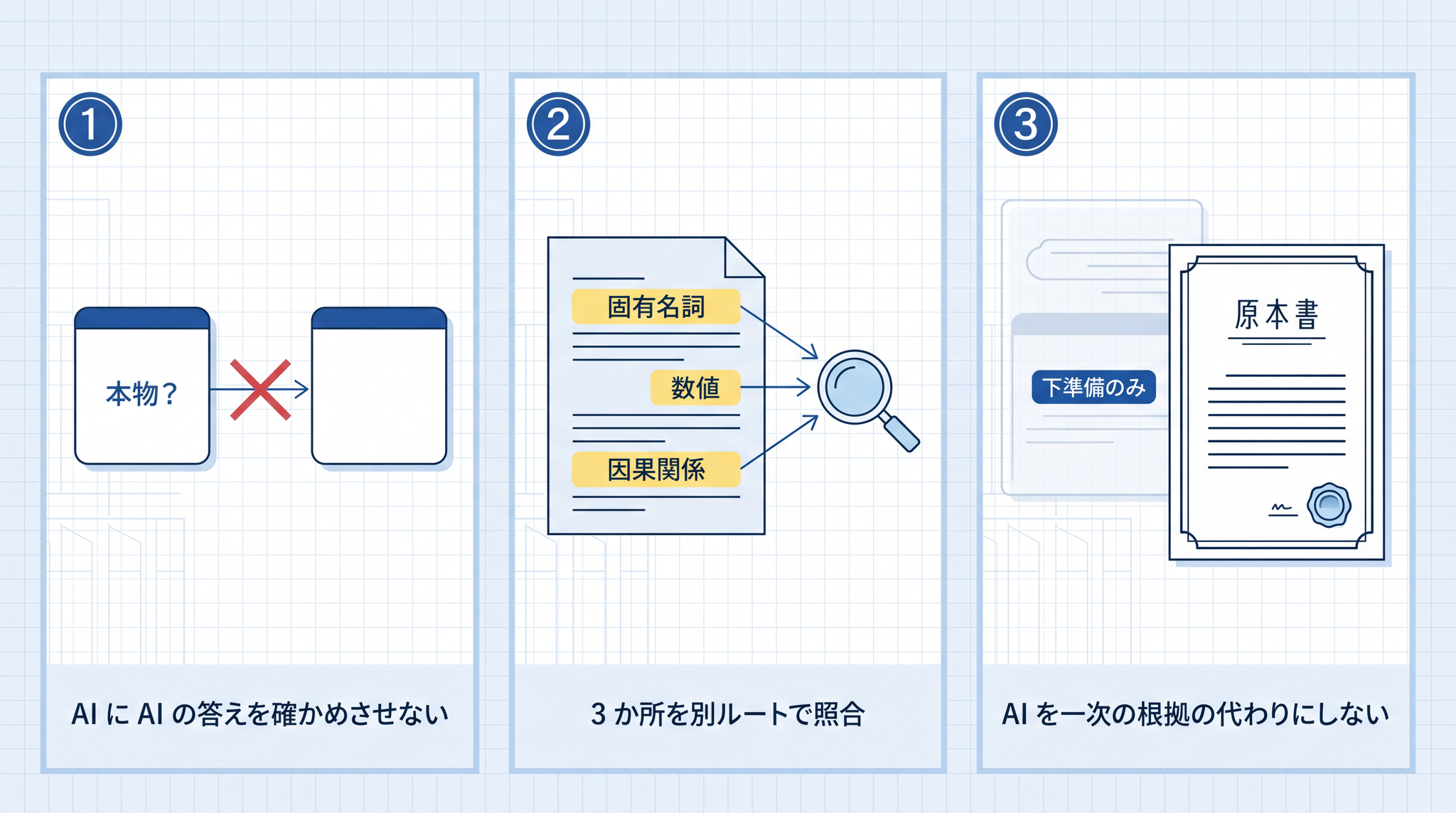
実用上の作法を 3 つだけ挙げます。
-
AI に「出典を出して」と言って終わりにしない。AI は出典そのものをハルシネーションします。
冒頭の弁護士は、判例の真偽を ChatGPT 自身に確かめました。
「この判例は本物ですか?」
ChatGPT:「Yes, it is a real case」(はい、本物の判例です)
続けて「925 F.3d 1339(11th Cir. 2019)として実在する。Westlaw と LexisNexis でも見つかる」と、判例集の巻号と検索可能性まで具体的に返してきた。
すべて捏造でした。
-
固有名詞・数値・因果関係の 3 か所を抜き出して、それぞれ別ルートで照合する。記事全体を一度に確かめようとすると挫折します。型を絞って局所的に当たる
-
AI を「答えのもと」にしない。下調べ・要約・整理には強い道具ですが、最終的な根拠そのものを AI に置かない
ハルシネーションは、AI の中に「本当」のラベルが無いことから自然に出てくる現象です。AI の作り方そのものから来る限界で、ちょっとした手直しでは消えません。
だからこそ、「本当」の感覚を持つ役割は、人間の側に残ります。AI は、もっともらしさを組み立てる達人として、これからも便利な道具であり続けます。けれど、 達人 ≠ 真実の保証人。
言い換えれば、下調べ・要約・整理を任せるのは安心です。 固有名詞・数値・因果関係だけは、自分で確かめる ── この使い分けが、AI と長く付き合っていく一番シンプルな作法です。
具体的には、Google 検索や公式サイトで突き合わせるのが基本です。
ここまでの話を、1 枚にまとめると、こうなります。
ここまで読んでくださった方には、関連する記事として以下をおすすめします。
- 「LLM の仕組み ── 同じ問いに違う答えが返ってくる、その理由」── 確率で単語を選ぶ仕組みを、もう一段掘り下げて
- 「AI でできること、できないこと ── 仕組みで整理する『地図』」── AI に何を任せ、何を任せないかの全体像
- 「『欲しい答え』が返ってくる聞き方 ── プロンプト 5 つの型」── 思った答えが返らないときの聞き方