
AI に教科書を渡してから聞く ── 自分の文書を答えに使わせる方法
目次
- 1. AI が “知らない” のは、書かれていなかったから
- 2. AI の知識には 2 種類ある
- 2-1. 頭の中に持っている知識(学習)
- 2-2. その場で渡される知識(コンテキスト)
- 3. 答える前に “教科書を引く” ── RAG の正体
- 4. 教科書はどう探されるのか
- 4-1. 同じ言葉を探す(キーワード検索)
- 4-2. 似た意味を探す(意味検索)
- 4-3. 両方を組み合わせる(ハイブリッド検索)
- 5. 身近な道具は “教科書を渡す” 仕組み
- 5-1. Claude Projects(Anthropic)
- 5-2. NotebookLM(Google)
- 5-3. ChatGPT のファイル添付(OpenAI)
- 5-4. 共通する性質
- 6. 教科書を渡しても、読み違えは起きる
- 6-1. 教科書にあるのに、読み違える
- 6-2. 教科書に無いから、補ってしまう
- 6-3. だから “確かめる” は人間の役割
- 7. 学習・RAG・資料添付 ── 場面ごとの使い分け
- 7-1. 学習(ファインチューニング)── 研修で覚えさせる
- 7-2. RAG(教科書を引く)── 机に検索端末を置く
- 7-3. 資料添付(コピペ・PDF を貼る)── その場で書類を手渡す
- 7-4. 一覧で見比べる
- 8. 次にやってみると良いこと
- 8-1. NotebookLM に PDF を 1 つ読ませてみる
- 8-2. ChatGPT や Claude のファイル添付で試す
- 8-3. 引用元のページを必ず開く
- 関連記事
- 出典・参考文献
町内会の規約 PDF を ChatGPT に貼り付けて「来月の役員会の議題は何ですか」と聞いてみる。返ってくるのは、規約のことではない、ありふれた一般論。取扱説明書や家族の医療履歴でも、同じことが起きる。
これは、聞き方を間違えたわけではありません。AI は 自分が学んできたことしか知りません 。手元の文書を答えに使わせるには、別の仕組みが要ります。
その仕組みの名前は RAG(Retrieval-Augmented Generation、答える前に教科書を引く仕組み)。社内資料の検索 AI、議事録のまとめ、自分の組織のマニュアル AI ── こういう道具の裏側で広く動いている共通の考え方です。
1. AI が “知らない” のは、書かれていなかったから
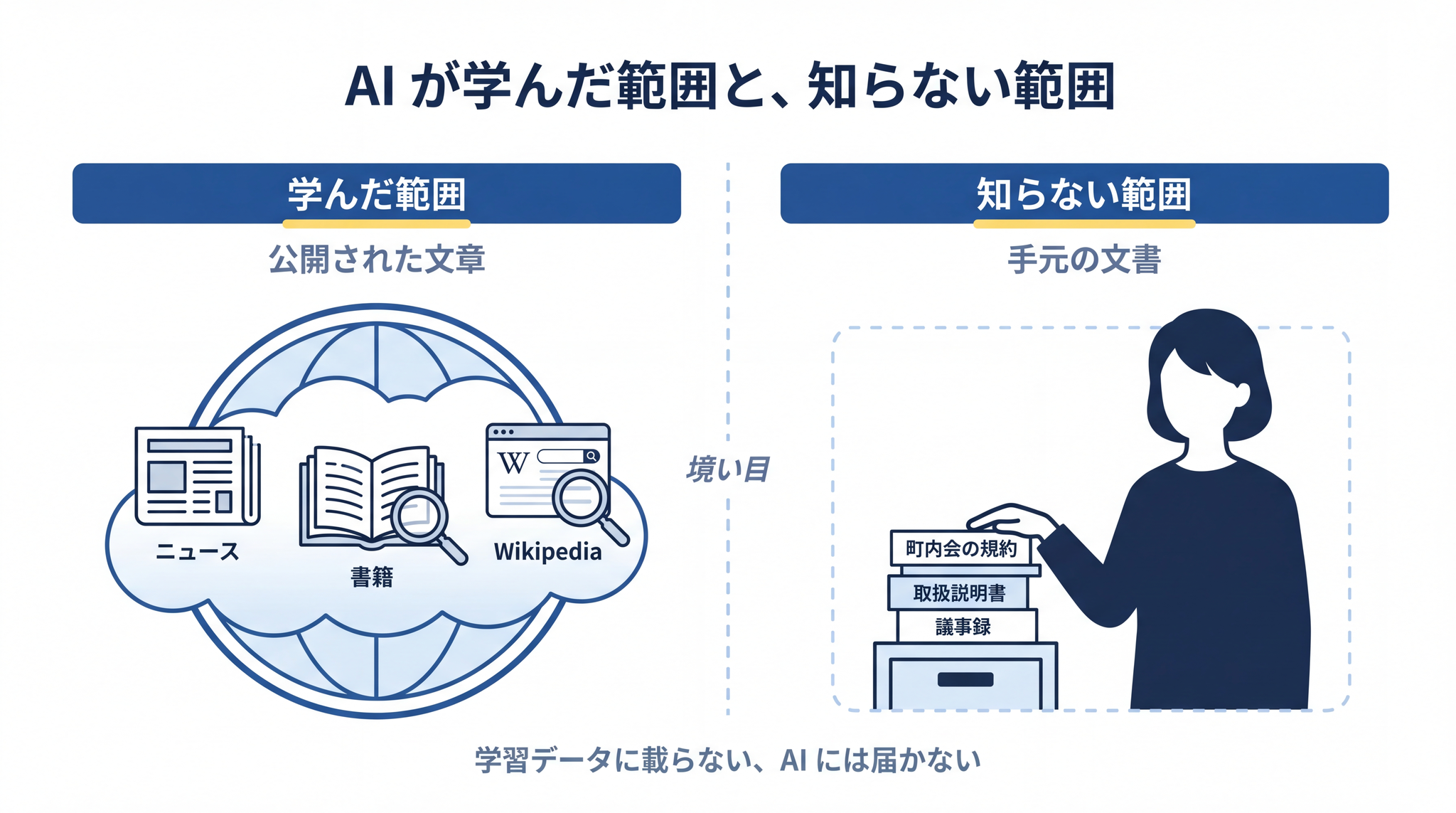
ChatGPT・Claude・Gemini ── これらの AI は、世の中に出回っているものすごい量の文章を読んで、その中身を頭の中に身につけています。これを「学習」と呼びます。
学習に使われる文章は、ニュース、Wikipedia、書籍、技術文書、ブログ ── インターネットに公開されている、誰でも読める範囲のものが中心です。学習が終わると、AI は学んだ内容を頭から取り出して答えを返せます。
ところが、AI が学んだ範囲には、当然入っていない文章が大量にあります。たとえば、
- あなたの町内会の規約
- 自宅の電子レンジの取扱説明書
- 家族の医療履歴メモ
- 自分が所属する組織の社内マニュアル
- 地元の自治会で交わされた議事録
- 学校で出されたレポートの参考資料 PDF
こうしたものは、どこにも公開されていません。AI が学ぶ機会もありません。だから直接尋ねても、関係のない一般論しか返ってこないわけです。「町内会の規約の話」と「町内会についての一般的な話」は、AI から見ると別物。後者は学べたけれど、前者は学べなかった、ということです。
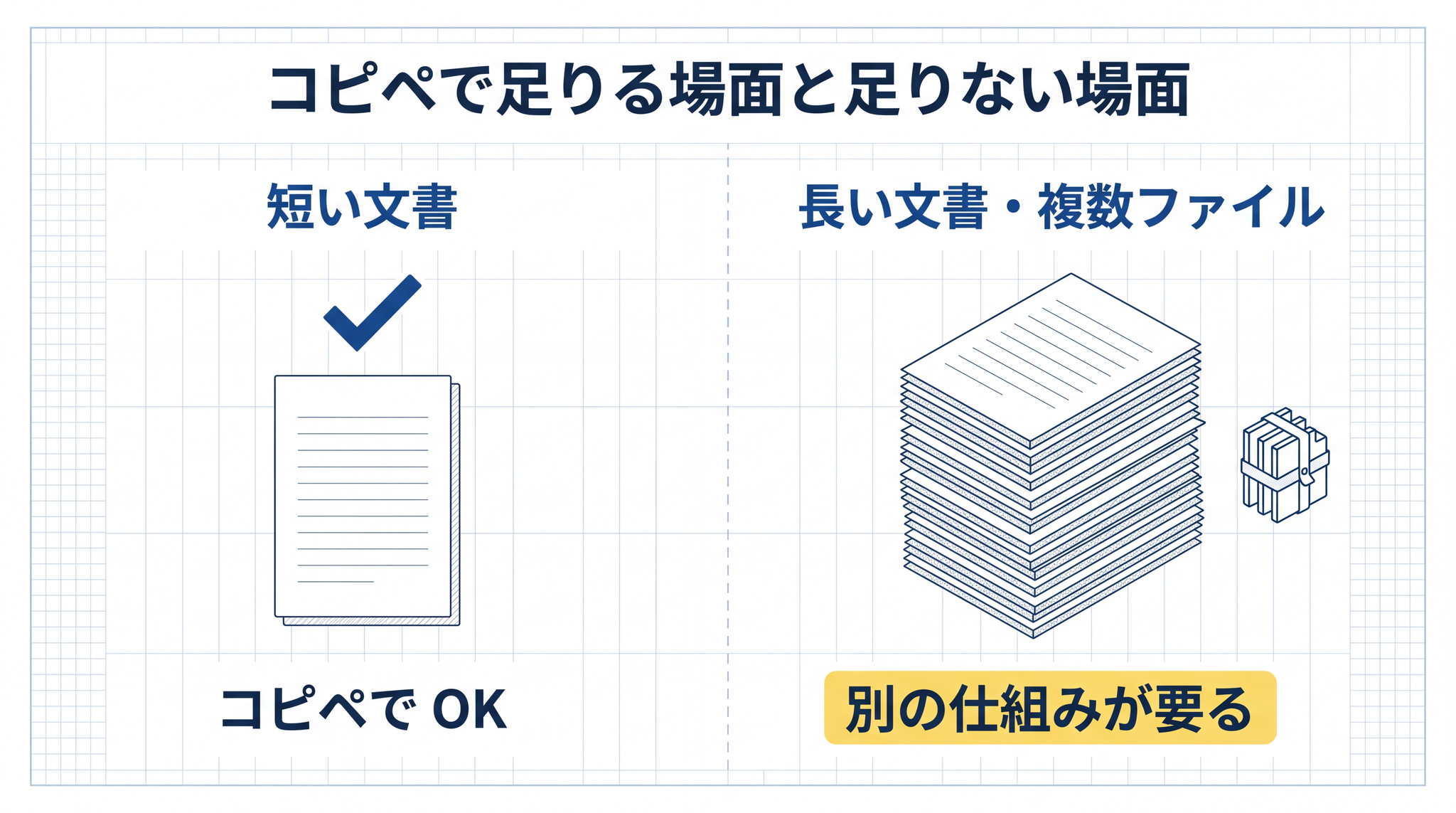
ここで多くの方が、まず思いつくやり方があります。「その PDF をコピペして AI への質問文に貼ればいいのでは」。これは半分正解です。短い文書なら、たしかに動きます。けれど長い PDF や、複数のファイルを束ねて参照させたいときには、もう一段別の仕組みが要ります。
言葉の整理:聞き方が悪いから返ってこないのではありません。渡し方の問題です。聞き方の話は別記事の「『欲しい答え』が返ってくる聞き方 ── プロンプト 5 つの型」を参照してください。この記事では、答えに使わせたい文書をそもそもどう渡すかの話をします。
2. AI の知識には 2 種類ある
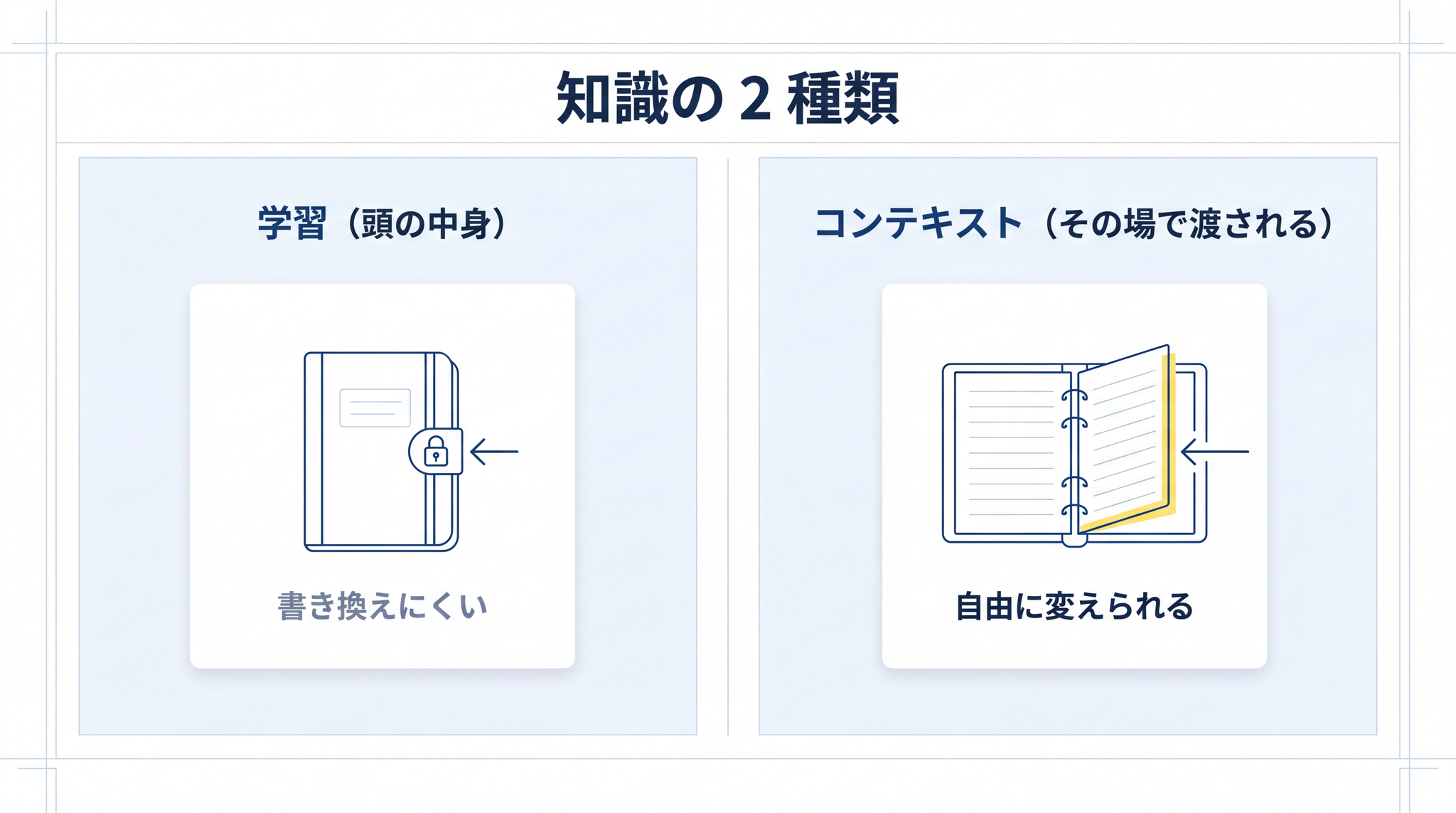
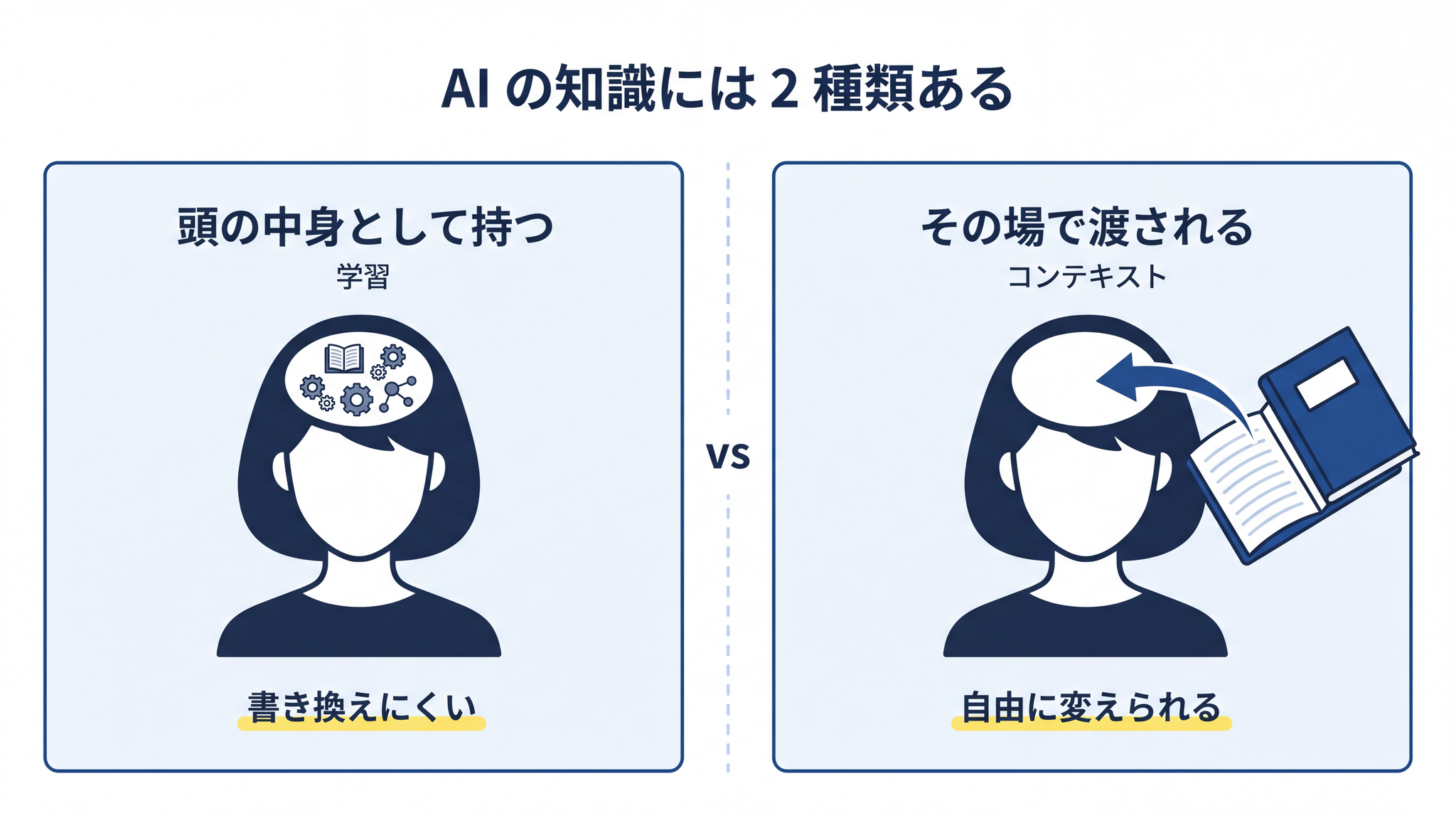
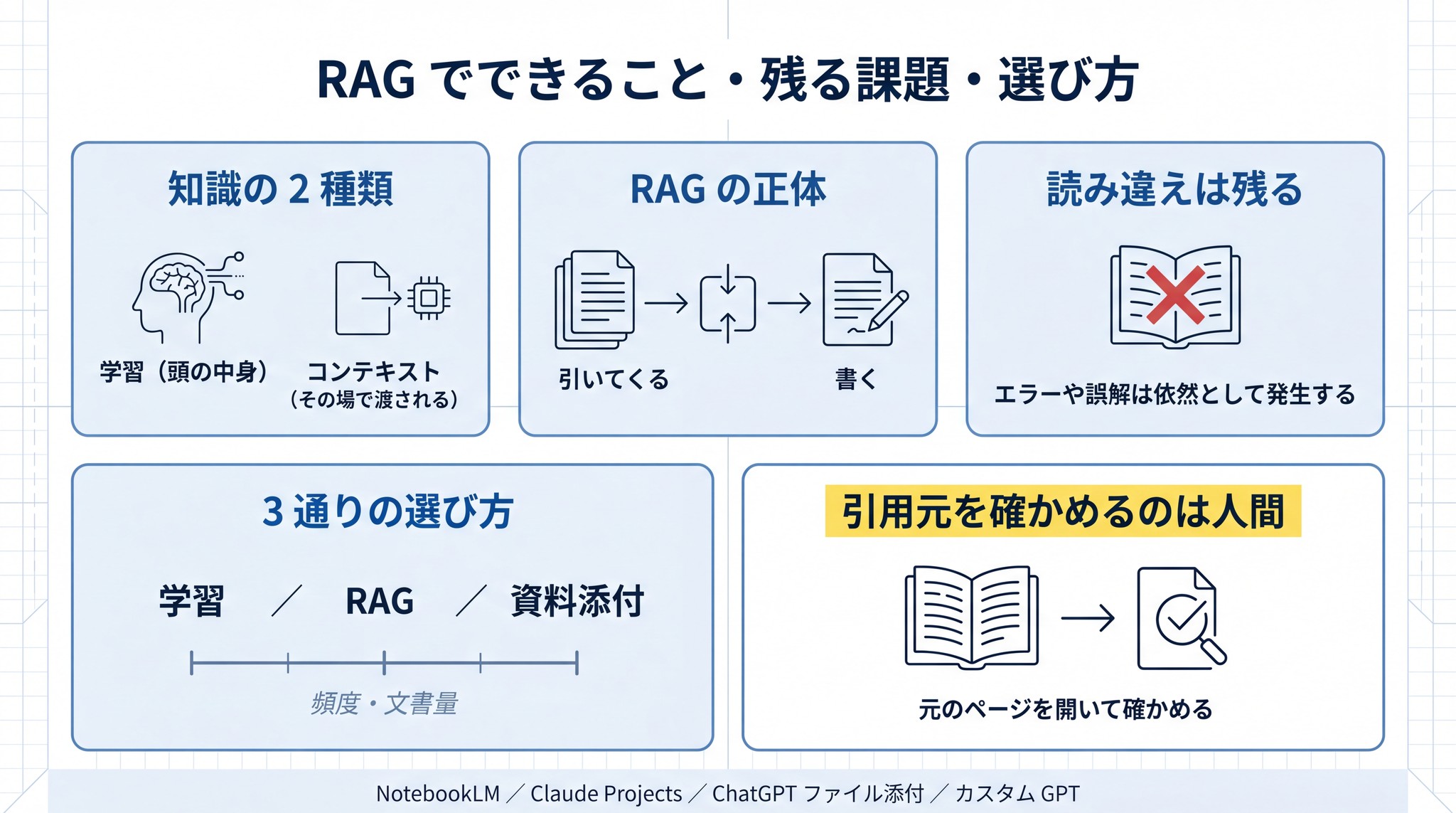
ここで、これから先の話の核になる区別を入れます。AI が答えを作るときに使う知識は、実は 2 種類あります 。
2-1. 頭の中に持っている知識(学習)
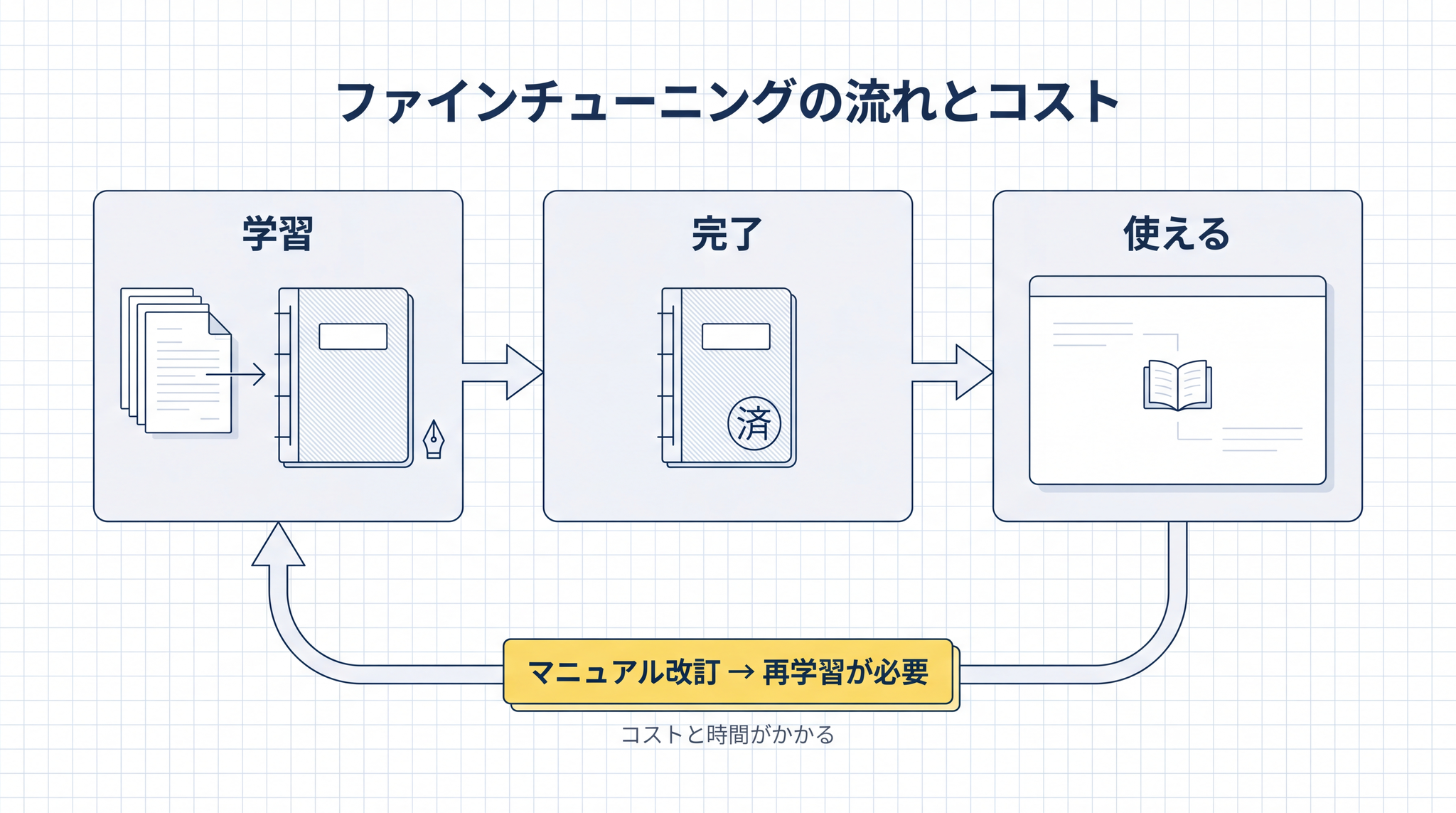
ひとつ目は、いま見たばかりの「学習で身につけた知識」です。AI の頭の中に、訓練のあいだに書き込まれているもの。一度学習が終わると、追加で書き込み直すには、改めて学習をやり直す必要があります(これをファインチューニングと呼びます。AI に特定の知識や文体を追加で学ばせること、と思ってください)。
ファインチューニングは、コストも時間もかかります。家庭の取扱説明書を読ませるたびに AI を再学習させる、というのは現実には無理があります。
2-2. その場で渡される知識(コンテキスト)
ふたつ目は、質問するときにその場で AI に渡す情報です。チャット欄に書き込む文章も、PDF の添付も、ここに入ります。AI はその場で受け取った情報を読んで、答えを組み立てます。
この「その場で渡される情報の入れ物」のことを、業界用語でコンテキストウィンドウと呼びます。AI が一度に見ていられる字数の上限、と思ってください。
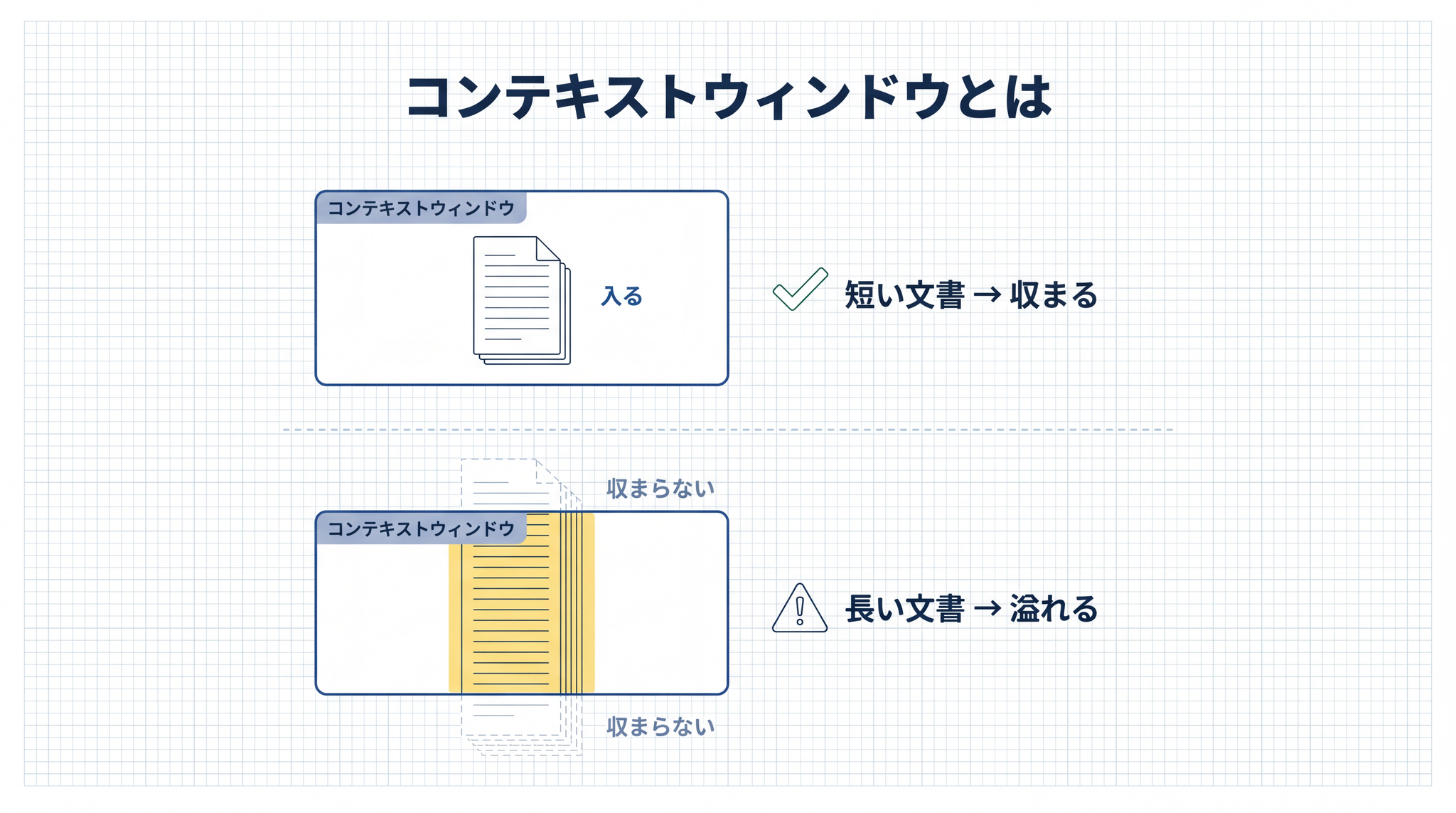
ここが大事なところです。 頭の中(学習)を書き換えるのは難しい 。でも、 その場で渡す情報は、いくらでも自由に変えられる 。
IBM の解説記事1 が、この区別をきれいな比喩でまとめています。学習だけで答えさせるのは「持ち込み禁止のテスト」。その場で文書を渡してから答えさせるのは「教科書持ち込みありのテスト」。
“It’s the difference between an open-book and a closed-book exam. In a RAG system, you are asking the model to respond to a question by browsing through the content in a book, as opposed to trying to remember facts from memory.”
(訳:持ち込み禁止のテストと教科書持ち込み可のテストの違いです。RAG では、記憶から事実を思い出すのではなく、本の中を調べながら質問に答えさせます。)
この 2 種類の区別が、ここからの話の土台になります。
もっと詳しく:AI の頭の中がどう作られているか、なぜ毎回違う答えが返ってくるかは、別記事の「LLM の仕組み ── 同じ問いに違う答えが返ってくる、その理由」で解きほぐしています。
3. 答える前に “教科書を引く” ── RAG の正体
ここでようやく RAG の話に入ります。
RAG は Retrieval-Augmented Generation の頭文字を取った名前です。直訳すれば「検索を加えて強化した文書生成」といった意味になりますが、そのままでは分かりにくい。かみ砕くと、こうなります。
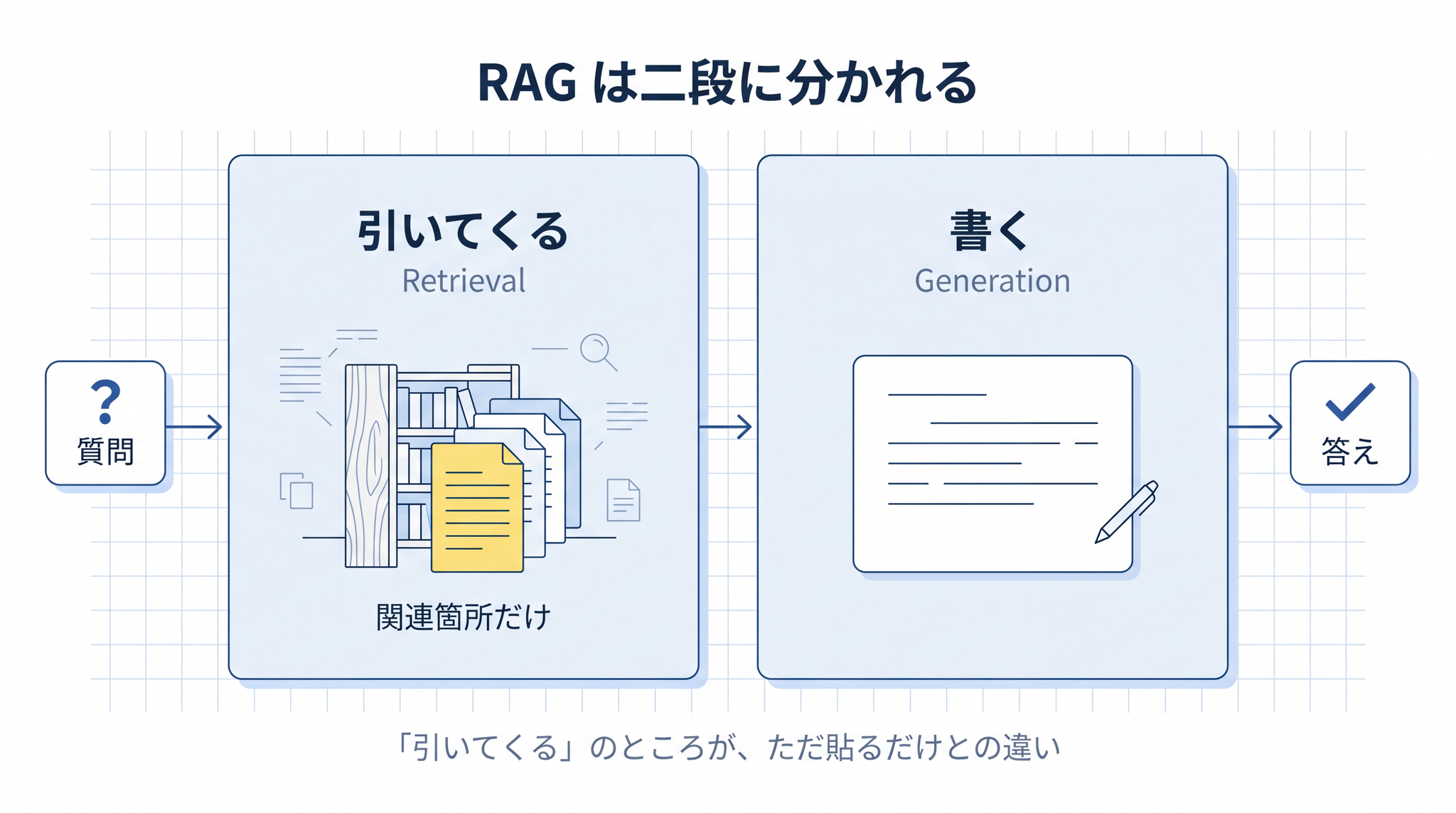
AI が答えを書き始める前に、関連する文書を自動で検索して引いてきて、それを読みながら答えを書く仕組み。
二段に分かれています。
- 引いてくる(Retrieval)── 質問に関係しそうな文書を、用意してある資料の中から自動で探す
- 書く(Generation)── 引いてきた文書を読みながら、答えを組み立てる
引いてくる のところが要です。AI は、質問に関係する箇所だけをつまみ出して、それを読みながら答える。
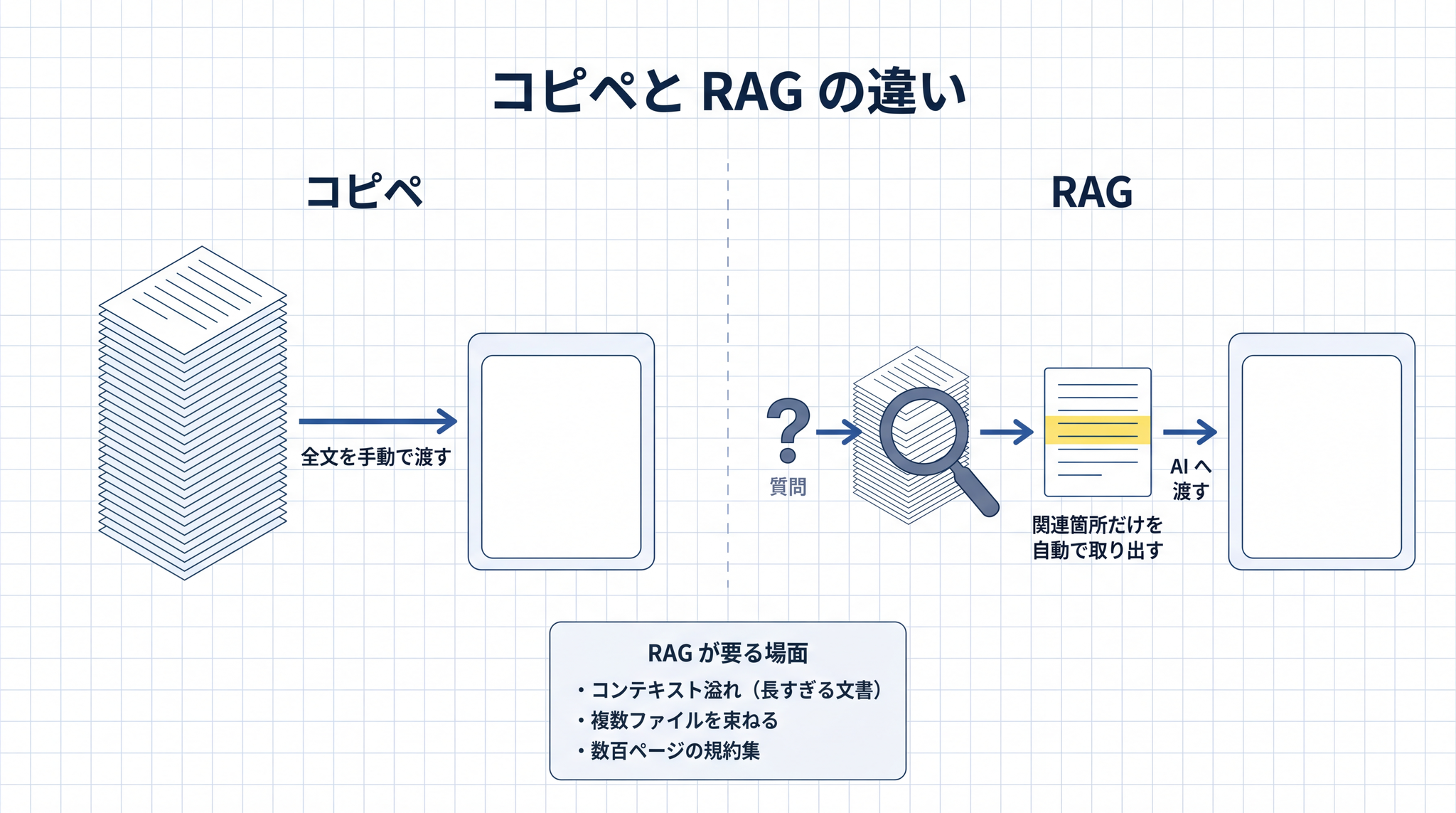
§1 の終わりで触れた「PDF をコピペで質問文に貼る」とは、ここが違います。コピペの場合、PDF の中身を全部 AI に押し込みます。短い文書ならそれで十分。けれど、
- PDF が分厚くて、コンテキストウィンドウに入りきらない
- 複数のファイルがあって、毎回どれを貼ればいいか分からない
- 数百ページの規約集の中から、関連する箇所だけ見せたい
こうした場面では、コピペでは追いつきません。RAG は必要な箇所を自動で取り出して AI に渡します。ここが「ただ貼るだけ」との違いです。
RAG の元になっているのは、Meta(旧 Facebook)と大学の共同研究チームが 2020 年に発表した論文2 です。当時はまだ ChatGPT も世に出ていませんでした。論文の中で著者たちは、RAG を「前もって覚えた知識と、そのつど外から引いてくる知識を組み合わせる仕組み」と定義しています。外部の文書を引いて AI に渡すやり方を広く RAG と呼ぶ使い方は、2020 年代以降に定着しました。
4. 教科書はどう探されるのか
「自動で引いてくる」と書きましたが、その引き方にも種類があります。この違いを知っておくと、「なぜかうまく引いてこられない」と感じたときに、原因を絞り込む手がかりになります。身近な言葉で 3 つに整理してみます。
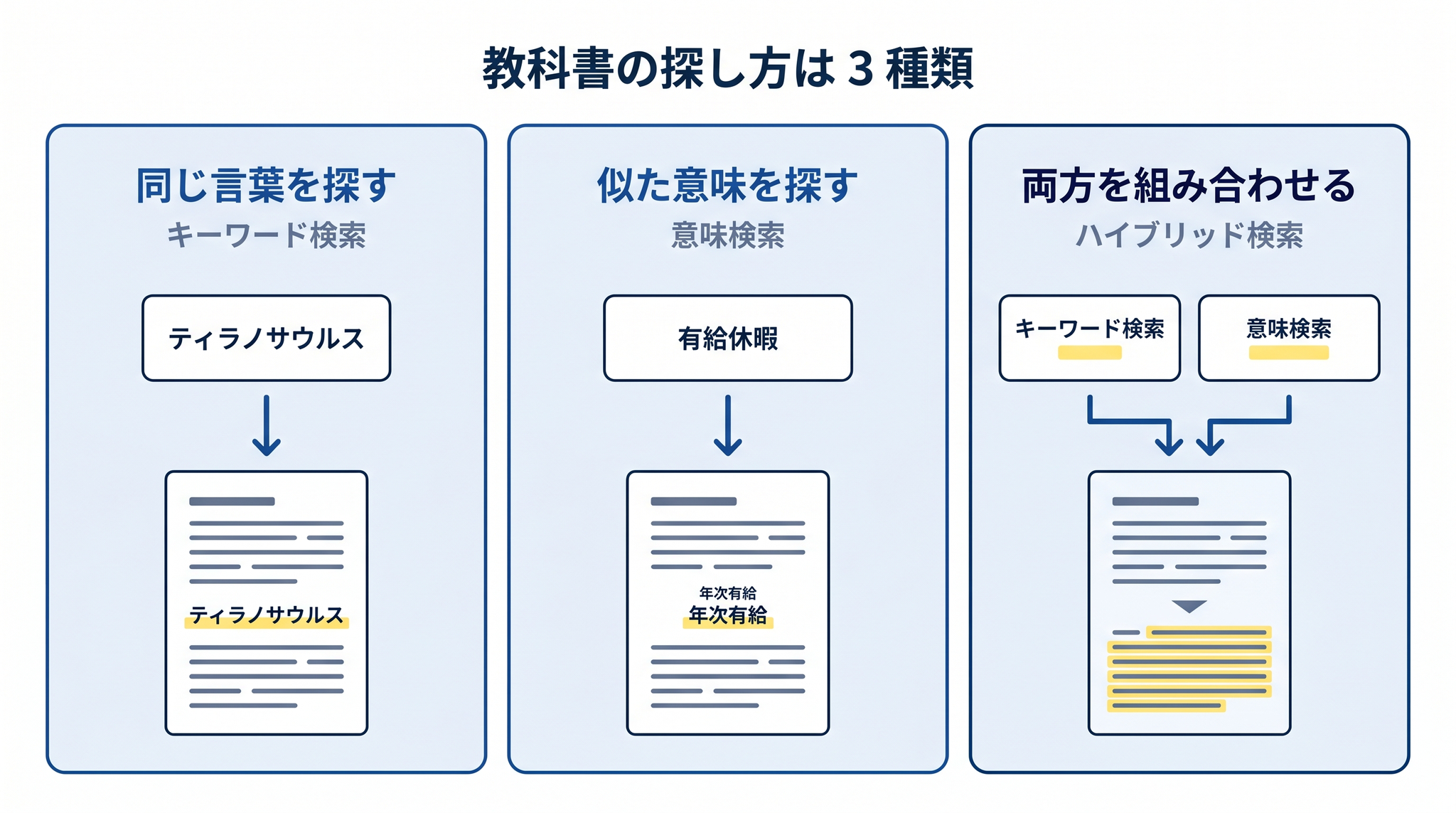
4-1. 同じ言葉を探す(キーワード検索)
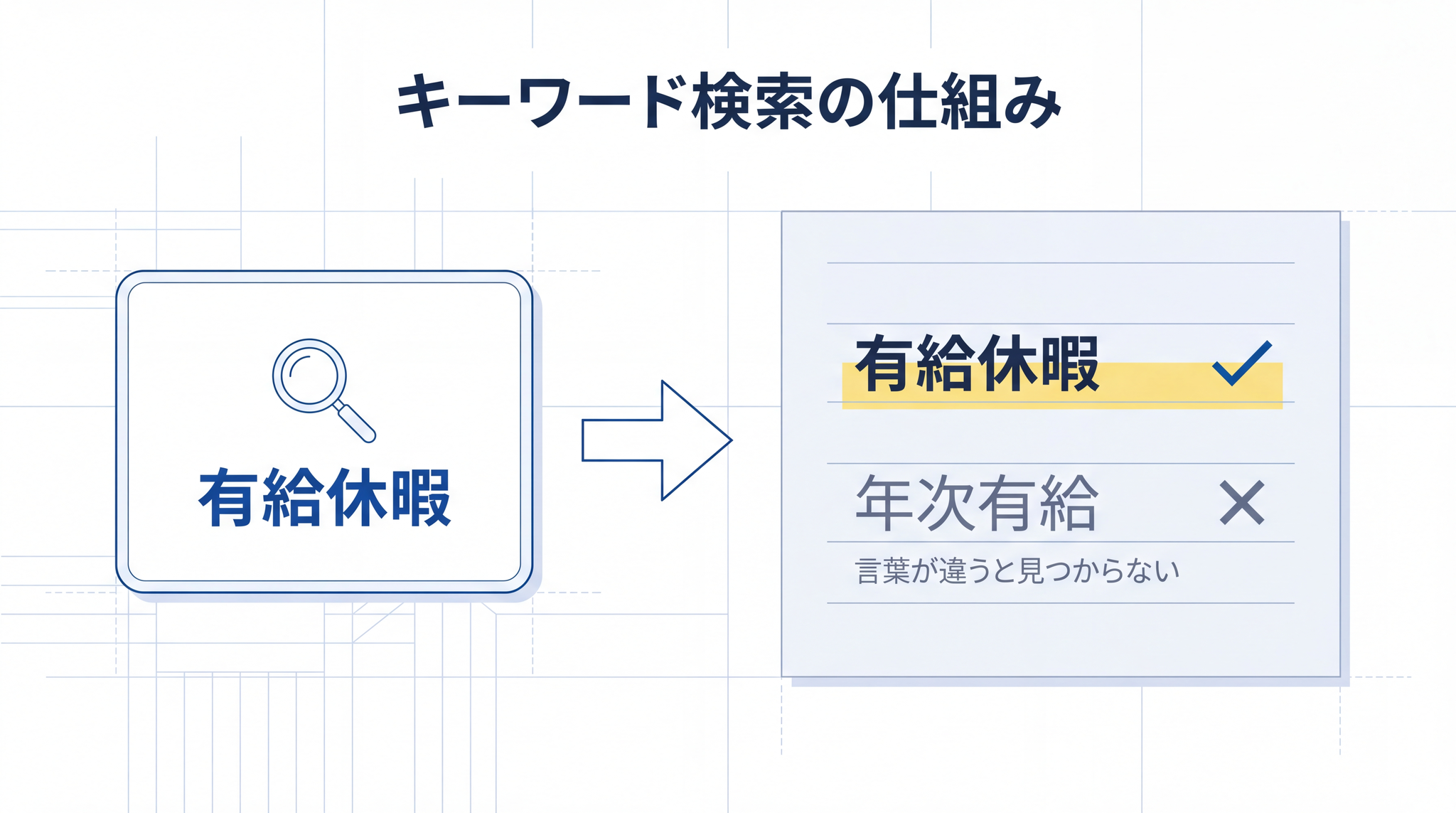
いちばん素朴なやり方です。質問に出てきた言葉と、同じ言葉が書いてある文書を探します。普段の検索エンジンに近い感覚です。
「ティラノサウルス」と検索すれば、ティラノサウルスと書いてある文書が見つかる。商品の型番、人名、エラーコードのような、一字一句が大事な情報には強いやり方です。
ただし、同じ意味でも言葉が違うと見つかりません。「有給休暇」を探したいのに、文書には「年次有給」としか書かれていなければ、ヒットしません。
4-2. 似た意味を探す(意味検索)
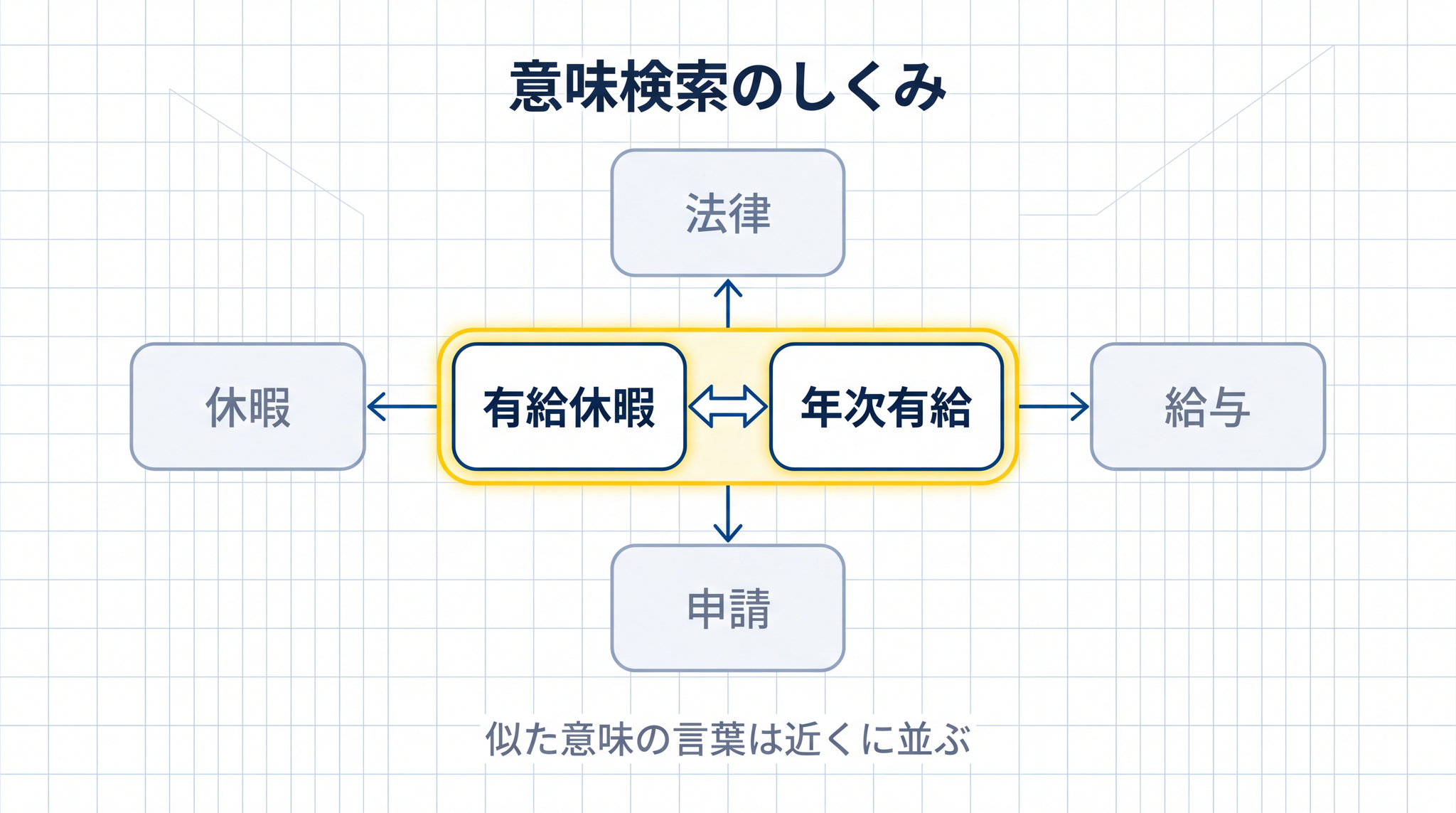
そこで登場したのが、意味の近さで探す方法です。文章を、AI の中で意味を表す数値の並び(ベクトル)に変換します。ベクトルとは数学用語ですが、ここでは「似た意味の言葉ほど近い数値になる仕組み」と理解するだけで十分です。「有給休暇」と「年次有給」のように、書き方は違っても意味が近いものは、数値の並びも近くなる ── そういう仕組みで探します。
意味検索 のおかげで、質問の言葉と文書の言葉がぴったり一致しなくても、内容が近いものを見つけてこられるようになりました。RAG が広まるうえで中心になった技術です。
4-3. 両方を組み合わせる(ハイブリッド検索)
実際の現場では、「同じ言葉を探す」と「似た意味を探す」を両方走らせて、結果を合わせるやり方が主流になっています。一字一句の正確さと、意味のしなやかさを、両立させる工夫です。これをハイブリッド検索と呼びます。
3 つの違いを 1 行ずつでまとめると、こうなります。
- 同じ言葉を探す ── 厳密な一致に強い、言い換えに弱い
- 似た意味を探す ── 言い換えに強い、固有名詞や型番に弱い
- 両方を組み合わせる ── どちらの強みも生きる、組み立ては複雑になる

ここで紹介した 3 つの探し方は、ツール側が自動でやってくれます。ユーザーが選ぶ必要はありません。
5. 身近な道具は “教科書を渡す” 仕組み
ChatGPT のファイル添付、NotebookLM、Claude Projects、ChatGPT のカスタム GPT ── これらは見た目もメニューも違います。内側の動きも、すべてが同じというわけではありません。ただ、共通して理解しておきたい性質があります。
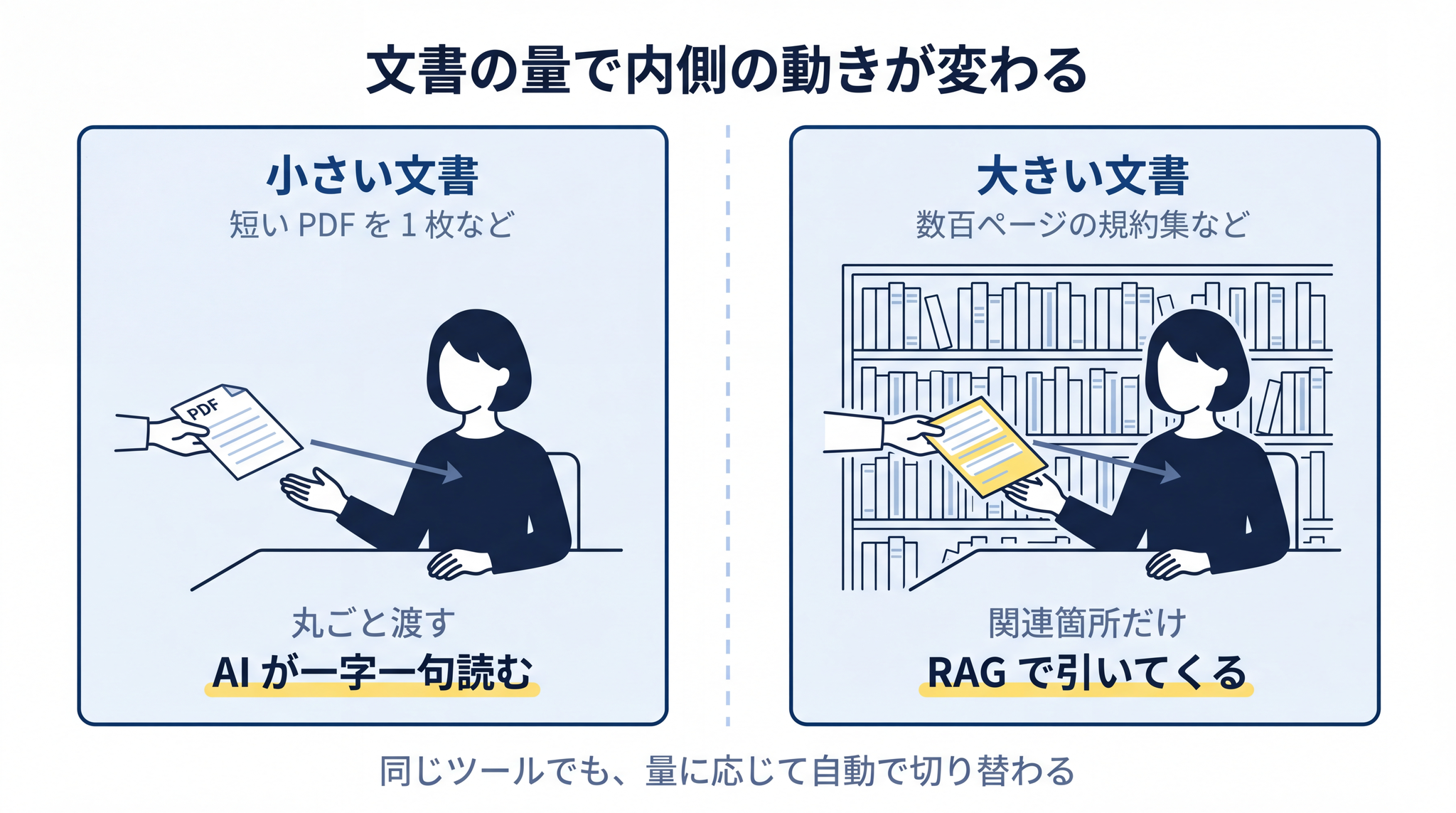
渡された文書を、AI が一字一句すべて記憶して読んでいるわけではない。質問に関係する箇所を引いてきて、その箇所を読みながら答えている。
多くの方が「PDF を添付したら AI が全部読んでくれている」と思いがちです。ところが実際には、ファイルのサイズや経路によって内側の動きが変わります。
短い文書を 1 枚だけ渡した場合、AI はそのままコンテキストに丸ごと読み込めます。RAG ではなく、単純に「文書をそのままコピーして読む」状態です。ファイルが大きくなったり、複数のファイルを束ねて使ったりすると、AI は関連する箇所だけを引いてくるモードに自動で切り替わります。
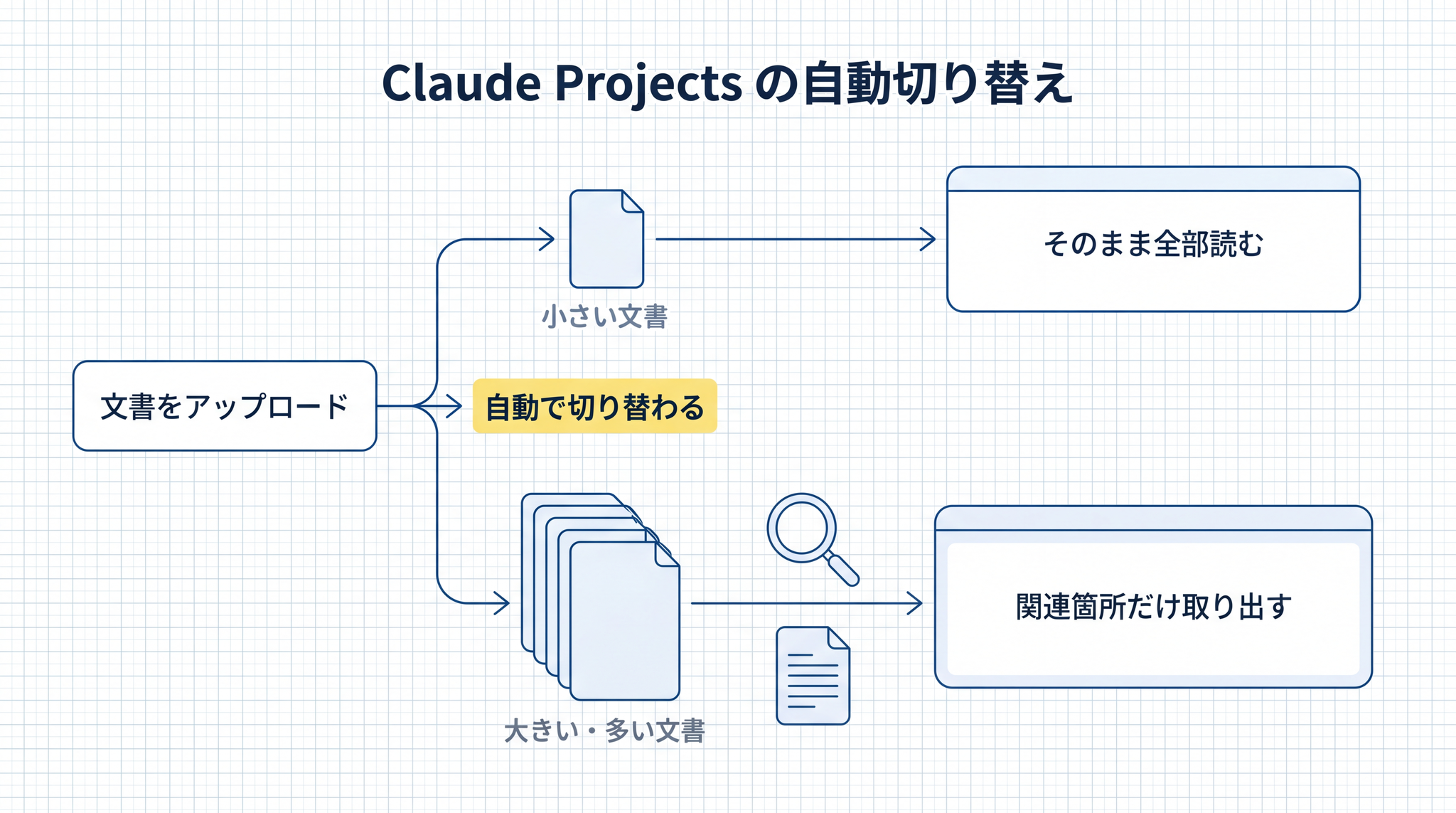
5-1. Claude Projects(Anthropic)
Anthropic は公式サポートページ3 で、文書の量が一定を超えると全部を一度に読み込むのではなく、必要な箇所だけを探して取ってくるモードに自動で切り替わると明記しています。容量を最大 10 倍に拡張しながら、質問への回答に必要な情報だけを取り出す、と書かれています。
5-2. NotebookLM(Google)
Google は NotebookLM のヘルプ4 で、複数の資料の中から質問に応じて関連情報を引いてきて、それをもとに回答を組み立てると説明しています。Anthropic と同じ性質です。

5-3. ChatGPT のファイル添付(OpenAI)
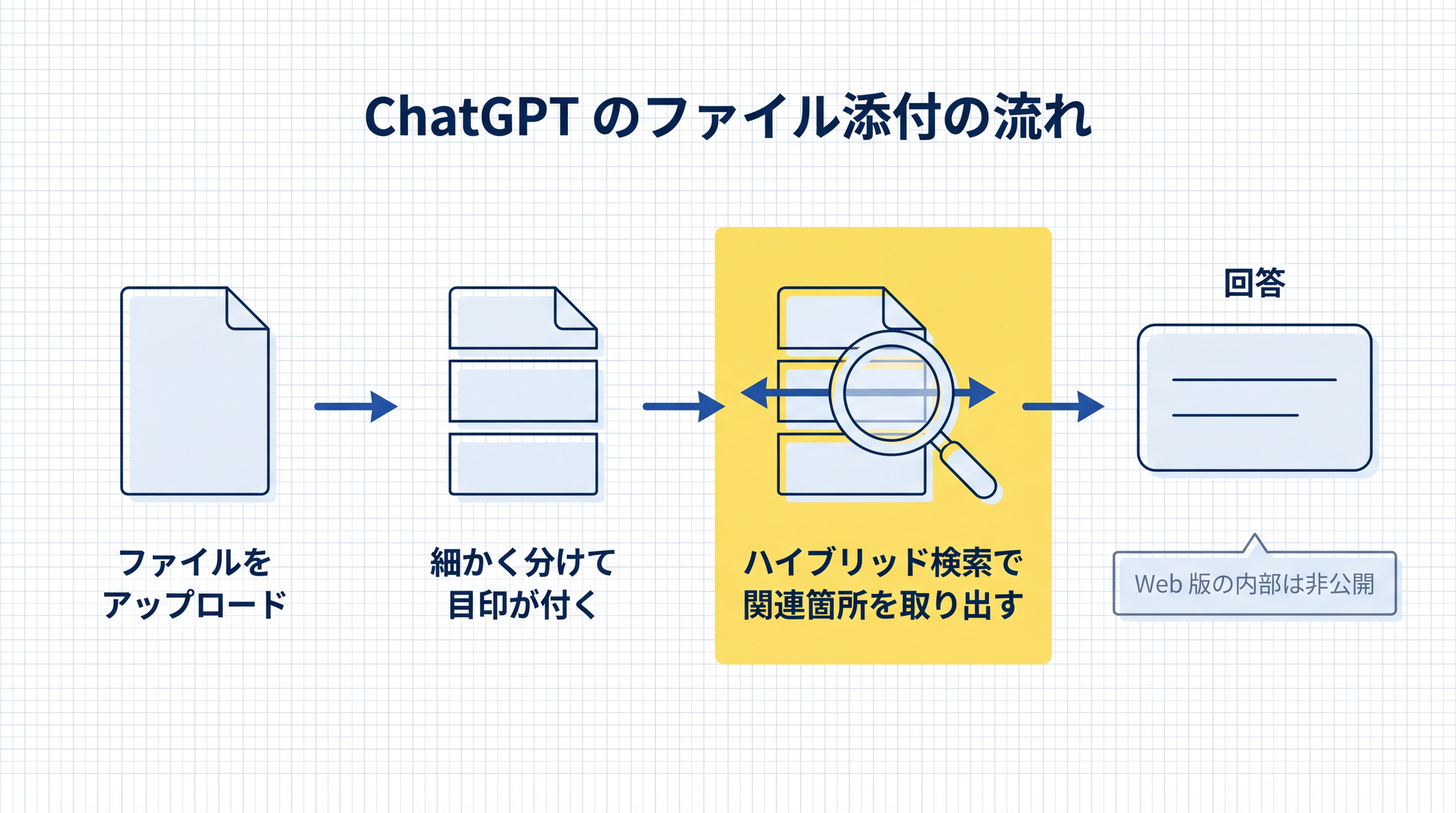
Web 版で使う分には、内部の細かい仕組みは気にせず使えます。ここからは技術背景に興味がある方向けの補足です。
OpenAI の API ドキュメント(開発者向けの技術資料)5 では、ファイルを渡すと自動で細かく分けて目印が付けられ、ハイブリッド検索で関連箇所が取り出されると明記されています。これは API の File Search での挙動です。Web 版でも同じ系統の仕組みが動いていると見られていますが、詳細は公式には出ていません。
5-4. 共通する性質
- 文書が小さい ── そのまま AI に丸ごと渡せる(コンテキストに収まる)
- 文書が大きい ── 自動で細切れに分けて目印が付けられ、関連箇所だけが引かれる(RAG)
注意:細かい挙動(どの時点で切り替わるか、どのくらいの精度で引いてくるか)はメーカーごとに違いますし、半年単位で更新されます。ここでは「仲間として括れる」ところまでを書きます。個別の道具を本格的に使いこなす話は、別記事に分けて扱う予定です。
迷ったらまず NotebookLM で試してみてください。次の章で 3 つの選び方を整理します。
6. 教科書を渡しても、読み違えは起きる

教科書を渡せば AI は嘘をつかなくなる ── そう期待したくなる場面です。ところが、そうはなりません。教科書を渡しても、 読み違いは起きます 。
これを示した有名な研究があります。スタンフォード大学の研究グループが、米国の法律業界向けに「嘘をつかない」を売りにした AI 製品 2 本を調査した報告6 です。内部では RAG を使っている製品です。
調査の結果、1 製品では 6 回に 1 回以上、もう 1 製品では 3 回に 1 回程度のペースで、ハルシネーション(もっともらしい嘘)が出ました。教科書を渡してあるはずなのに、です。
身近な事件もあります。航空会社のチャットボットが、自社サイトの公式情報を読めるようになっていたにもかかわらず、存在しない「お葬式の参列で乗る飛行機を、後から割引できる制度」を答えてしまった。後にカナダの裁判所が航空会社側に賠償を命じた事件です。
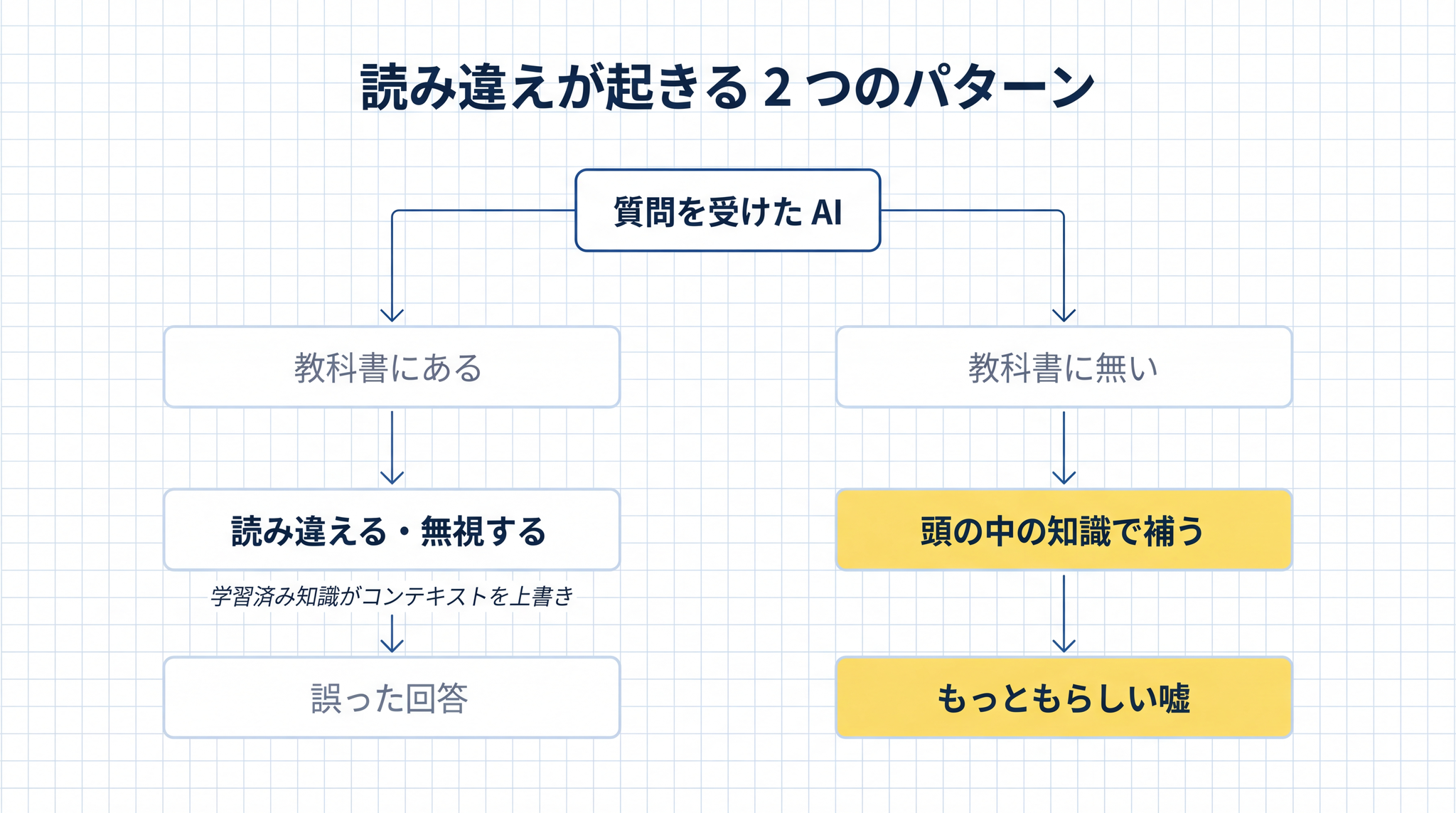
なぜ、こういうことが起きるのでしょうか。読み違いには、大きく 2 つのパターンがあります。
6-1. 教科書にあるのに、読み違える
引いてきた箇所を AI が無視する、もしくは解釈を誤るパターンです。AI は学習で身につけた知識(§2 の「頭の中」)と、その場で渡された情報(「コンテキスト」)の両方を見て答えを組み立てます。両者が食い違うと、頭の中のほうを優先してしまうことがあります。
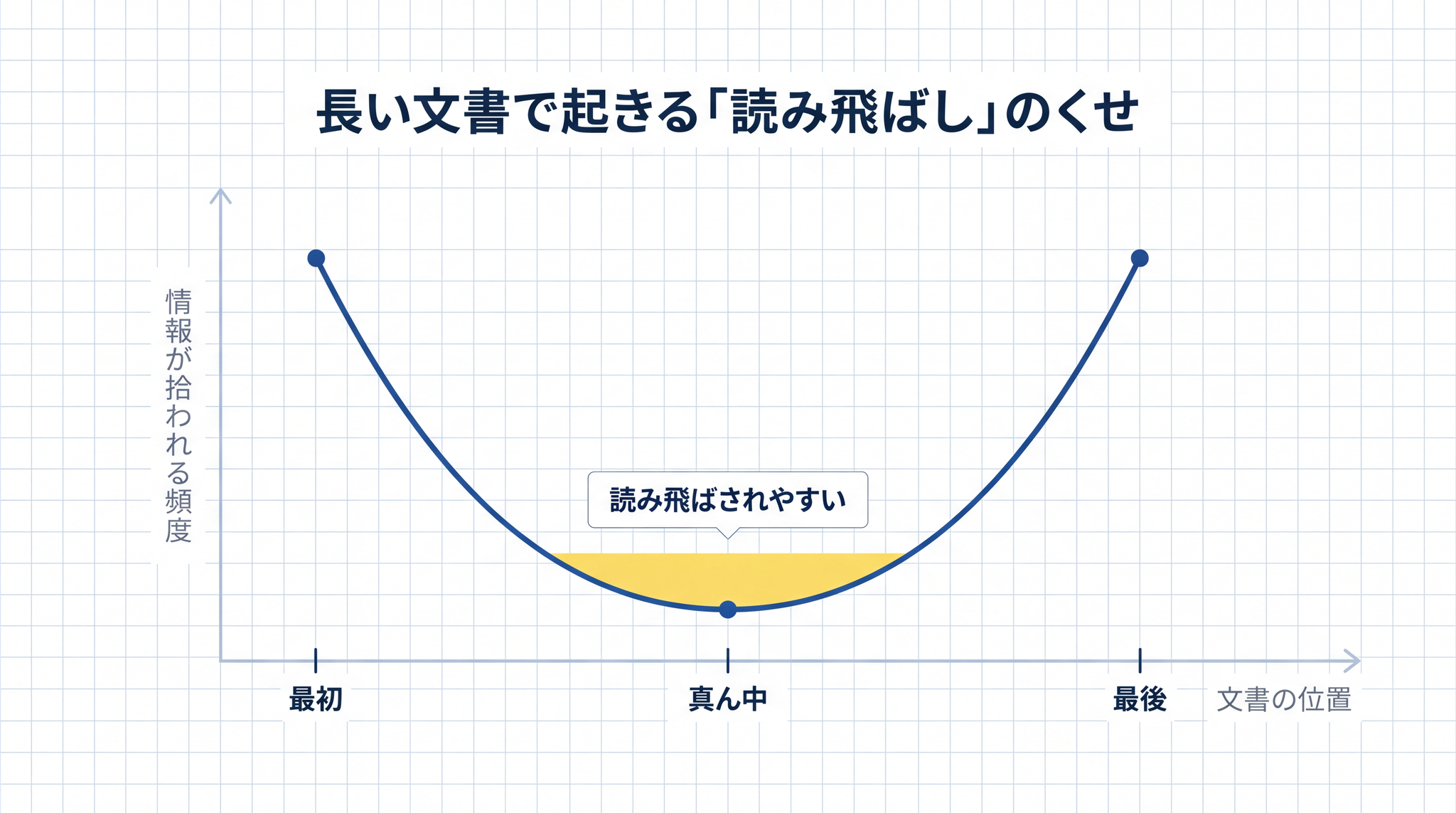
スタンフォード大学などの研究チームが発表した報告7 もあります。長い文書を渡したとき、真ん中のページの情報を AI が読み飛ばす傾向があるという内容です。文書の最初と最後はよく拾われ、真ん中は見落とされる ── U の字を描くようなクセが、複数の AI モデルで確かめられています。
実際の研修でも、同じ壁にぶつかる場面があります。
たとえば、社内マニュアルの PDF を AI に渡して質問させると、ページをまたいで印刷された表を正しく読み取れないことがあります。1 ページ目に項目名、2 ページ目に数値が並ぶ表は、PDF のページ区切りで分割されると、項目と数値の対応関係が崩れたまま取り込まれるからです。
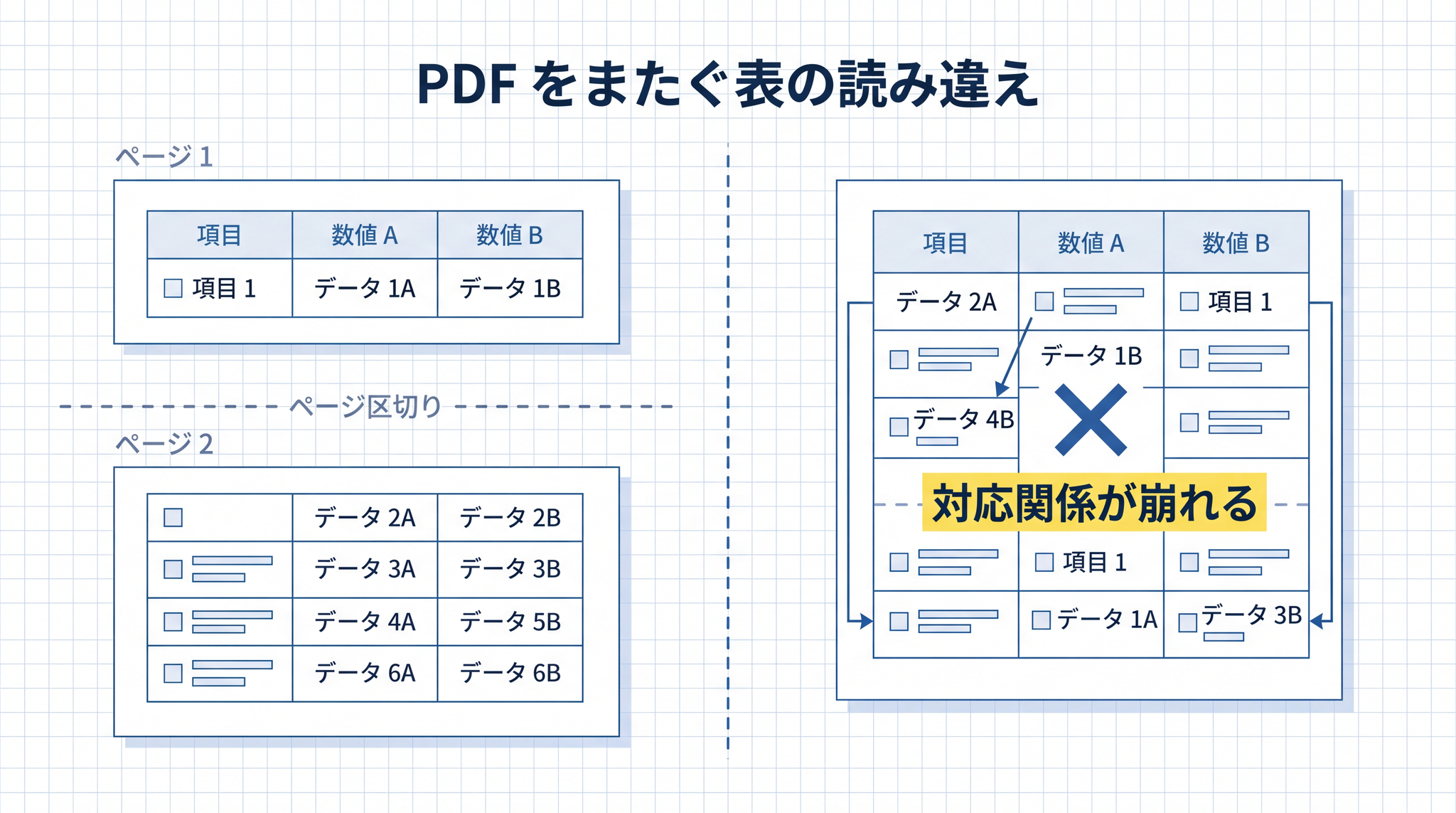
また、操作手順を画像で示したマニュアルは、画像部分を RAG が読み取れません。「この手順を教えて」と聞いても、画像の中の情報は答えに入ってこない。教科書を渡したはずなのに、肝心なところが抜けてしまう ── 読み違えの典型です。
6-2. 教科書に無いから、補ってしまう
引かれてきた箇所に答えが書かれていなかったとき、AI が「分かりません」と返さず、頭の中を使ってそれらしく補ってしまうパターンです。航空会社の「お葬式の割引制度」がこの例です。
引かれた箇所には、答えが薄かった(あるいは無かった)。けれど AI は、学習で身につけた一般的な航空業界の知識を使って、もっともらしい話を作ってしまった。
6-3. だから “確かめる” は人間の役割
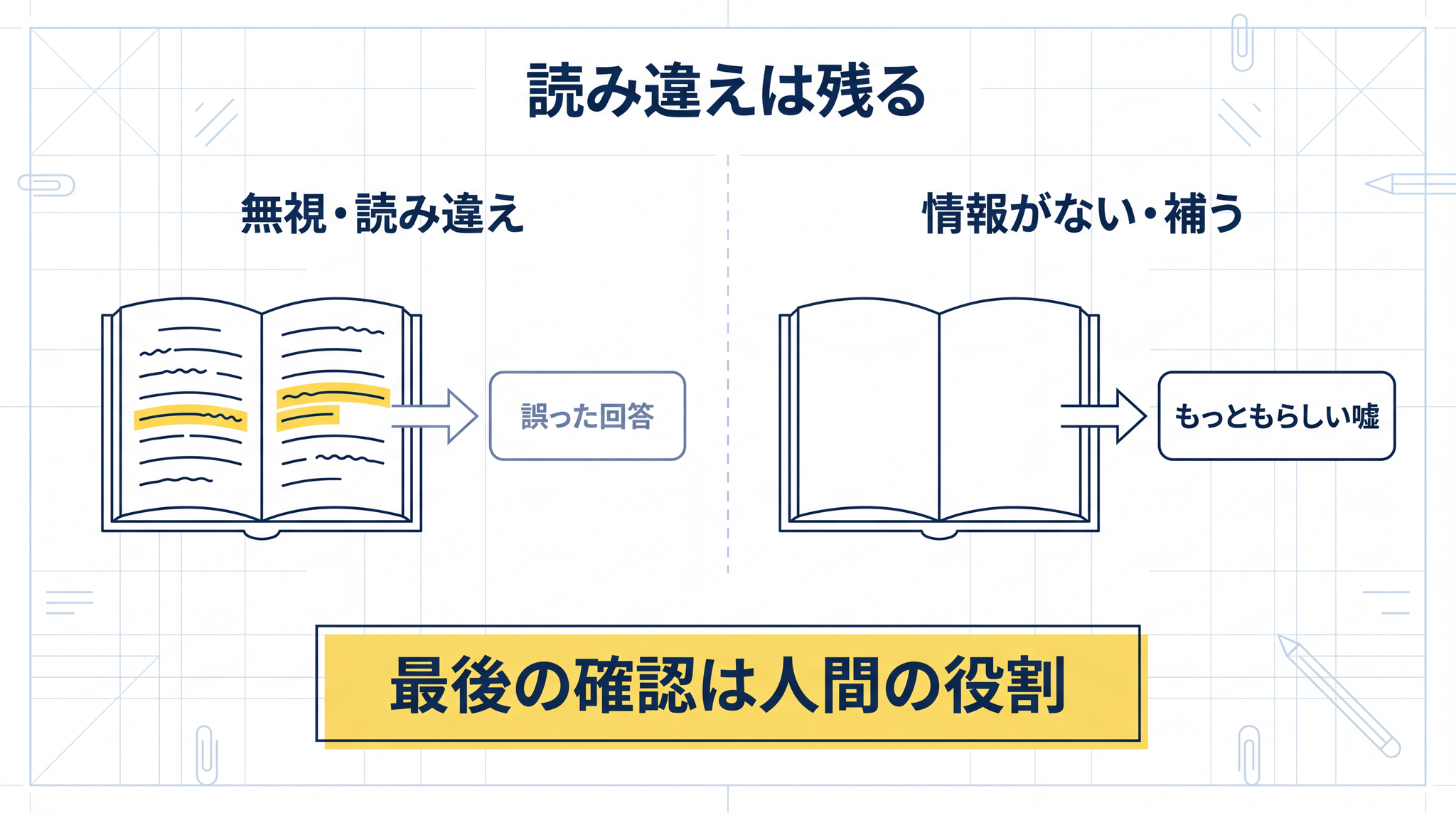
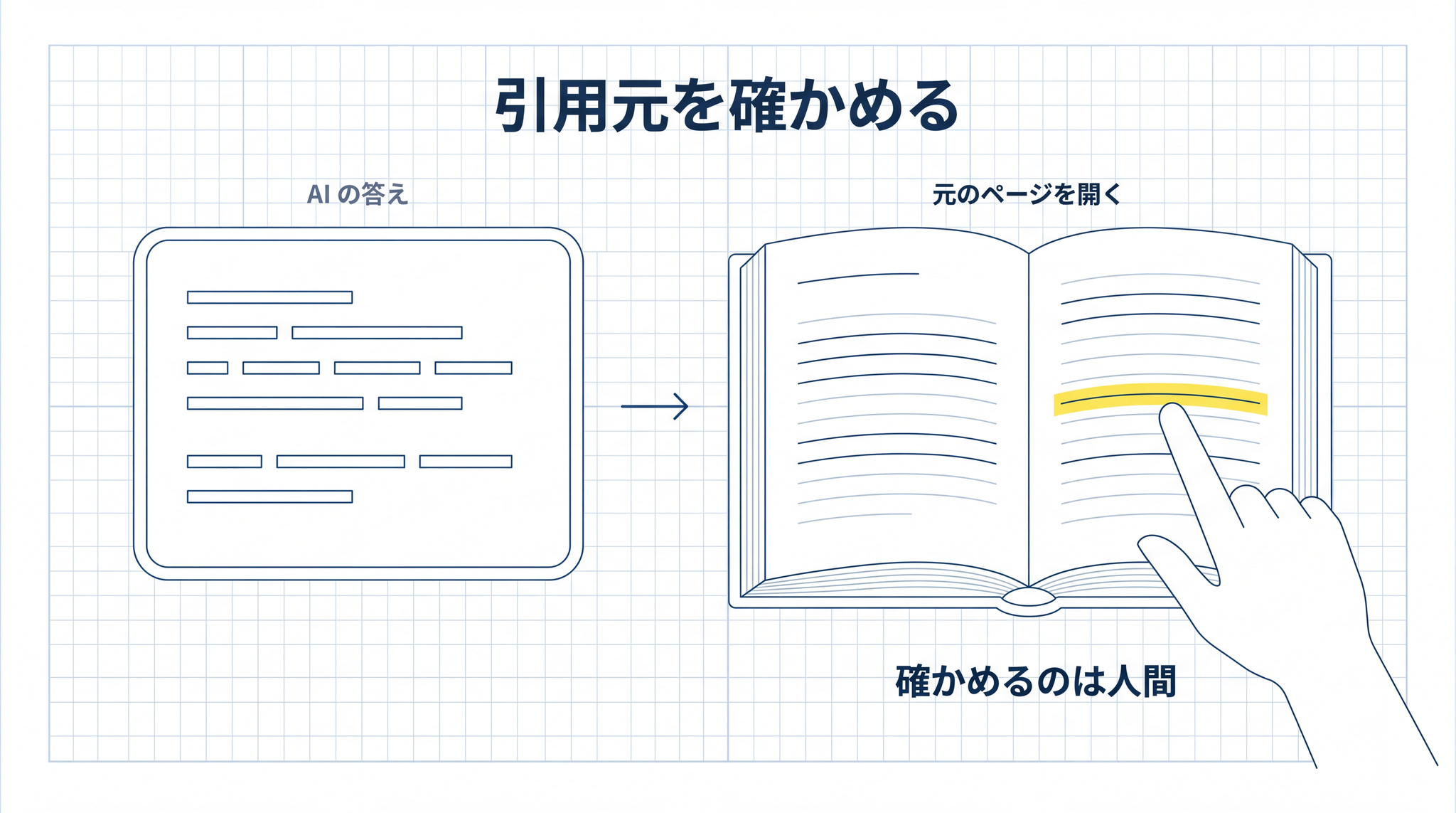
RAG は、嘘の量を 減らす 仕組みです。 消す 仕組みではありません。最後に “本当か” を確かめるのは 人間 です。AI が「この PDF の 3 ページに書かれています」と引用元を示してくれる場合は、その 3 ページを自分で開いて確かめる。それだけで、§6 で挙げた読み違いの大半は捕まえられます。
ハルシネーション(AI が “自信満々で嘘をつく” 現象)の根っこには、ここでは深入りしません。詳しくは別記事「ハルシネーション ── AI に『本当』の感覚が無い、という話」で扱います。
7. 学習・RAG・資料添付 ── 場面ごとの使い分け
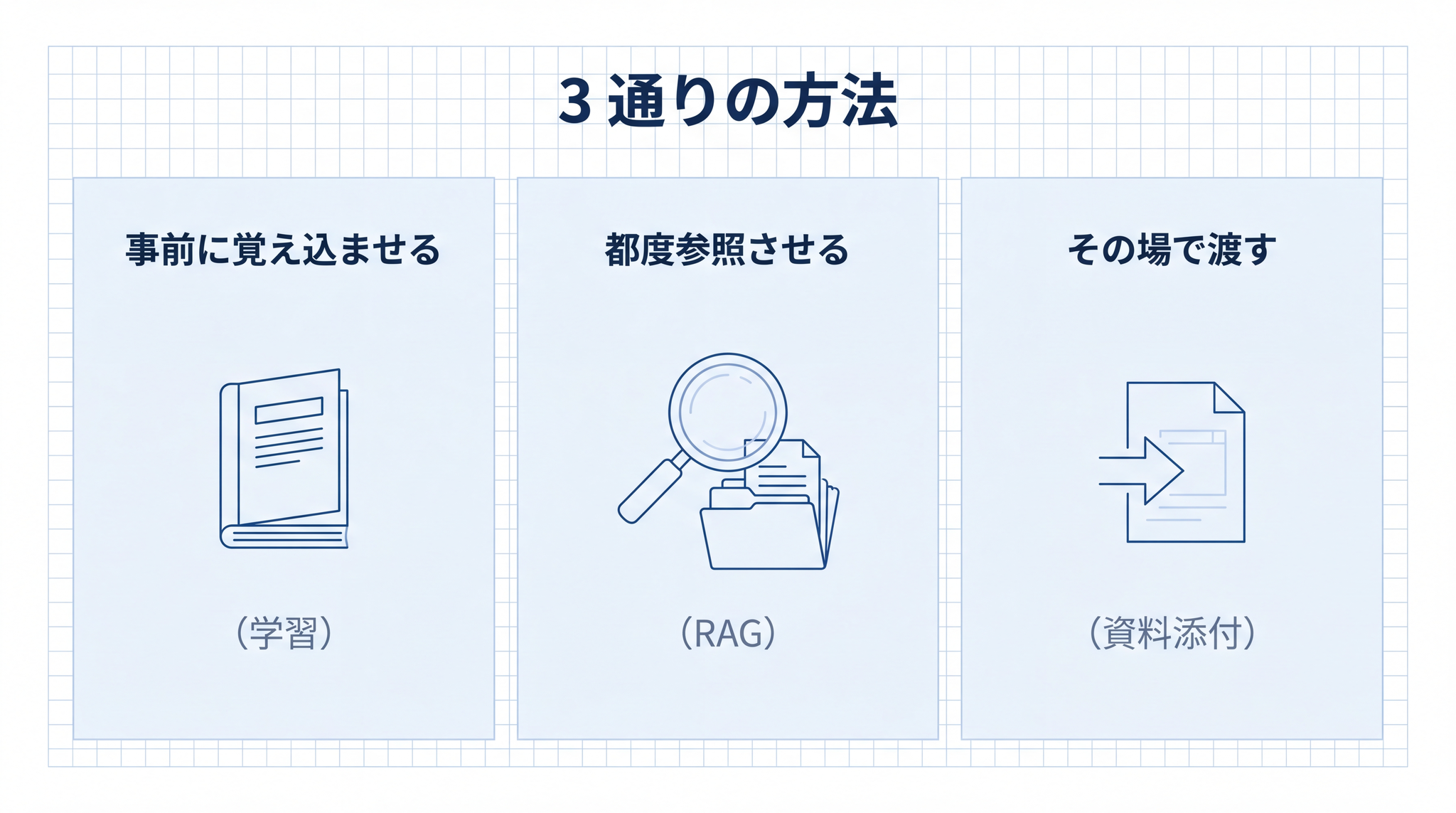
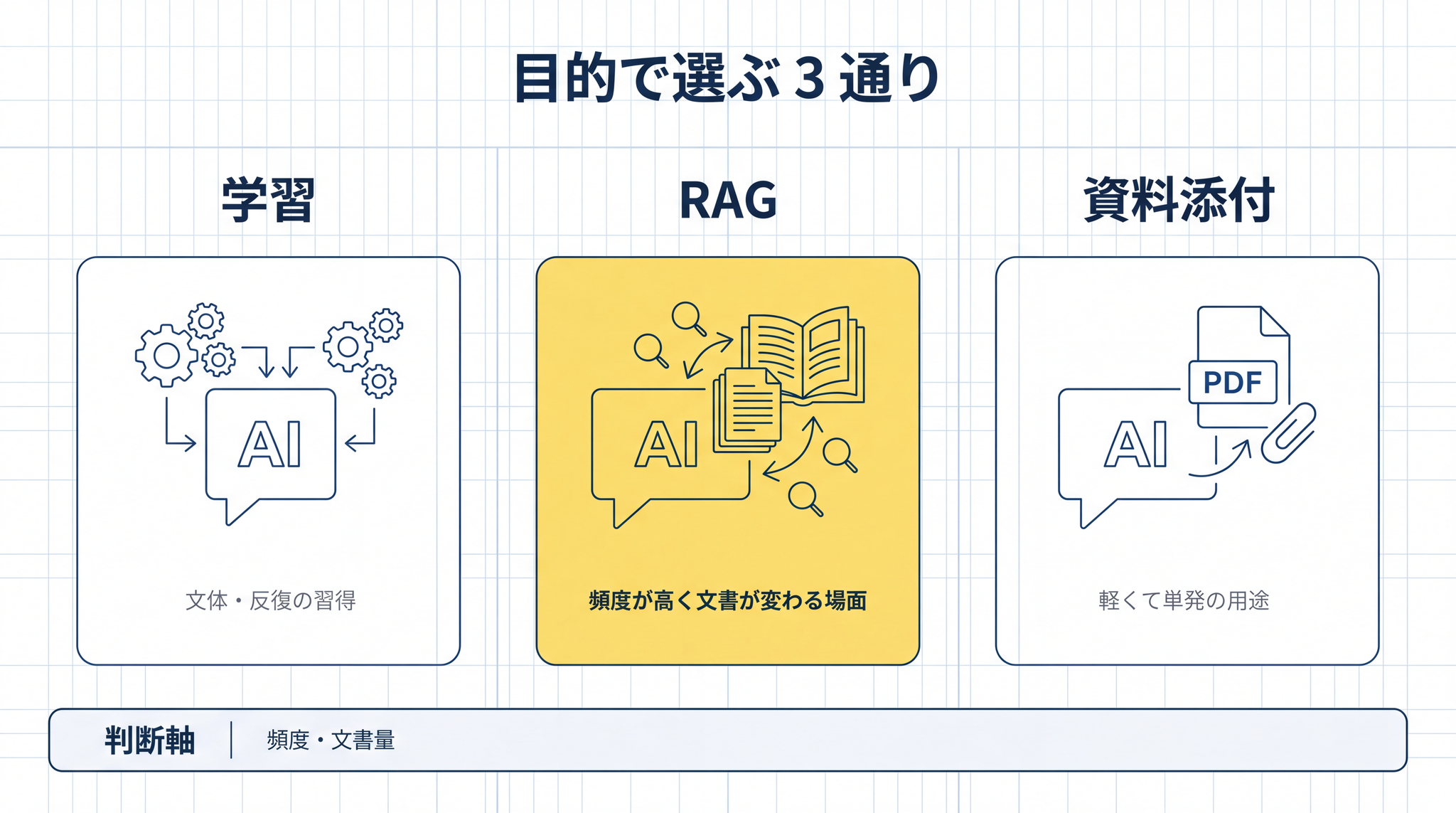
AI に手元の文書を答えに使わせる方法は 3 通りあります。
- 学習(ファインチューニング)── 文書を AI の頭の中に書き込む
- RAG(教科書を引く)── 質問のたびに関連する箇所だけ引いてくる
- 資料添付(PDF を貼る・コピペで渡す)── 質問のときに全部その場で渡す
3 つの違いを、新人社員のたとえで並べてみます。社員 1 人に「この組織のことに詳しくなって、相手に答えてほしい」とお願いする 3 つのやり方です。使い分けの目安を先に示します。
頻度が低くて軽いなら資料添付、頻度が高くて文書が変わるなら RAG、文体や同じ仕事の反復を刻みたいなら学習。
7-1. 学習(ファインチューニング)── 研修で覚えさせる
新人社員に業務マニュアルを丸ごと覚えさせる研修を受けさせるイメージ。研修が終われば、社員は毎回マニュアルを開かなくても、聞かれたことに即答できます。
ただし、研修にはコストと時間がかかります。マニュアルが改訂されるたびに再研修も必要です。社内文書のように頻繁に変わる情報を扱うのには向きません。
逆に向くのは、AI に特有の文体や口調を身につけさせたい、同じような仕事を、たくさん、すばやく回したい場面です。一度刻んでしまえば、毎回背景情報を渡し直さなくていい ── それが学習の最大の強みです。

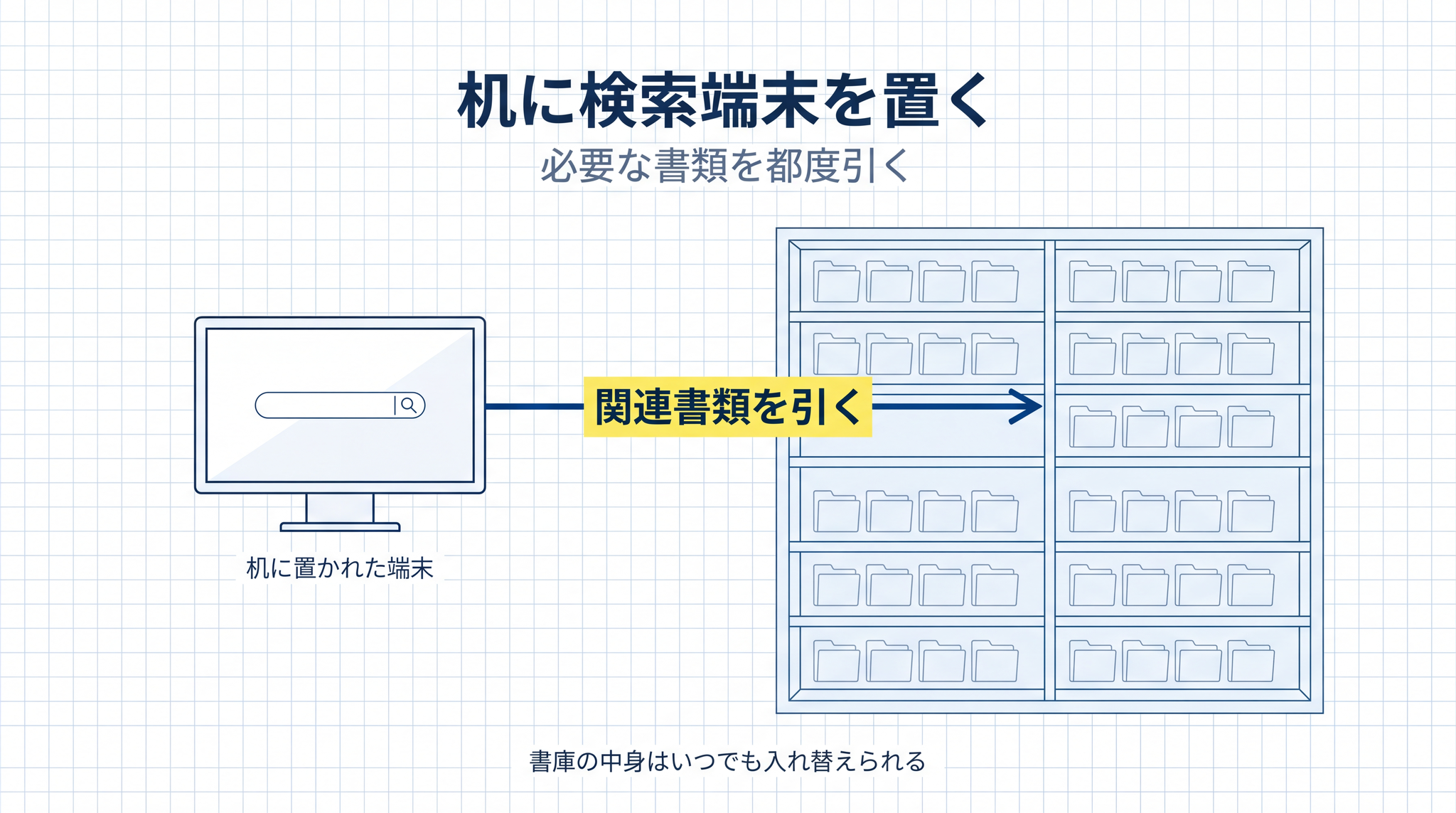
7-2. RAG(教科書を引く)── 机に検索端末を置く
新人社員の机に書庫を調べる端末を置くイメージ。質問が来たら端末で関連書類を引いて、それを見ながら答える。
書庫の中身はいつでも入れ替えられます。新しい議事録が出たら足すだけ。研修をやり直す必要はありません。書類の量が増えても、検索端末で関連箇所だけ呼び出せるので、社員の頭はパンクしません。
向くのは、取扱説明書を何度も使う、数百ページの規約集を扱う、頻繁に更新される情報を答えに反映したい、機密情報を扱うので必要な箇所だけ送りたい ── このあたりです。
7-3. 資料添付(コピペ・PDF を貼る)── その場で書類を手渡す
質問のときに必要な書類をその場で社員に手渡すイメージ。短い書類なら、これがいちばん早くて手軽です。
ただし、書類が分厚すぎるとコンテキストウィンドウに入りきりません。数十冊を毎回手渡すのも、現実には無理があります。毎回違うファイルを貼り直す手間もかかります。
向くのは、1 ページの PDF を一度だけ要約してもらう、短いメールの下書きをチェックしてもらう、Web ページの内容を貼って質問する ── 単発・少量の用途です。

7-4. 一覧で見比べる
◎ が一番向いている、△ が条件付き、× が向かない、です。
| 場面 | 学習 | RAG | 資料添付 |
|---|---|---|---|
| 数ページの PDF を 1 回だけ読ませる | × | △ | ◎ |
| 取扱説明書 1 冊を、毎日のように使う | × | ◎ | △ |
| 数百ページの規約集・数十ファイルの束 | × | ◎ | × |
| 頻繁に更新される情報(議事録・在庫・ニュース) | × | ◎ | △ |
| AI に特有の文体・口調を身につけさせる | ◎ | × | × |
| 同じような仕事を、たくさん、すばやく処理する | ◎ | △ | × |
| 機密情報を扱う(必要な箇所だけ送りたい) | △ | ◎ | △ |
8. 次にやってみると良いこと

以上の話を、手元で 1 つだけ試して持ち帰ってください。それだけで、この記事は仕事をしたことになります。
8-1. NotebookLM に PDF を 1 つ読ませてみる
入り口として最もやさしいのは、Google の NotebookLM8 です。Google アカウントがあれば無料で使えます。
- 自宅の電子レンジの取扱説明書 PDF を 1 枚アップロードする
- 「冷凍ご飯をあたためる手順を教えて」と聞いてみる
- 答えにどのページから引いたかが小さく表示されるのを確認する
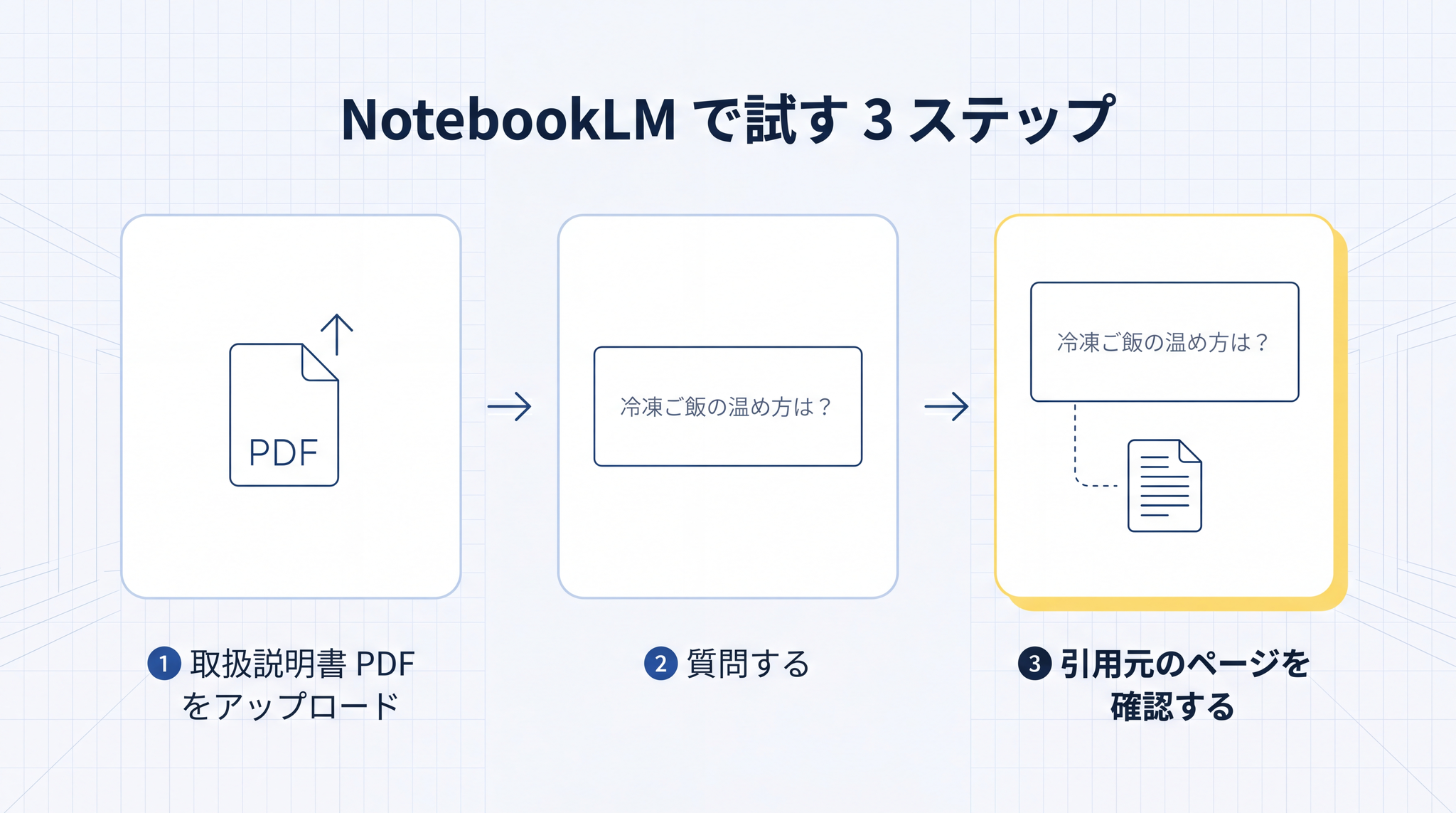
引用元が表示されることが、§6 の「確かめるのは人間」を物理的に支えてくれます。
8-2. ChatGPT や Claude のファイル添付で試す
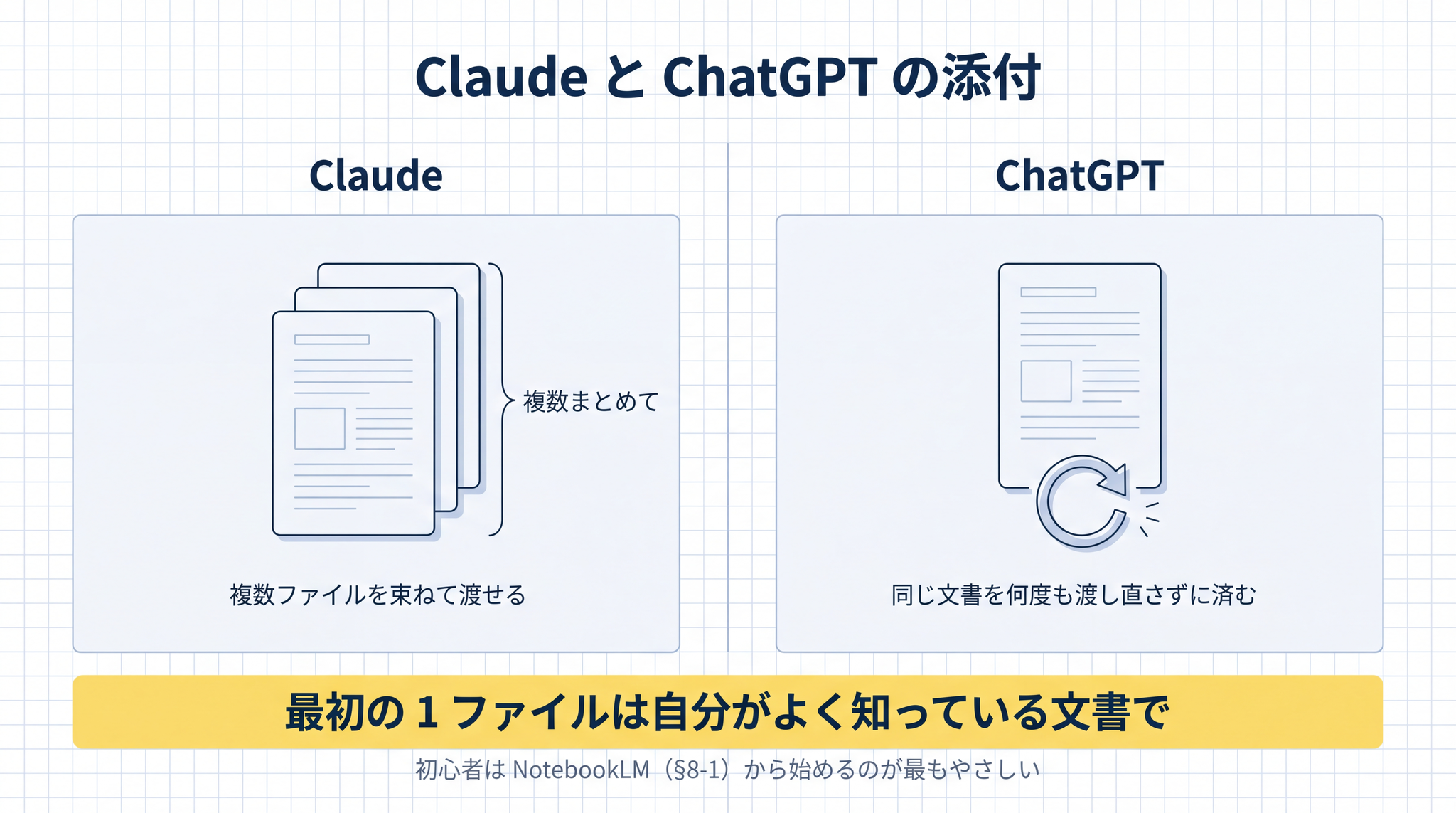
すでに ChatGPT や Claude を契約している方向けです。まだどちらも使っていないなら、前の 8-1(NotebookLM)から始めるのが最もやさしい道です。
ChatGPT や Claude のファイル添付の機能で同じことができます。Claude を使うなら、複数ファイルを束ねて読ませる機能があります。ChatGPT にも、同じ文書を何度も渡し直さずに済む機能があります。
最初の 1 ファイルは、自分が中身をよく知っている文書にしてください。AI が読み違えたとき、自分で気づけるためです。家族のレシピ集、自治会の規約、過去の議事録、学校のレポート PDF ── 何でも構いません。
8-3. 引用元のページを必ず開く
§6 で見たとおり、AI は教科書を渡しても読み違えます。だから、AI が示した答えのうち、大事な箇所は必ず 元のページを開いて確かめる 。これだけは習慣にしてください。
教科書を渡す仕組みを使う、と「教科書を渡しさえすれば AI は嘘をつかない」と思い込む、は別物です。前者は便利な道具、後者は危険な勘違い ── その違いを、自分の言葉で言えるはずです。
今日まず NotebookLM を開いて、自分がよく知っている文書を 1 つアップロードしてみてください。引用元が表示される画面を自分の目で見ると、この記事で書いたことがひとつにつながります。
関連記事
- LLM の仕組み ── 同じ問いに違う答えが返ってくる、その理由:§2 の「頭の中」がどう作られているかを、もう一段深く
- AI でできること、できないこと ── 仕組みで整理する「地図」:本記事の前提になる、半年後も古びない判断軸
- 『欲しい答え』が返ってくる聞き方 ── プロンプト 5 つの型:§1 で切り分けた “聞き方の問題” 側
- コンビニ・職人・科学者 ── ChatGPT・Claude・Gemini はなぜ違うのか:§5 で並べた道具を、目指す方向から整理
- AI・機械学習・深層学習・生成 AI ── 入れ子で見ると、ニュースが読める:用語の関係を 1 枚で整理
- ハルシネーション ── AI に『本当』の感覚が無い、という話:§6 の根っこを深掘り
出典・参考文献
-
Lewis et al. 2020 | Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(arXiv:2005.11401) ↩
-
Anthropic | Retrieval-Augmented Generation (RAG) for Projects ↩
-
スタンフォード大学 | Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools ↩
-
Liu et al. 2023 | Lost in the Middle: How Language Models Use Long Contexts ↩